 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompt-Guided Prefiltering for VLM Image Compression
Mar 31, 2026The rapid progress of large Vision-Language Models (VLMs) has enabled a wide range of applications, such as image understanding and Visual Question Answering (VQA). Query images are often uploaded to the cloud, where VLMs are typically hosted, hence efficient image compression becomes crucial. However, traditional human-centric codecs are suboptimal in this setting because they preserve many task-irrelevant details. Existing Image Coding for Machines (ICM) methods also fall short, as they assume a fixed set of downstream tasks and cannot adapt to prompt-driven VLMs with an open-ended variety of objectives. We propose a lightweight, plug-and-play, prompt-guided prefiltering module to identify image regions most relevant to the text prompt, and consequently to the downstream task. The module preserves important details while smoothing out less relevant areas to improve compression efficiency. It is codec-agnostic and can be applied before conventional and learned encoders. Experiments on several VQA benchmarks show that our approach achieves a 25-50% average bitrate reduction while maintaining the same task accuracy. Our source code is available at https://github.com/bardia-az/pgp-vlm-compression.
Smart Split-Federated Learning over Noisy Channels for Embryo Image Segmentation
Jan 26, 2026Split-Federated (SplitFed) learning is an extension of federated learning that places minimal requirements on the clients computing infrastructure, since only a small portion of the overall model is deployed on the clients hardware. In SplitFed learning, feature values, gradient updates, and model updates are transferred across communication channels. In this paper, we study the effects of noise in the communication channels on the learning process and the quality of the final model. We propose a smart averaging strategy for SplitFed learning with the goal of improving resilience against channel noise. Experiments on a segmentation model for embryo images shows that the proposed smart averaging strategy is able to tolerate two orders of magnitude stronger noise in the communication channels compared to conventional averaging, while still maintaining the accuracy of the final model.
