 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFullCircle: Effortless 3D Reconstruction from Casual 360$^\circ$ Captures
Mar 23, 2026Radiance fields have emerged as powerful tools for 3D scene reconstruction. However, casual capture remains challenging due to the narrow field of view of perspective cameras, which limits viewpoint coverage and feature correspondences necessary for reliable camera calibration and reconstruction. While commercially available 360$^\circ$ cameras offer significantly broader coverage than perspective cameras for the same capture effort, existing 360$^\circ$ reconstruction methods require special capture protocols and pre-processing steps that undermine the promise of radiance fields: effortless workflows to capture and reconstruct 3D scenes. We propose a practical pipeline for reconstructing 3D scenes directly from raw 360$^\circ$ camera captures. We require no special capture protocols or pre-processing, and exhibit robustness to a prevalent source of reconstruction errors: the human operator that is visible in all 360$^\circ$ imagery. To facilitate evaluation, we introduce a multi-tiered dataset of scenes captured as raw dual-fisheye images, establishing a benchmark for robust casual 360$^\circ$ reconstruction. Our method significantly outperforms not only vanilla 3DGS for 360$^\circ$ cameras but also robust perspective baselines when perspective cameras are simulated from the same capture, demonstrating the advantages of 360$^\circ$ capture for casual reconstruction. Additional results are available at: https://theialab.github.io/fullcircle
Does Gaussian Splatting need SFM Initialization?
Apr 18, 2024
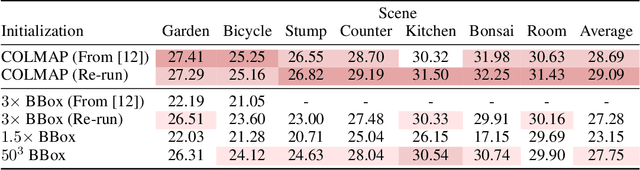

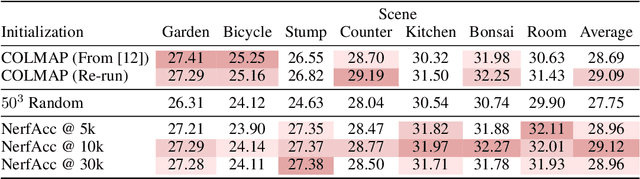
3D Gaussian Splatting has recently been embraced as a versatile and effective method for scene reconstruction and novel view synthesis, owing to its high-quality results and compatibility with hardware rasterization. Despite its advantages, Gaussian Splatting's reliance on high-quality point cloud initialization by Structure-from-Motion (SFM) algorithms is a significant limitation to be overcome. To this end, we investigate various initialization strategies for Gaussian Splatting and delve into how volumetric reconstructions from Neural Radiance Fields (NeRF) can be utilized to bypass the dependency on SFM data. Our findings demonstrate that random initialization can perform much better if carefully designed and that by employing a combination of improved initialization strategies and structure distillation from low-cost NeRF models, it is possible to achieve equivalent results, or at times even superior, to those obtained from SFM initialization.
Base Layer Efficiency in Scalable Human-Machine Coding
Jul 05, 2023A basic premise in scalable human-machine coding is that the base layer is intended for automated machine analysis and is therefore more compressible than the same content would be for human viewing. Use cases for such coding include video surveillance and traffic monitoring, where the majority of the content will never be seen by humans. Therefore, base layer efficiency is of paramount importance because the system would most frequently operate at the base-layer rate. In this paper, we analyze the coding efficiency of the base layer in a state-of-the-art scalable human-machine image codec, and show that it can be improved. In particular, we demonstrate that gains of 20-40% in BD-Rate compared to the currently best results on object detection and instance segmentation are possible.
Rate-Distortion Theory in Coding for Machines and its Application
May 26, 2023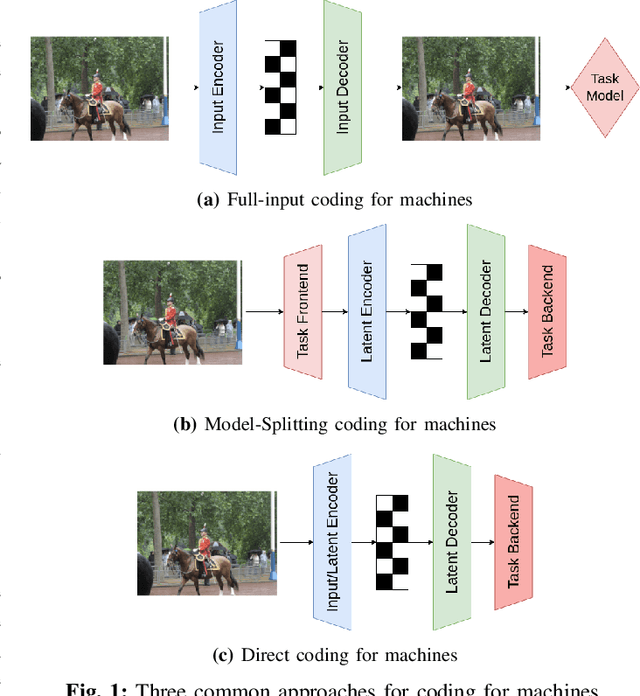
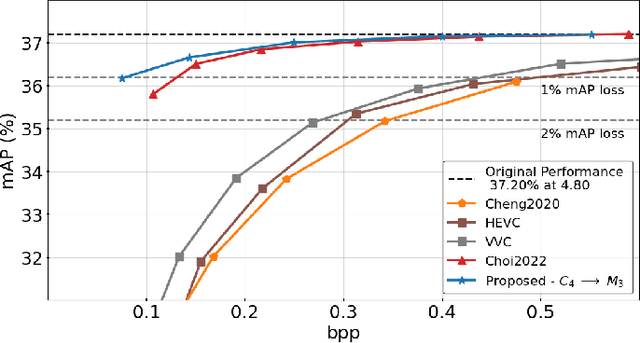
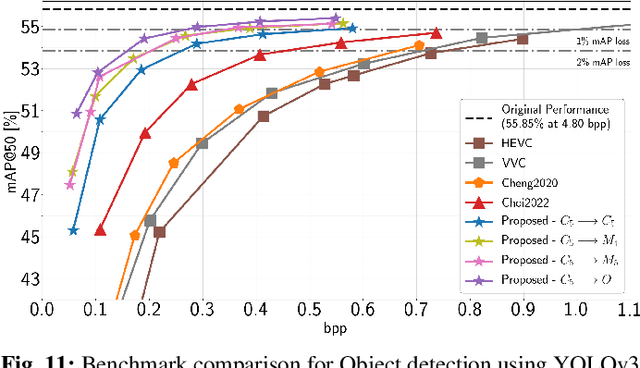
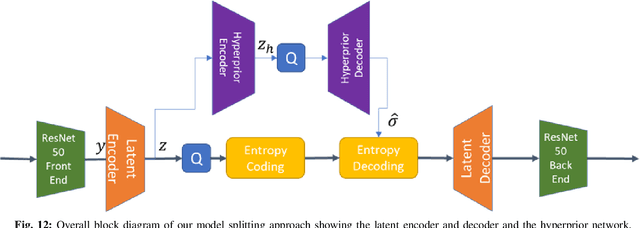
Recent years have seen a tremendous growth in both the capability and popularity of automatic machine analysis of images and video. As a result, a growing need for efficient compression methods optimized for machine vision, rather than human vision, has emerged. To meet this growing demand, several methods have been developed for image and video coding for machines. Unfortunately, while there is a substantial body of knowledge regarding rate-distortion theory for human vision, the same cannot be said of machine analysis. In this paper, we extend the current rate-distortion theory for machines, providing insight into important design considerations of machine-vision codecs. We then utilize this newfound understanding to improve several methods for learnable image coding for machines. Our proposed methods achieve state-of-the-art rate-distortion performance on several computer vision tasks such as classification, instance segmentation, and object detection.
VVC+M: Plug and Play Scalable Image Coding for Humans and Machines
May 17, 2023


