 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent-space scalability for multi-task collaborative intelligence
Paper and Code
May 21, 2021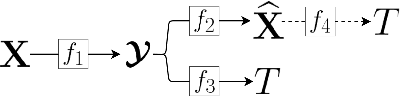
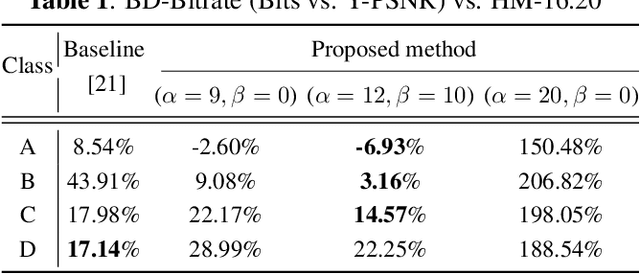
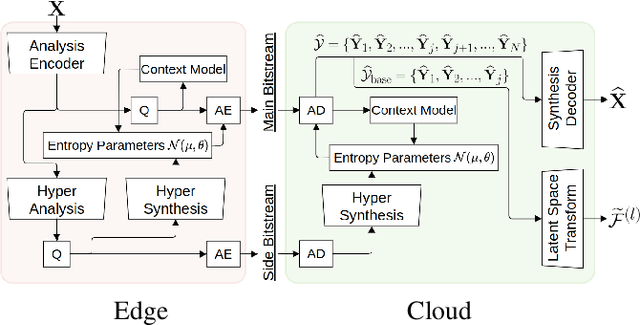
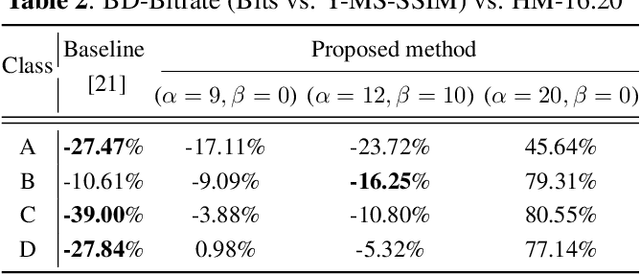
We investigate latent-space scalability for multi-task collaborative intelligence, where one of the tasks is object detection and the other is input reconstruction. In our proposed approach, part of the latent space can be selectively decoded to support object detection while the remainder can be decoded when input reconstruction is needed. Such an approach allows reduced computational resources when only object detection is required, and this can be achieved without reconstructing input pixels. By varying the scaling factors of various terms in the training loss function, the system can be trained to achieve various trade-offs between object detection accuracy and input reconstruction quality. Experiments are conducted to demonstrate the adjustable system performance on the two tasks compared to the relevant benchmarks.