Rate-Distortion Theory in Coding for Machines and its Application
May 26, 2023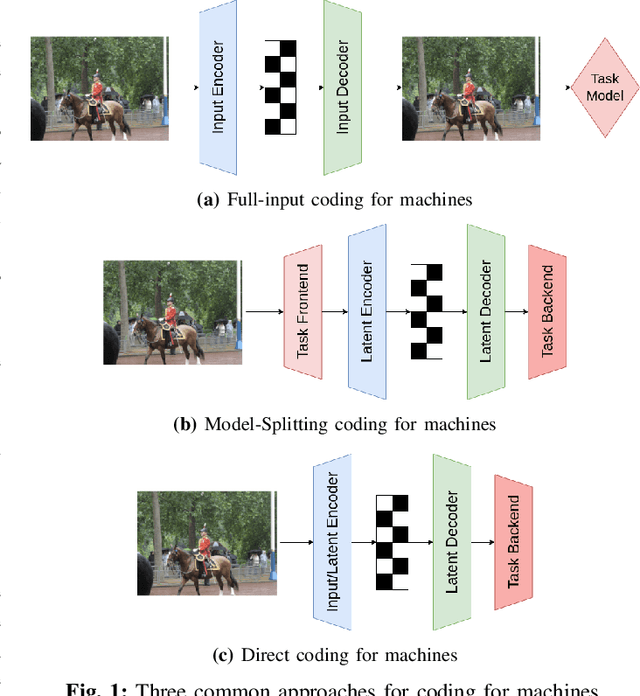
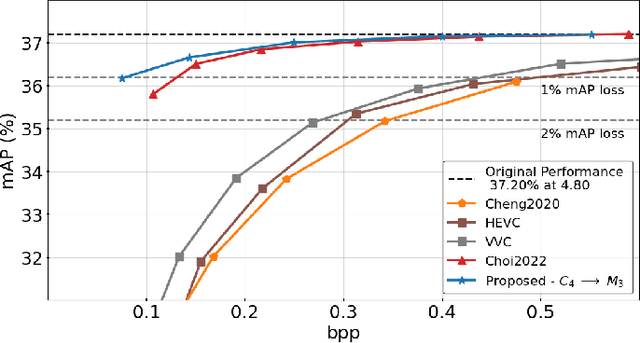
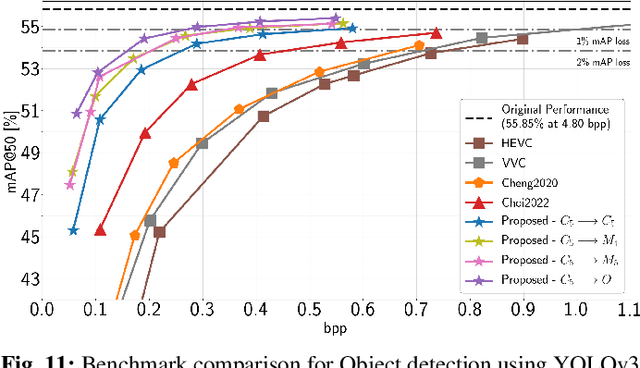
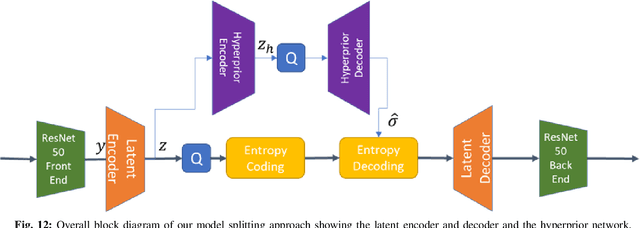
Recent years have seen a tremendous growth in both the capability and popularity of automatic machine analysis of images and video. As a result, a growing need for efficient compression methods optimized for machine vision, rather than human vision, has emerged. To meet this growing demand, several methods have been developed for image and video coding for machines. Unfortunately, while there is a substantial body of knowledge regarding rate-distortion theory for human vision, the same cannot be said of machine analysis. In this paper, we extend the current rate-distortion theory for machines, providing insight into important design considerations of machine-vision codecs. We then utilize this newfound understanding to improve several methods for learnable image coding for machines. Our proposed methods achieve state-of-the-art rate-distortion performance on several computer vision tasks such as classification, instance segmentation, and object detection.
VVC+M: Plug and Play Scalable Image Coding for Humans and Machines
May 17, 2023


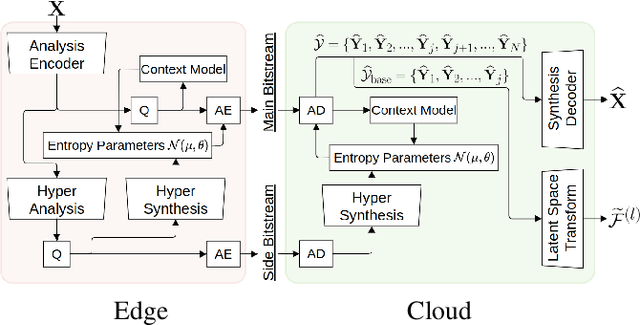
Compression for machines is an emerging field, where inputs are encoded while optimizing the performance of downstream automated analysis. In scalable coding for humans and machines, the compressed representation used for machines is further utilized to enable input reconstruction. Often performed by jointly optimizing the compression scheme for both machine task and human perception, this results in sub-optimal rate-distortion (RD) performance for the machine side. We focus on the case of images, proposing to utilize the pre-existing residual coding capabilities of video codecs such as VVC to create a scalable codec from any image compression for machines (ICM) scheme. Using our approach we improve an existing scalable codec to achieve superior RD performance on the machine task, while remaining competitive for human perception. Moreover, our approach can be trained post-hoc for any given ICM scheme, and without creating a coupling between the quality of the machine analysis and human vision.
