 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLifelong Learning Without a Task Oracle
Paper and Code
Nov 09, 2020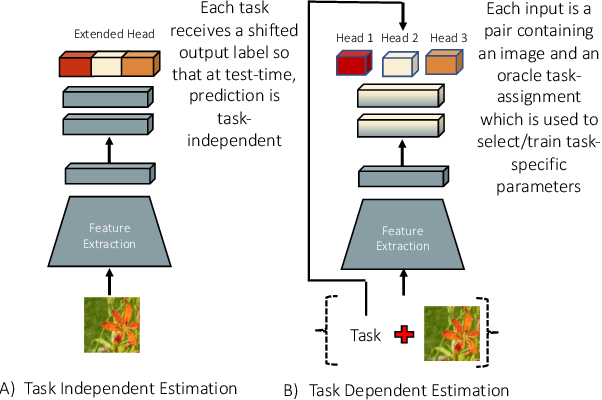
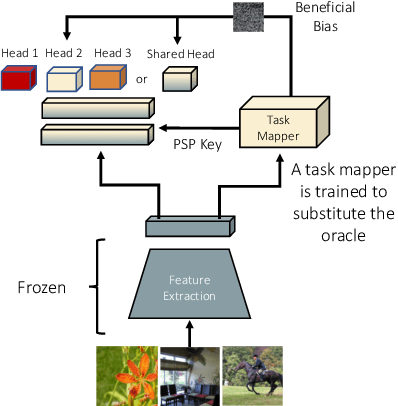
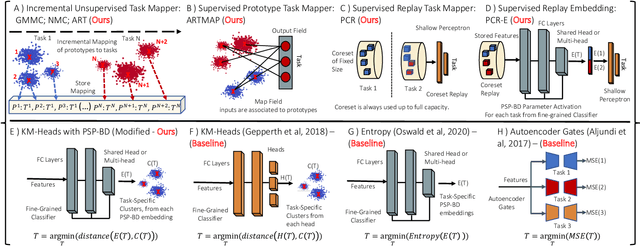
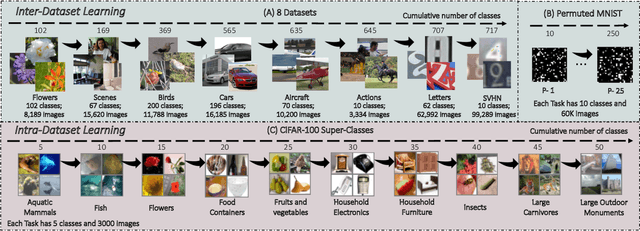
Supervised deep neural networks are known to undergo a sharp decline in the accuracy of older tasks when new tasks are learned, termed "catastrophic forgetting". Many state-of-the-art solutions to continual learning rely on biasing and/or partitioning a model to accommodate successive tasks incrementally. However, these methods largely depend on the availability of a task-oracle to confer task identities to each test sample, without which the models are entirely unable to perform. To address this shortcoming, we propose and compare several candidate task-assigning mappers which require very little memory overhead: (1) Incremental unsupervised prototype assignment using either nearest means, Gaussian Mixture Models or fuzzy ART backbones; (2) Supervised incremental prototype assignment with fast fuzzy ARTMAP; (3) Shallow perceptron trained via a dynamic coreset. Our proposed model variants are trained either from pre-trained feature extractors or task-dependent feature embeddings of the main classifier network. We apply these pipeline variants to continual learning benchmarks, comprised of either sequences of several datasets or within one single dataset. Overall, these methods, despite their simplicity and compactness, perform very close to a ground truth oracle, especially in experiments of inter-dataset task assignment. Moreover, best-performing variants only impose an average cost of 1.7% parameter memory increase.