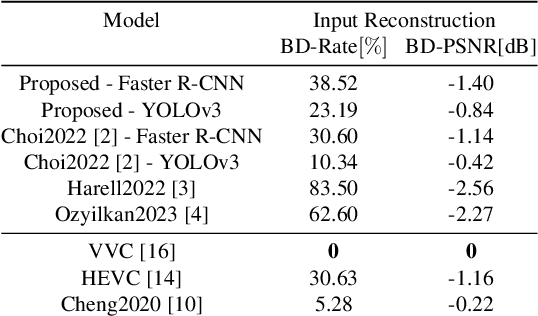
Compression for machines is an emerging field, where inputs are encoded while optimizing the performance of downstream automated analysis. In scalable coding for humans and machines, the compressed representation used for machines is further utilized to enable input reconstruction. Often performed by jointly optimizing the compression scheme for both machine task and human perception, this results in sub-optimal rate-distortion (RD) performance for the machine side. We focus on the case of images, proposing to utilize the pre-existing residual coding capabilities of video codecs such as VVC to create a scalable codec from any image compression for machines (ICM) scheme. Using our approach we improve an existing scalable codec to achieve superior RD performance on the machine task, while remaining competitive for human perception. Moreover, our approach can be trained post-hoc for any given ICM scheme, and without creating a coupling between the quality of the machine analysis and human vision.
Conditional and Residual Methods in Scalable Coding for Humans and Machines
May 04, 2023We present methods for conditional and residual coding in the context of scalable coding for humans and machines. Our focus is on optimizing the rate-distortion performance of the reconstruction task using the information available in the computer vision task. We include an information analysis of both approaches to provide baselines and also propose an entropy model suitable for conditional coding with increased modelling capacity and similar tractability as previous work. We apply these methods to image reconstruction, using, in one instance, representations created for semantic segmentation on the Cityscapes dataset, and in another instance, representations created for object detection on the COCO dataset. In both experiments, we obtain similar performance between the conditional and residual methods, with the resulting rate-distortion curves contained within our baselines.
Control of computer pointer using hand gesture recognition in motion pictures
Dec 24, 2020



A user interface is designed to control the computer cursor by hand detection and classification of its gesture. A hand dataset with 6720 image samples is collected, including four classes: fist, palm, pointing to the left, and pointing to the right. The images are captured from 15 persons in simple backgrounds and different perspectives and light conditions. A CNN network is trained on this dataset to predict a label for each captured image and measure the similarity of them. Finally, commands are defined to click, right-click and move the cursor. The algorithm has 91.88% accuracy and can be used in different backgrounds.