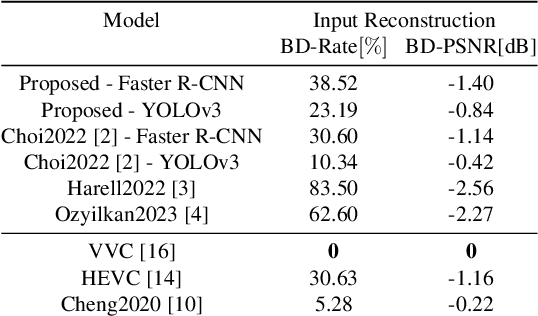
Rate-Distortion in Image Coding for Machines
Sep 21, 2022
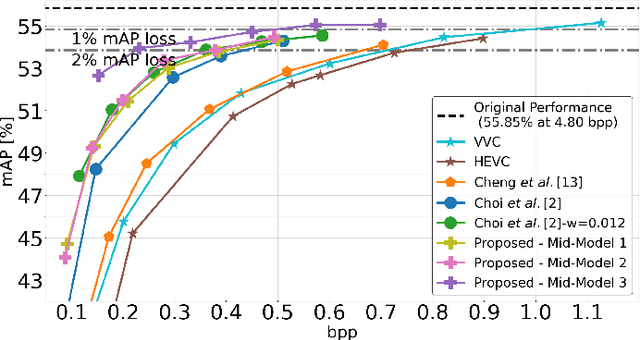
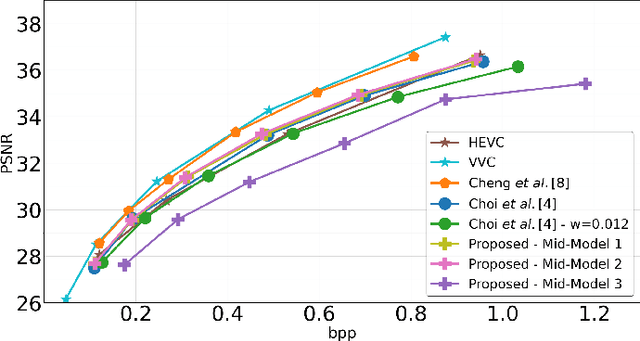
In recent years, there has been a sharp increase in transmission of images to remote servers specifically for the purpose of computer vision. In many applications, such as surveillance, images are mostly transmitted for automated analysis, and rarely seen by humans. Using traditional compression for this scenario has been shown to be inefficient in terms of bit-rate, likely due to the focus on human based distortion metrics. Thus, it is important to create specific image coding methods for joint use by humans and machines. One way to create the machine side of such a codec is to perform feature matching of some intermediate layer in a Deep Neural Network performing the machine task. In this work, we explore the effects of the layer choice used in training a learnable codec for humans and machines. We prove, using the data processing inequality, that matching features from deeper layers is preferable in the sense of rate-distortion. Next, we confirm our findings empirically by re-training an existing model for scalable human-machine coding. In our experiments we show the trade-off between the human and machine sides of such a scalable model, and discuss the benefit of using deeper layers for training in that regard.
Efficient Signed Graph Sampling via Balancing & Gershgorin Disc Perfect Alignment
Aug 18, 2022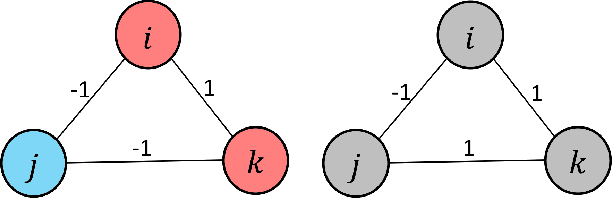
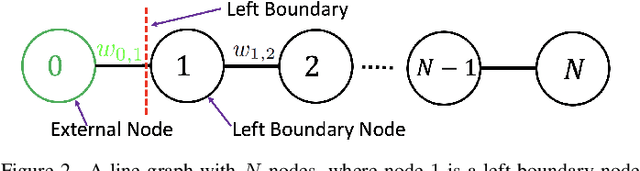
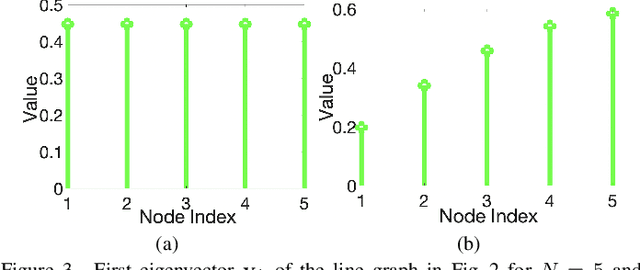
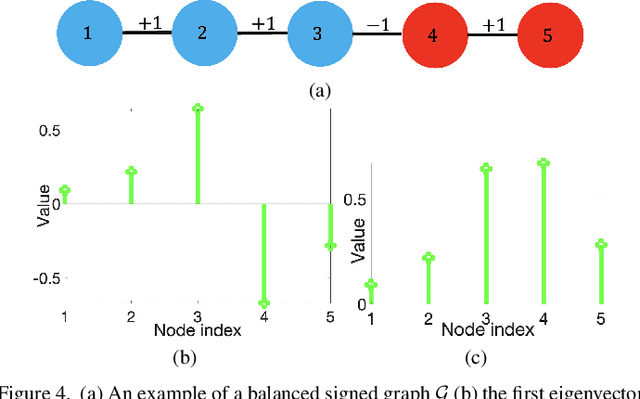
