 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightweight Learner for Shared Knowledge Lifelong Learning
May 24, 2023
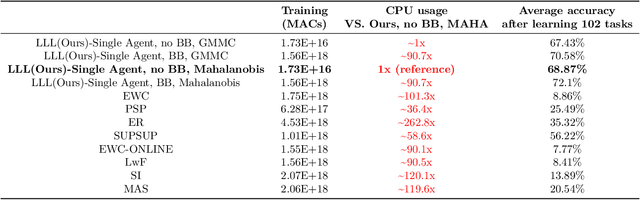

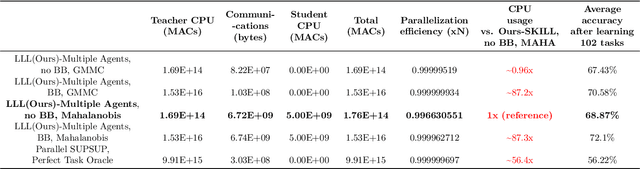
In Lifelong Learning (LL), agents continually learn as they encounter new conditions and tasks. Most current LL is limited to a single agent that learns tasks sequentially. Dedicated LL machinery is then deployed to mitigate the forgetting of old tasks as new tasks are learned. This is inherently slow. We propose a new Shared Knowledge Lifelong Learning (SKILL) challenge, which deploys a decentralized population of LL agents that each sequentially learn different tasks, with all agents operating independently and in parallel. After learning their respective tasks, agents share and consolidate their knowledge over a decentralized communication network, so that, in the end, all agents can master all tasks. We present one solution to SKILL which uses Lightweight Lifelong Learning (LLL) agents, where the goal is to facilitate efficient sharing by minimizing the fraction of the agent that is specialized for any given task. Each LLL agent thus consists of a common task-agnostic immutable part, where most parameters are, and individual task-specific modules that contain fewer parameters but are adapted to each task. Agents share their task-specific modules, plus summary information ("task anchors") representing their tasks in the common task-agnostic latent space of all agents. Receiving agents register each received task-specific module using the corresponding anchor. Thus, every agent improves its ability to solve new tasks each time new task-specific modules and anchors are received. On a new, very challenging SKILL-102 dataset with 102 image classification tasks (5,033 classes in total, 2,041,225 training, 243,464 validation, and 243,464 test images), we achieve much higher (and SOTA) accuracy over 8 LL baselines, while also achieving near perfect parallelization. Code and data can be found at https://github.com/gyhandy/Shared-Knowledge-Lifelong-Learning
