 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeneficial perturbation network for continual learning
Paper and Code
Jun 22, 2019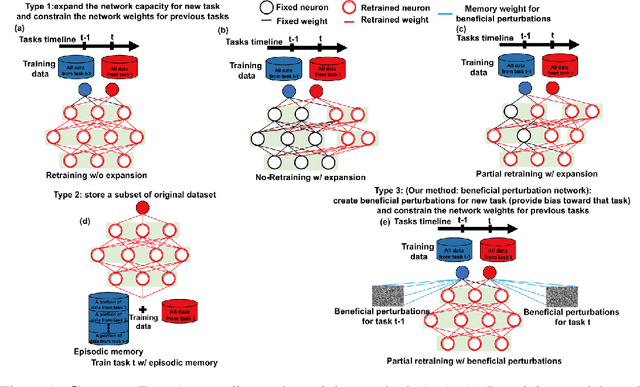
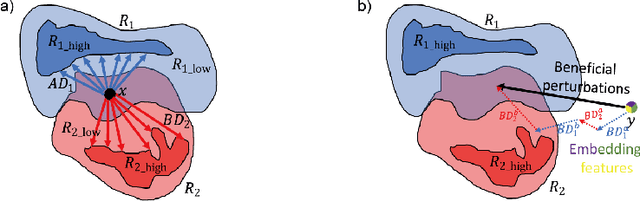
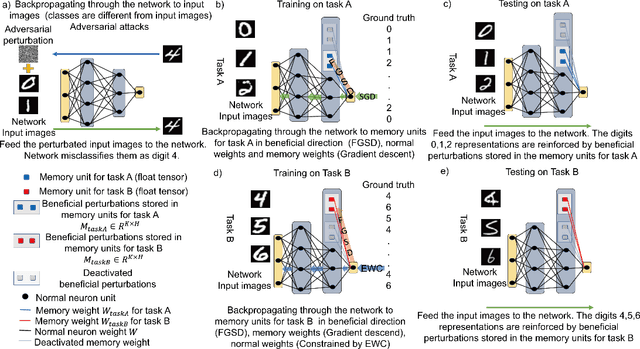
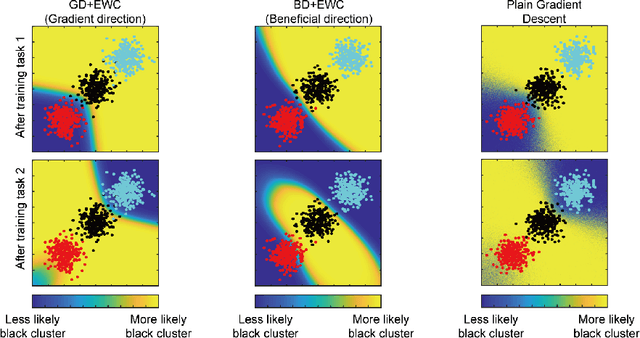
Sequential learning of multiple tasks in artificial neural networks using gradient descent leads to catastrophic forgetting, whereby previously learned knowledge is erased during learning of new, disjoint knowledge. Here, we propose a fundamentally new type of method - Beneficial Perturbation Network (BPN). We add task-dependent memory (biasing) units to allow the network to operate in different regimes for different tasks. We compute the most beneficial directions to train these units, in a manner inspired by recent work on adversarial examples. At test time, beneficial perturbations for a given task bias the network toward that task to overcome catastrophic forgetting. BPN is not only more parameter-efficient than network expansion methods, but also does not need to store any data from previous tasks, in contrast with episodic memory methods. Experiments on variants of the MNIST, CIFAR-10, CIFAR-100 datasets demonstrate strong performance of BPN when compared to the state-of-the-art.