A basic premise in graph signal processing (GSP) is that a graph encoding pairwise (anti-)correlations of the targeted signal as edge weights is exploited for graph filtering. However, existing fast graph sampling schemes are designed and tested only for positive graphs describing positive correlations. In this paper, we show that for datasets with strong inherent anti-correlations, a suitable graph contains both positive and negative edge weights. In response, we propose a linear-time signed graph sampling method centered on the concept of balanced signed graphs. Specifically, given an empirical covariance data matrix $\bar{\bf{C}}$, we first learn a sparse inverse matrix (graph Laplacian) $\mathcal{L}$ corresponding to a signed graph $\mathcal{G}$. We define the eigenvectors of Laplacian $\mathcal{L}_B$ for a balanced signed graph $\mathcal{G}_B$ -- approximating $\mathcal{G}$ via edge weight augmentation -- as graph frequency components. Next, we choose samples to minimize the low-pass filter reconstruction error in two steps. We first align all Gershgorin disc left-ends of Laplacian $\mathcal{L}_B$ at smallest eigenvalue $\lambda_{\min}(\mathcal{L}_B)$ via similarity transform $\mathcal{L}_p = \S \mathcal{L}_B \S^{-1}$, leveraging a recent linear algebra theorem called Gershgorin disc perfect alignment (GDPA). We then perform sampling on $\mathcal{L}_p$ using a previous fast Gershgorin disc alignment sampling (GDAS) scheme. Experimental results show that our signed graph sampling method outperformed existing fast sampling schemes noticeably on various datasets.
Collaborative Inference for AI-Empowered IoT Devices
Jul 24, 2022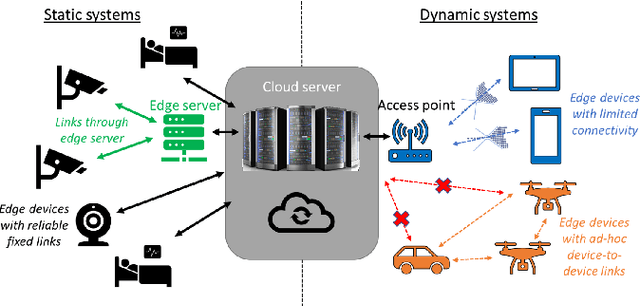
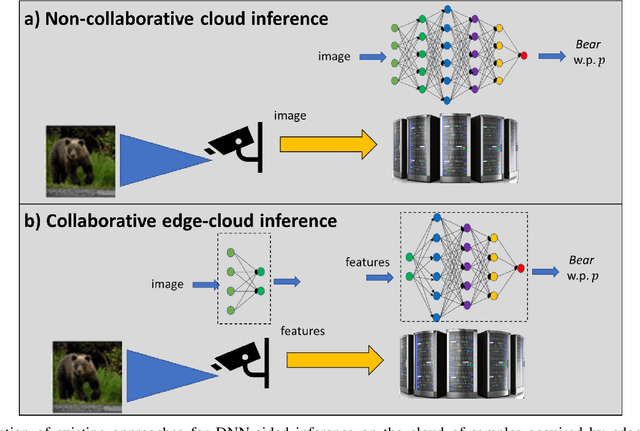
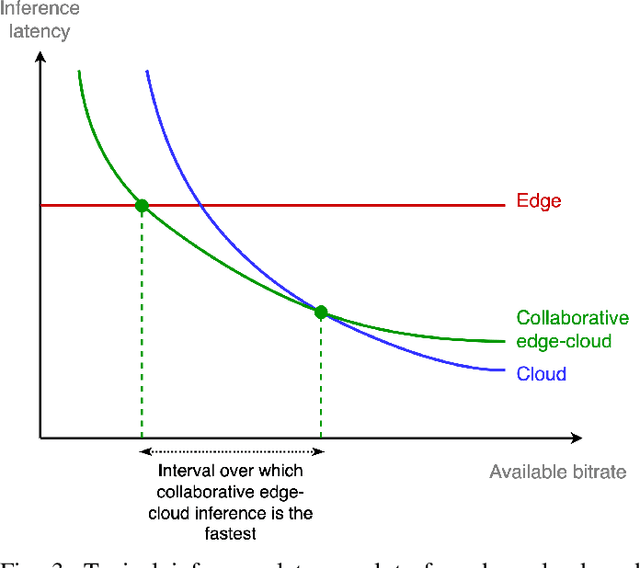
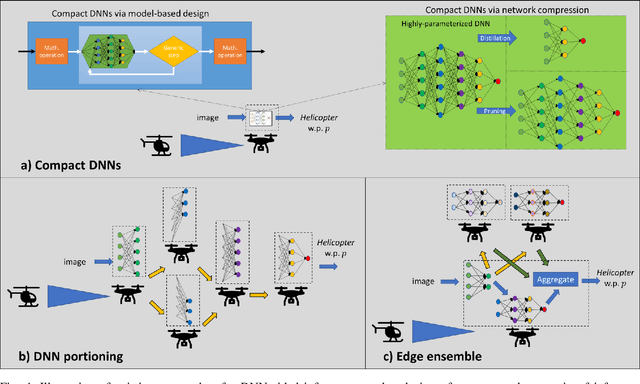