What can we learn from misclassified ImageNet images?
Jan 20, 2022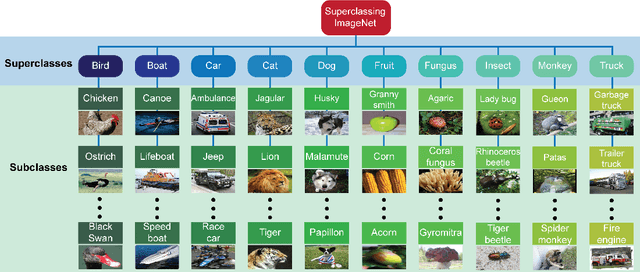
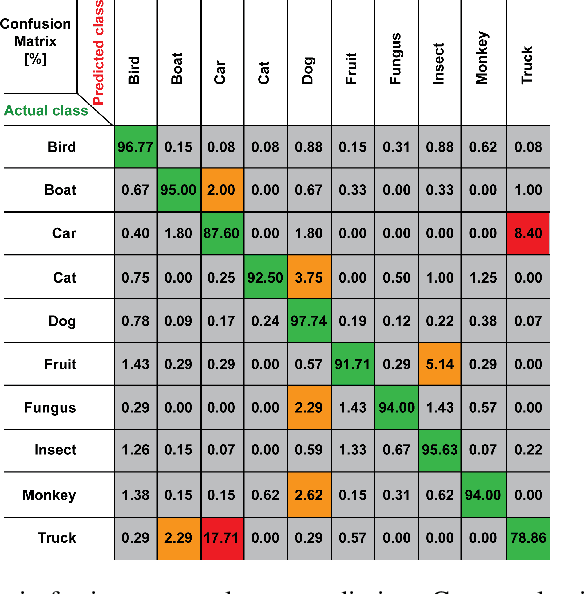
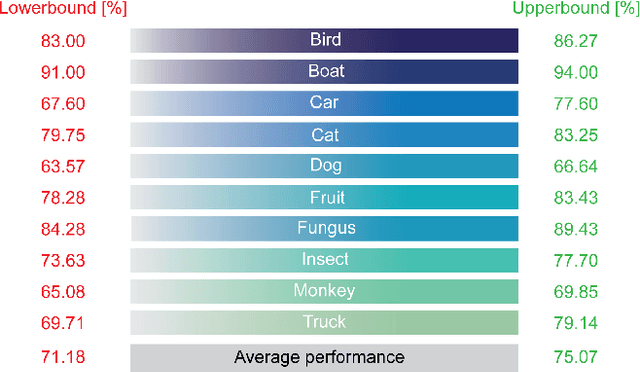
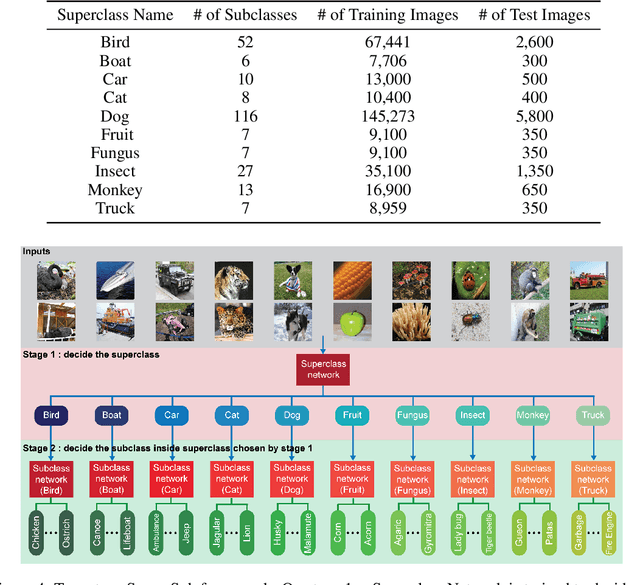
Understanding the patterns of misclassified ImageNet images is particularly important, as it could guide us to design deep neural networks (DNN) that generalize better. However, the richness of ImageNet imposes difficulties for researchers to visually find any useful patterns of misclassification. Here, to help find these patterns, we propose "Superclassing ImageNet dataset". It is a subset of ImageNet which consists of 10 superclasses, each containing 7-116 related subclasses (e.g., 52 bird types, 116 dog types). By training neural networks on this dataset, we found that: (i) Misclassifications are rarely across superclasses, but mainly among subclasses within a superclass. (ii) Ensemble networks trained each only on subclasses of a given superclass perform better than the same network trained on all subclasses of all superclasses. Hence, we propose a two-stage Super-Sub framework, and demonstrate that: (i) The framework improves overall classification performance by 3.3%, by first inferring a superclass using a generalist superclass-level network, and then using a specialized network for final subclass-level classification. (ii) Although the total parameter storage cost increases to a factor N+1 for N superclasses compared to using a single network, with finetuning, delta and quantization aware training techniques this can be reduced to 0.2N+1. Another advantage of this efficient implementation is that the memory cost on the GPU during inference is equivalent to using only one network. The reason is we initiate each subclass-level network through addition of small parameter variations (deltas) to the superclass-level network. (iii) Finally, our framework promises to be more scalable and generalizable than the common alternative of simply scaling up a vanilla network in size, since very large networks often suffer from overfitting and gradient vanishing.
