 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Bayesian Surprise to Prevent Overfitting and to Predict Model Performance in Non-Intrusive Load Monitoring
Sep 16, 2020
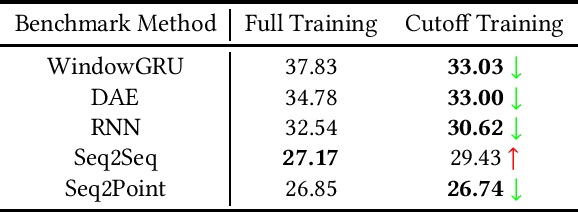
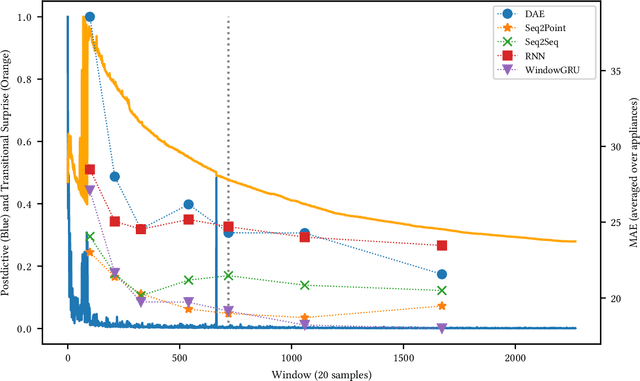
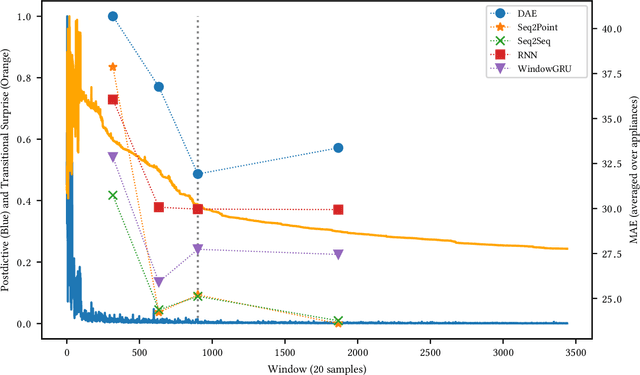
Non-Intrusive Load Monitoring (NILM) is a field of research focused on segregating constituent electrical loads in a system based only on their aggregated signal. Significant computational resources and research time are spent training models, often using as much data as possible, perhaps driven by the preconception that more data equates to more accurate models and better performing algorithms. When has enough prior training been done? When has a NILM algorithm encountered new, unseen data? This work applies the notion of Bayesian surprise to answer these questions which are important for both supervised and unsupervised algorithms. We quantify the degree of surprise between the predictive distribution (termed postdictive surprise), as well as the transitional probabilities (termed transitional surprise), before and after a window of observations. We compare the performance of several benchmark NILM algorithms supported by NILMTK, in order to establish a useful threshold on the two combined measures of surprise. We validate the use of transitional surprise by exploring the performance of a popular Hidden Markov Model as a function of surprise threshold. Finally, we explore the use of a surprise threshold as a regularization technique to avoid overfitting in cross-dataset performance. Although the generality of the specific surprise threshold discussed herein may be suspect without further testing, this work provides clear evidence that a point of diminishing returns of model performance with respect to dataset size exists. This has implications for future model development, dataset acquisition, as well as aiding in model flexibility during deployment.
Towards Comparability in Non-Intrusive Load Monitoring: On Data and Performance Evaluation
Jan 20, 2020


Non-Intrusive Load Monitoring (NILM) comprises of a set of techniques that provide insights into the energy consumption of households and industrial facilities. Latest contributions show significant improvements in terms of accuracy and generalisation abilities. Despite all progress made concerning disaggregation techniques, performance evaluation and comparability remains an open research question. The lack of standardisation and consensus on evaluation procedures makes reproducibility and comparability extremely difficult. In this paper, we draw attention to comparability in NILM with a focus on highlighting the considerable differences amongst common energy datasets used to test the performance of algorithms. We divide discussion on comparability into data aspects, performance metrics, and give a close view on evaluation processes. Detailed information on pre-processing as well as data cleaning methods, the importance of unified performance reporting, and the need for complexity measures in load disaggregation are found to be the most urgent issues in NILM-related research. In addition, our evaluation suggests that datasets should be chosen carefully. We conclude by formulating suggestions for future work to enhance comparability.
On Metrics to Assess the Transferability of Machine Learning Models in Non-Intrusive Load Monitoring
Dec 12, 2019



To assess the performance of load disaggregation algorithms it is common practise to train a candidate algorithm on data from one or multiple households and subsequently apply cross-validation by evaluating the classification and energy estimation performance on unseen portions of the dataset derived from the same households. With an emerging discussion of transferability in Non-Intrusive Load Monitoring (NILM), there is a need for domain-specific metrics to assess the performance of NILM algorithms on new test scenarios being unseen buildings. In this paper, we discuss several metrics to assess the generalisation ability of NILM algorithms. These metrics target different aspects of performance evaluation in NILM and are meant to complement the traditional performance evaluation approach. We demonstrate how our metrics can be utilised to evaluate NILM algorithms by means of two case studies. We conduct our studies on several energy consumption datasets and take into consideration five state-of-the-art as well as four baseline NILM solutions. Finally, we formulate research challenges for future work.