Artificial intelligence (AI) technologies, and particularly deep learning systems, are traditionally the domain of large-scale cloud servers, which have access to high computational and energy resources. Nonetheless, in Internet-of-Things (IoT) networks, the interface with the real-world is carried out using edge devices that are limited in hardware and can communicate. The conventional approach to provide AI processing to data collected by edge devices involves sending samples to the cloud, at the cost of latency, communication, connectivity, and privacy concerns. Consequently, recent years have witnessed a growing interest in enabling AI-aided inference on edge devices by leveraging their communication capabilities to establish collaborative inference. This article reviews candidate strategies for facilitating the transition of AI to IoT devices via collaboration. We identify the need to operate in different mobility and connectivity constraints as a motivating factor to consider multiple schemes, which can be roughly divided into methods where inference is done remotely, i.e., on the cloud, and those that infer on the edge. We identify the key characteristics of each strategy in terms of inference accuracy, communication latency, privacy, and connectivity requirements, providing a systematic comparison between existing approaches. We conclude by presenting future research challenges and opportunities arising from the concept of collaborative inference.
Scalable Image Coding for Humans and Machines
Jul 18, 2021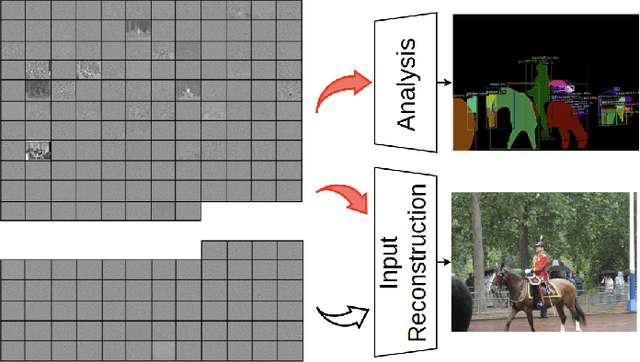
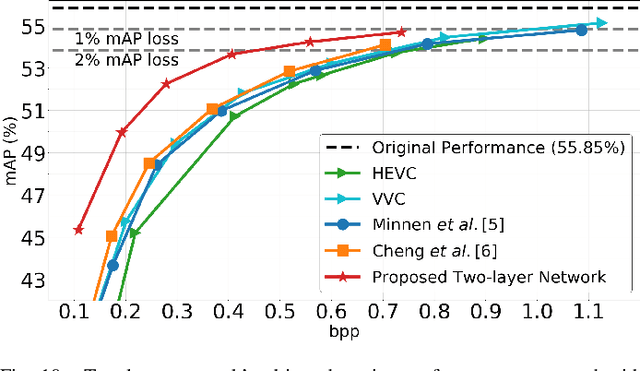
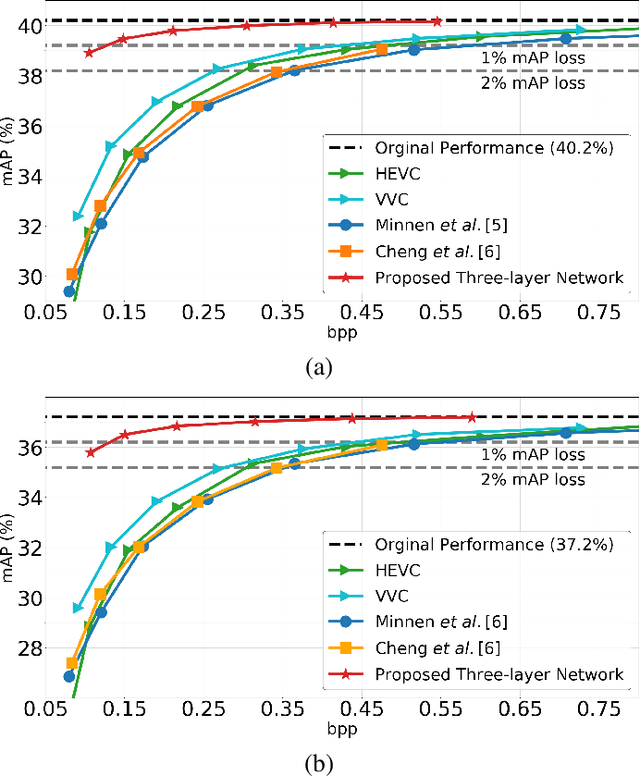
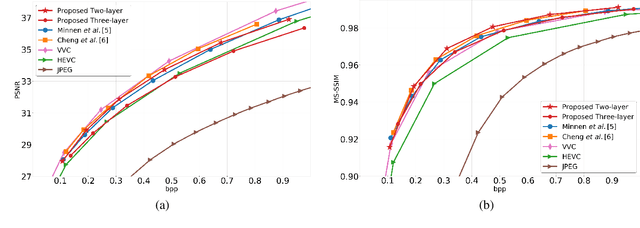
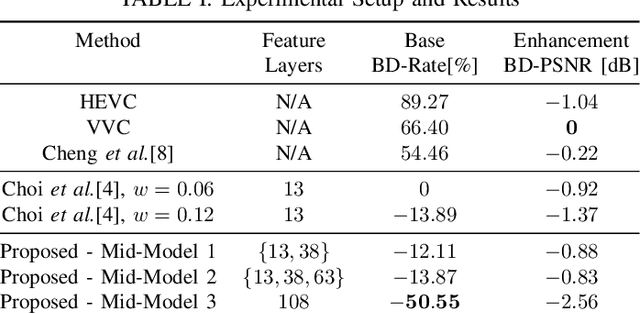