Beneficial Perturbations Network for Defending Adversarial Examples
Sep 27, 2020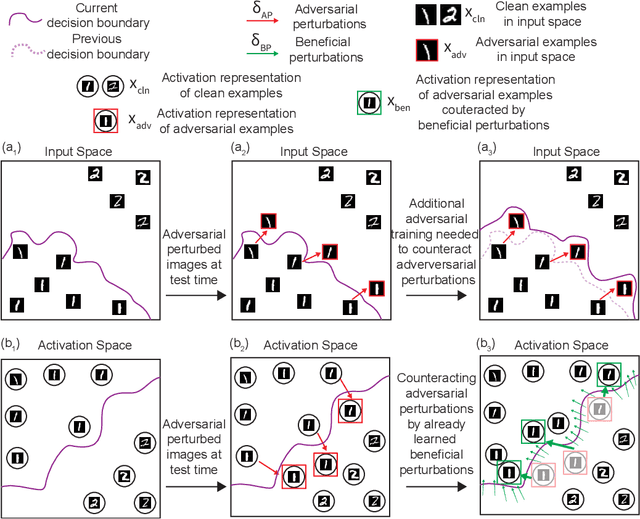
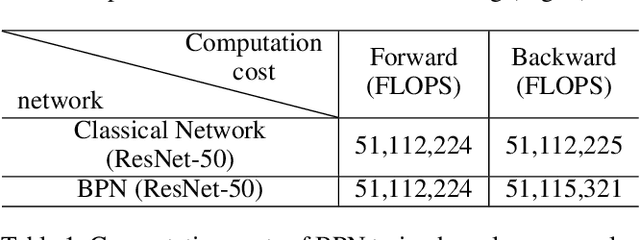
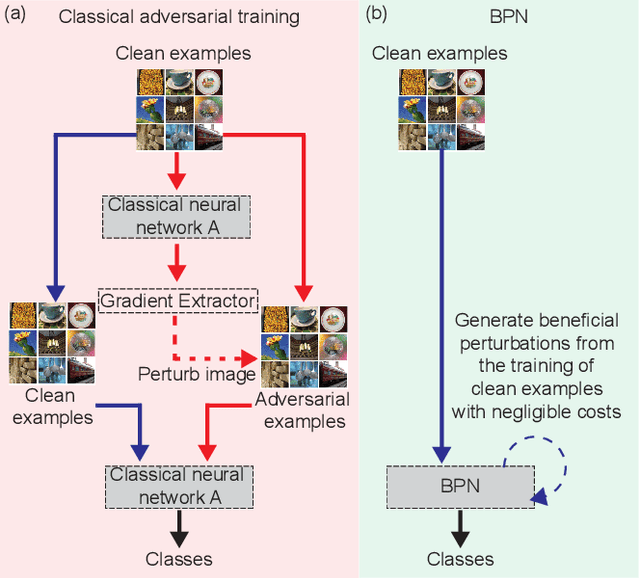
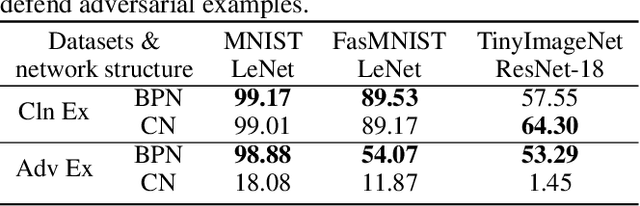
Adversarial training, in which a network is trained on both adversarial and clean examples, is one of the most trusted defense methods against adversarial attacks. However, there are three major practical difficulties in implementing and deploying this method - expensive in terms of running memory and computation costs; accuracy trade-off between clean and adversarial examples; cannot foresee all adversarial attacks at training time. Here, we present a new solution to ease these three difficulties - Beneficial perturbation Networks (BPN). BPN generates and leverages beneficial perturbations (somewhat opposite to well-known adversarial perturbations) as biases within the parameter space of the network, to neutralize the effects of adversarial perturbations on data samples. Thus, BPN can effectively defend against adversarial examples. Compared to adversarial training, we demonstrate that BPN can significantly reduce the required running memory and computation costs, by generating beneficial perturbations through recycling of the gradients computed from training on clean examples. In addition, BPN can alleviate the accuracy trade-off difficulty and the difficulty of foreseeing multiple attacks, by improving the generalization of the network, thanks to increased diversity of the training set achieved through neutralization between adversarial and beneficial perturbations.
