 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDFTS2: Simulating Deep Feature Transmission Over Packet Loss Channels
Dec 01, 2021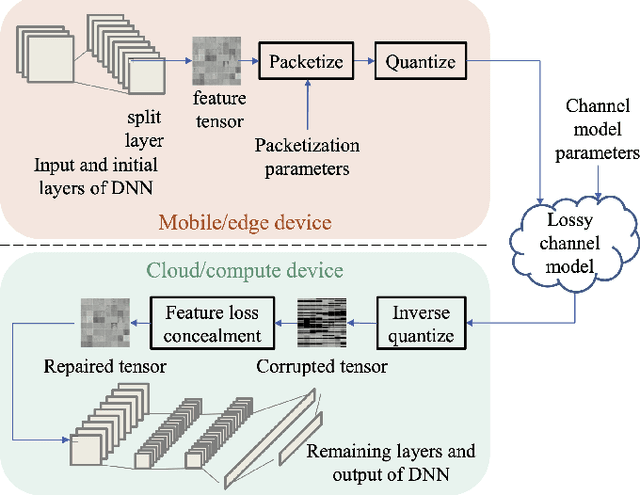
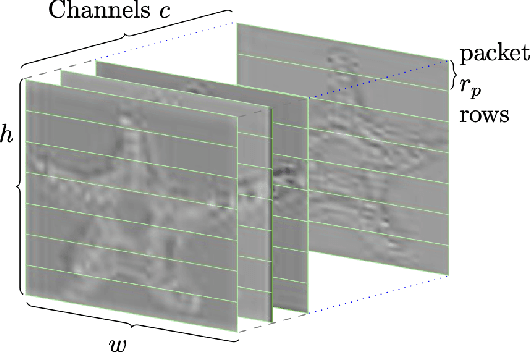
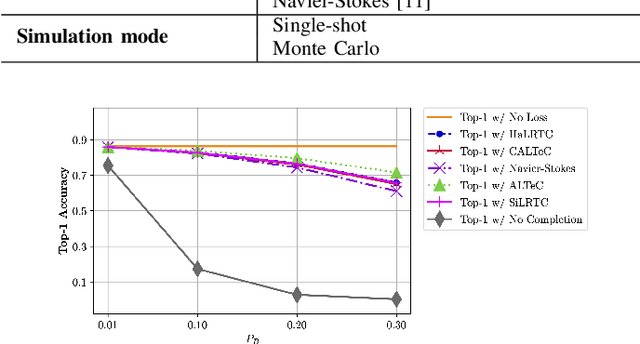

In edge-cloud collaborative intelligence (CI), an unreliable transmission channel exists in the information path of the AI model performing the inference. It is important to be able to simulate the performance of the CI system across an imperfect channel in order to understand system behavior and develop appropriate error control strategies. In this paper we present a simulation framework called DFTS2, which enables researchers to define the components of the CI system in TensorFlow~2, select a packet-based channel model with various parameters, and simulate system behavior under various channel conditions and error/loss control strategies. Using DFTS2, we also present the most comprehensive study to date of the packet loss concealment methods for collaborative image classification models.
CALTeC: Content-Adaptive Linear Tensor Completion for Collaborative Intelligence
Jun 10, 2021
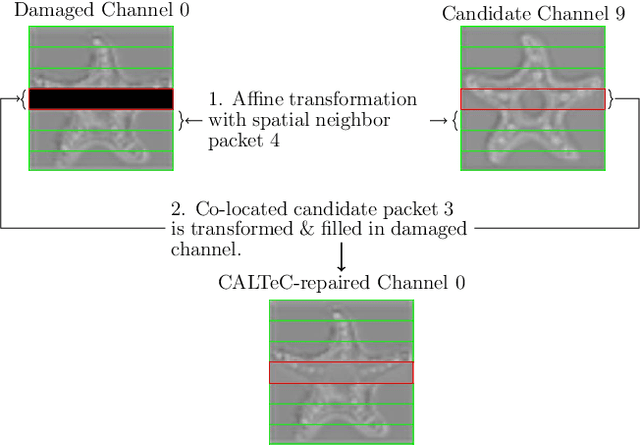


In collaborative intelligence, an artificial intelligence (AI) model is typically split between an edge device and the cloud. Feature tensors produced by the edge sub-model are sent to the cloud via an imperfect communication channel. At the cloud side, parts of the feature tensor may be missing due to packet loss. In this paper we propose a method called Content-Adaptive Linear Tensor Completion (CALTeC) to recover the missing feature data. The proposed method is fast, data-adaptive, does not require pre-training, and produces better results than existing methods for tensor data recovery in collaborative intelligence.