At present, and increasingly so in the future, much of the captured visual content will not be seen by humans. Instead, it will be used for automated machine vision analytics and may require occasional human viewing. Examples of such applications include traffic monitoring, visual surveillance, autonomous navigation, and industrial machine vision. To address such requirements, we develop an end-to-end learned image codec whose latent space is designed to support scalability from simpler to more complicated tasks. The simplest task is assigned to a subset of the latent space (the base layer), while more complicated tasks make use of additional subsets of the latent space, i.e., both the base and enhancement layer(s). For the experiments, we establish a 2-layer and a 3-layer model, each of which offers input reconstruction for human vision, plus machine vision task(s), and compare them with relevant benchmarks. The experiments show that our scalable codecs offer 37%-80% bitrate savings on machine vision tasks compared to best alternatives, while being comparable to state-of-the-art image codecs in terms of input reconstruction.
Latent-space scalability for multi-task collaborative intelligence
May 21, 2021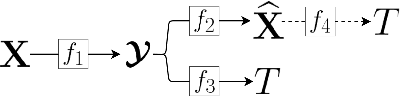
We investigate latent-space scalability for multi-task collaborative intelligence, where one of the tasks is object detection and the other is input reconstruction. In our proposed approach, part of the latent space can be selectively decoded to support object detection while the remainder can be decoded when input reconstruction is needed. Such an approach allows reduced computational resources when only object detection is required, and this can be achieved without reconstructing input pixels. By varying the scaling factors of various terms in the training loss function, the system can be trained to achieve various trade-offs between object detection accuracy and input reconstruction quality. Experiments are conducted to demonstrate the adjustable system performance on the two tasks compared to the relevant benchmarks.