Beneficial Perturbation Network for designing general adaptive artificial intelligence systems
Sep 27, 2020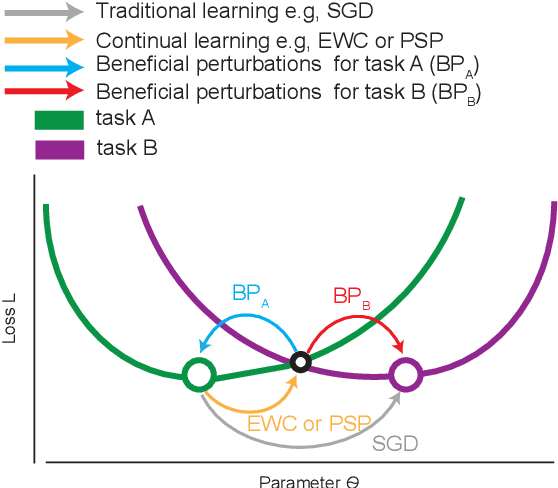
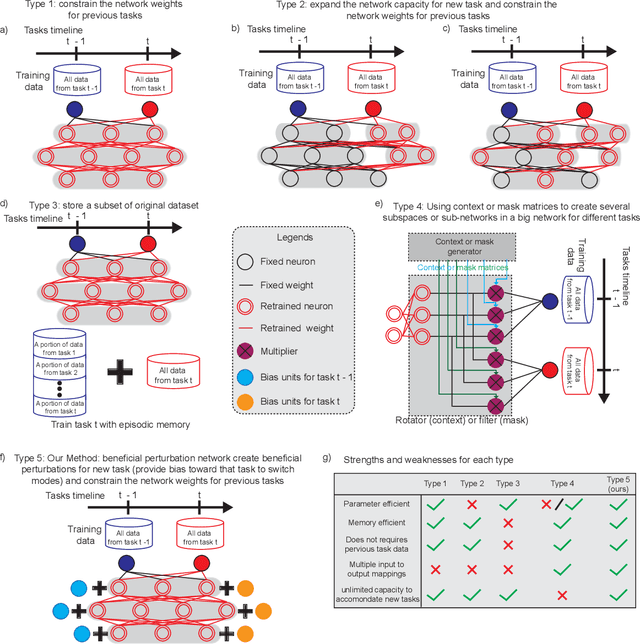
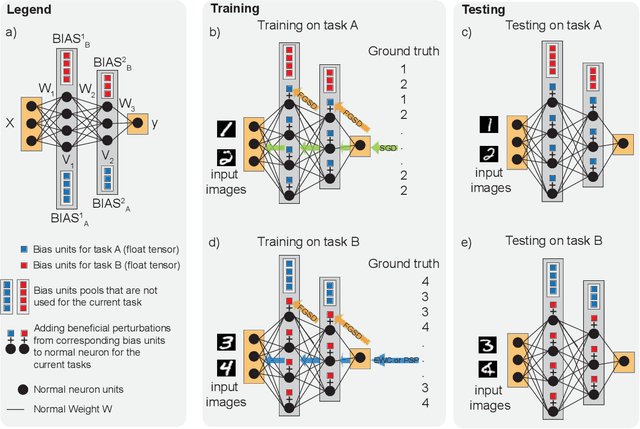
The human brain is the gold standard of adaptive learning. It not only can learn and benefit from experience, but also can adapt to new situations. In contrast, deep neural networks only learn one sophisticated but fixed mapping from inputs to outputs. This limits their applicability to more dynamic situations, where input to output mapping may change with different contexts. A salient example is continual learning - learning new independent tasks sequentially without forgetting previous tasks. Continual learning of multiple tasks in artificial neural networks using gradient descent leads to catastrophic forgetting, whereby a previously learned mapping of an old task is erased when learning new mappings for new tasks. Here, we propose a new biologically plausible type of deep neural network with extra, out-of-network, task-dependent biasing units to accommodate these dynamic situations. This allows, for the first time, a single network to learn potentially unlimited parallel input to output mappings, and to switch on the fly between them at runtime. Biasing units are programmed by leveraging beneficial perturbations (opposite to well-known adversarial perturbations) for each task. Beneficial perturbations for a given task bias the network toward that task, essentially switching the network into a different mode to process that task. This largely eliminates catastrophic interference between tasks. Our approach is memory-efficient and parameter-efficient, can accommodate many tasks, and achieves state-of-the-art performance across different tasks and domains.