Exploring Bayesian Surprise to Prevent Overfitting and to Predict Model Performance in Non-Intrusive Load Monitoring
Sep 16, 2020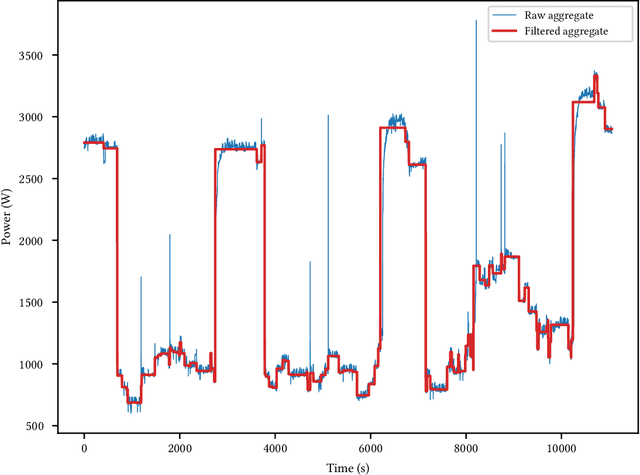
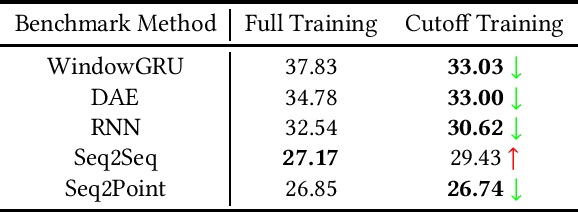
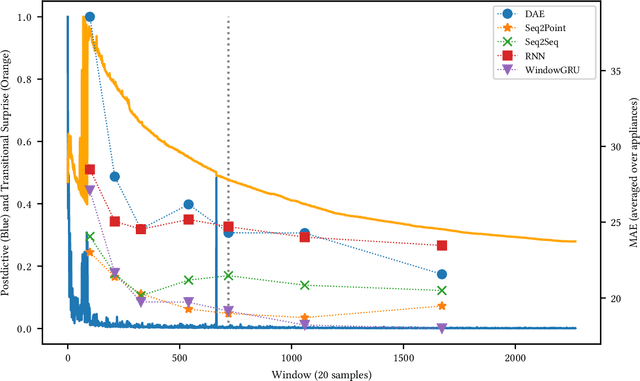
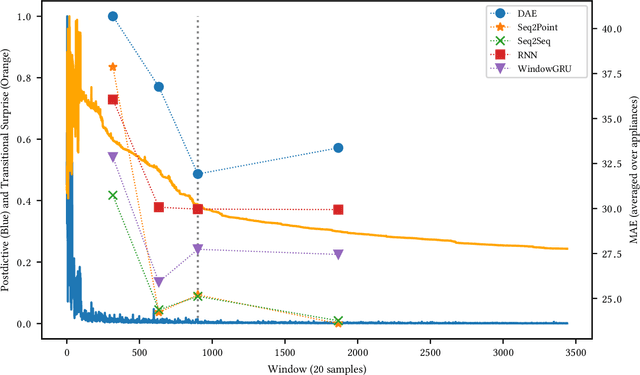
Non-Intrusive Load Monitoring (NILM) is a field of research focused on segregating constituent electrical loads in a system based only on their aggregated signal. Significant computational resources and research time are spent training models, often using as much data as possible, perhaps driven by the preconception that more data equates to more accurate models and better performing algorithms. When has enough prior training been done? When has a NILM algorithm encountered new, unseen data? This work applies the notion of Bayesian surprise to answer these questions which are important for both supervised and unsupervised algorithms. We quantify the degree of surprise between the predictive distribution (termed postdictive surprise), as well as the transitional probabilities (termed transitional surprise), before and after a window of observations. We compare the performance of several benchmark NILM algorithms supported by NILMTK, in order to establish a useful threshold on the two combined measures of surprise. We validate the use of transitional surprise by exploring the performance of a popular Hidden Markov Model as a function of surprise threshold. Finally, we explore the use of a surprise threshold as a regularization technique to avoid overfitting in cross-dataset performance. Although the generality of the specific surprise threshold discussed herein may be suspect without further testing, this work provides clear evidence that a point of diminishing returns of model performance with respect to dataset size exists. This has implications for future model development, dataset acquisition, as well as aiding in model flexibility during deployment.