Adversarial Training: embedding adversarial perturbations into the parameter space of a neural network to build a robust system
Oct 09, 2019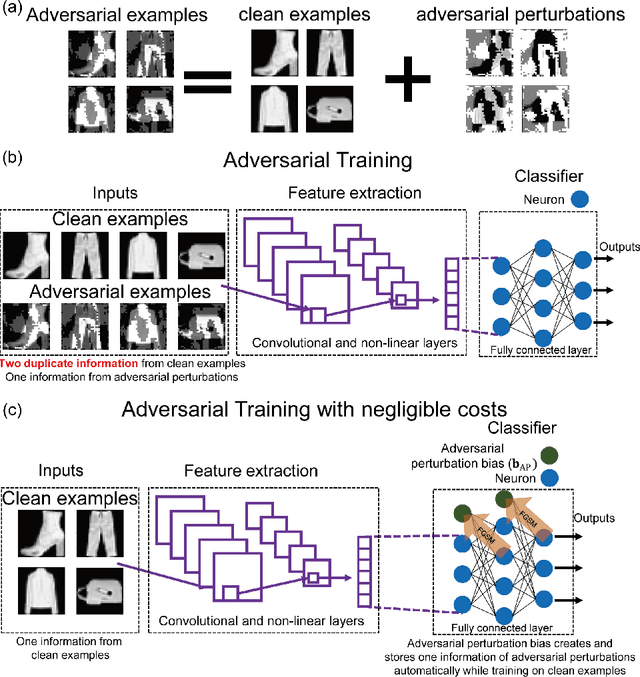
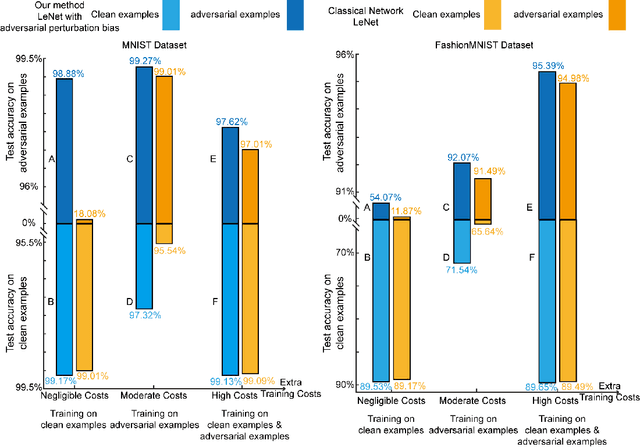
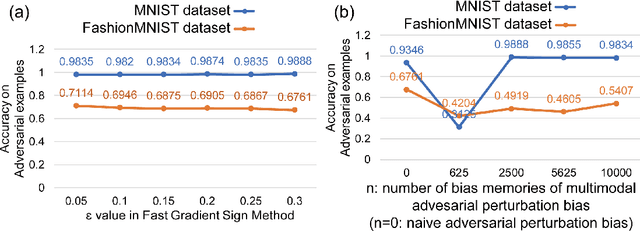
Adversarial training, in which a network is trained on both adversarial and clean examples, is one of the most trusted defense methods against adversarial attacks. However, there are three major practical difficulties in implementing and deploying this method - expensive in terms of extra memory and computation costs; accuracy trade-off between clean and adversarial examples; and lack of diversity of adversarial perturbations. Classical adversarial training uses fixed, precomputed perturbations in adversarial examples (input space). In contrast, we introduce dynamic adversarial perturbations into the parameter space of the network, by adding perturbation biases to the fully connected layers of deep convolutional neural network. During training, using only clean images, the perturbation biases are updated in the Fast Gradient Sign Direction to automatically create and store adversarial perturbations by recycling the gradient information computed. The network learns and adjusts itself automatically to these learned adversarial perturbations. Thus, we can achieve adversarial training with negligible cost compared to requiring a training set of adversarial example images. In addition, if combined with classical adversarial training, our perturbation biases can alleviate accuracy trade-off difficulties, and diversify adversarial perturbations.
Beneficial perturbation network for continual learning
Jun 22, 2019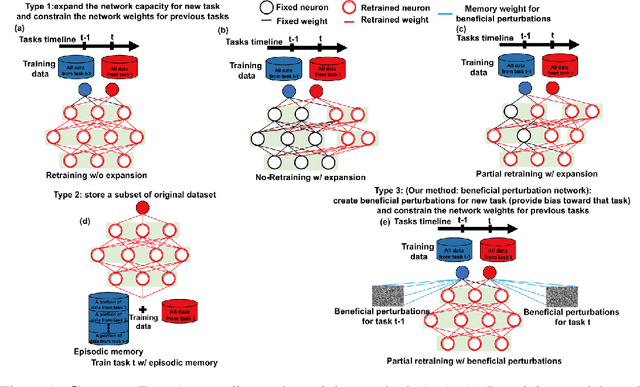
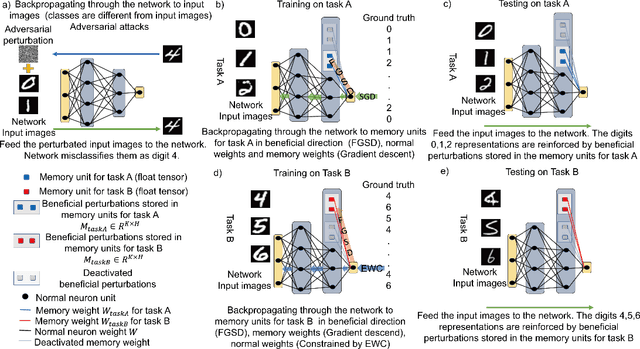
Sequential learning of multiple tasks in artificial neural networks using gradient descent leads to catastrophic forgetting, whereby previously learned knowledge is erased during learning of new, disjoint knowledge. Here, we propose a fundamentally new type of method - Beneficial Perturbation Network (BPN). We add task-dependent memory (biasing) units to allow the network to operate in different regimes for different tasks. We compute the most beneficial directions to train these units, in a manner inspired by recent work on adversarial examples. At test time, beneficial perturbations for a given task bias the network toward that task to overcome catastrophic forgetting. BPN is not only more parameter-efficient than network expansion methods, but also does not need to store any data from previous tasks, in contrast with episodic memory methods. Experiments on variants of the MNIST, CIFAR-10, CIFAR-100 datasets demonstrate strong performance of BPN when compared to the state-of-the-art.
Overcoming catastrophic forgetting problem by weight consolidation and long-term memory
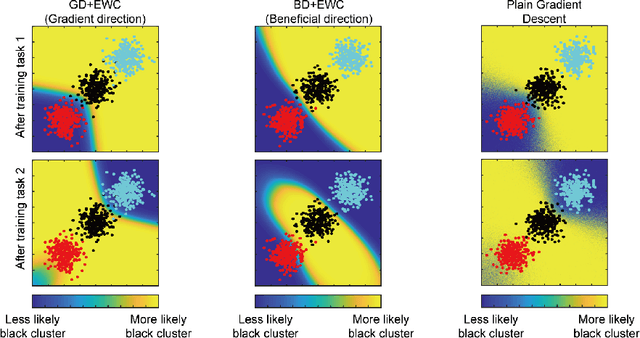
May 18, 2018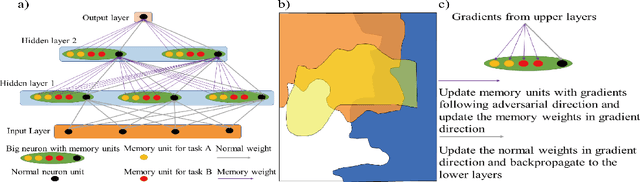

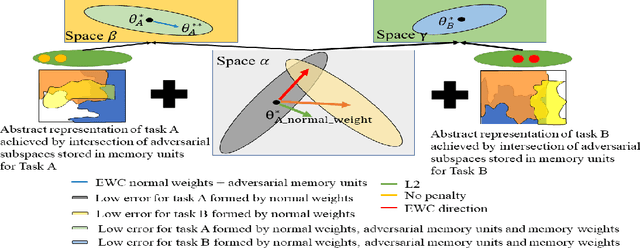
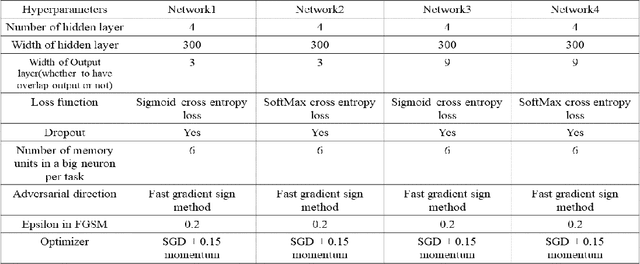
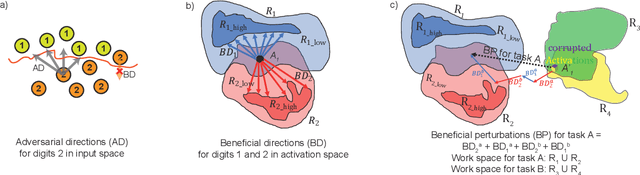
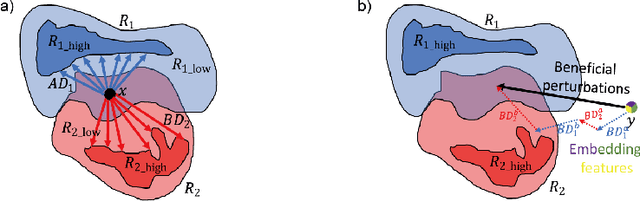
Sequential learning of multiple tasks in artificial neural networks using gradient descent leads to catastrophic forgetting, whereby previously learned knowledge is erased during learning of new, disjoint knowledge. Here, we propose a new approach to sequential learning which leverages the recent discovery of adversarial examples. We use adversarial subspaces from previous tasks to enable learning of new tasks with less interference. We apply our method to sequentially learning to classify digits 0, 1, 2 (task 1), 4, 5, 6, (task 2), and 7, 8, 9 (task 3) in MNIST (disjoint MNIST task). We compare and combine our Adversarial Direction (AD) method with the recently proposed Elastic Weight Consolidation (EWC) method for sequential learning. We train each task for 20 epochs, which yields good initial performance (99.24% correct task 1 performance). After training task 2, and then task 3, both plain gradient descent (PGD) and EWC largely forget task 1 (task 1 accuracy 32.95% for PGD and 41.02% for EWC), while our combined approach (AD+EWC) still achieves 94.53% correct on task 1. We obtain similar results with a much more difficult disjoint CIFAR10 task, which to our knowledge had not been attempted before (70.10% initial task 1 performance, 67.73% after learning tasks 2 and 3 for AD+EWC, while PGD and EWC both fall to chance level). Our results suggest that AD+EWC can provide better sequential learning performance than either PGD or EWC.