Lightweight Compression of Intermediate Neural Network Features for Collaborative Intelligence
May 15, 2021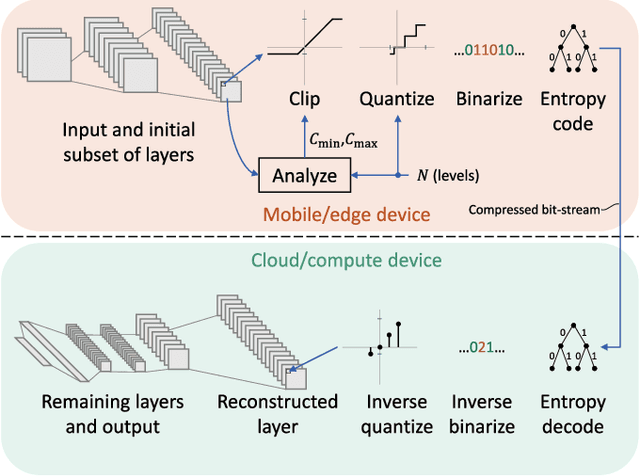
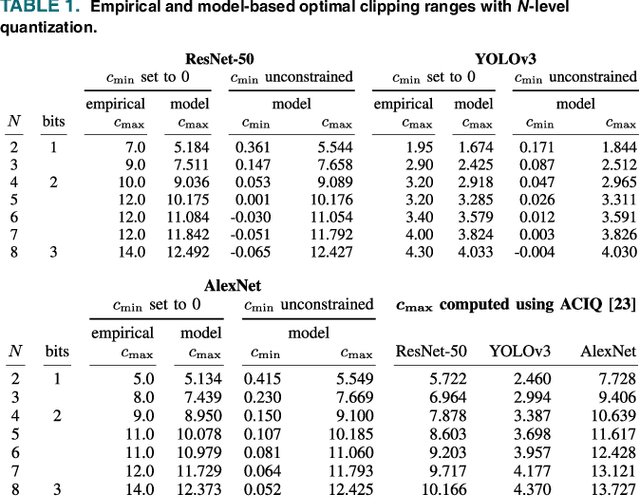
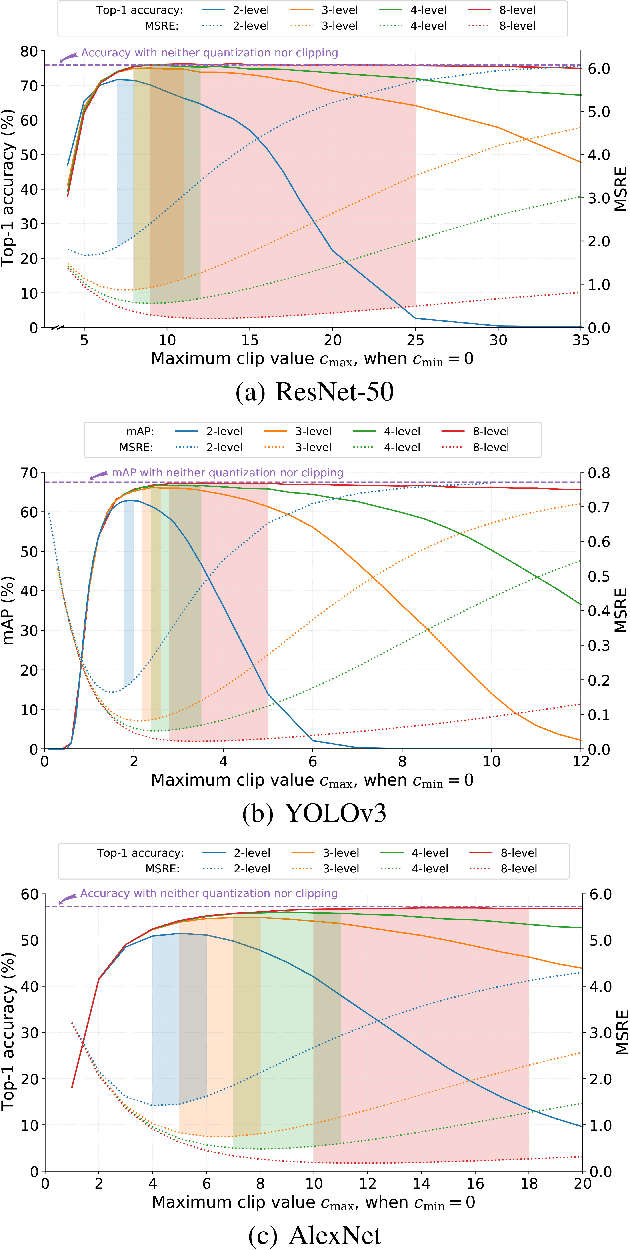
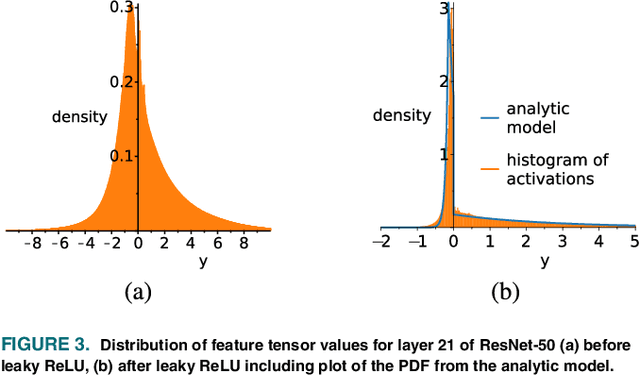
In collaborative intelligence applications, part of a deep neural network (DNN) is deployed on a lightweight device such as a mobile phone or edge device, and the remaining portion of the DNN is processed where more computing resources are available, such as in the cloud. This paper presents a novel lightweight compression technique designed specifically to quantize and compress the features output by the intermediate layer of a split DNN, without requiring any retraining of the network weights. Mathematical models for estimating the clipping and quantization error of ReLU and leaky-ReLU activations at this intermediate layer are developed and used to compute optimal clipping ranges for coarse quantization. We also present a modified entropy-constrained design algorithm for quantizing clipped activations. When applied to popular object-detection and classification DNNs, we were able to compress the 32-bit floating point intermediate activations down to 0.6 to 0.8 bits, while keeping the loss in accuracy to less than 1%. When compared to HEVC, we found that the lightweight codec consistently provided better inference accuracy, by up to 1.3%. The performance and simplicity of this lightweight compression technique makes it an attractive option for coding an intermediate layer of a split neural network for edge/cloud applications.
* Accepted for publication in IEEE Open Journal of Circuits and Systems
Lightweight compression of neural network feature tensors for collaborative intelligence
May 12, 2021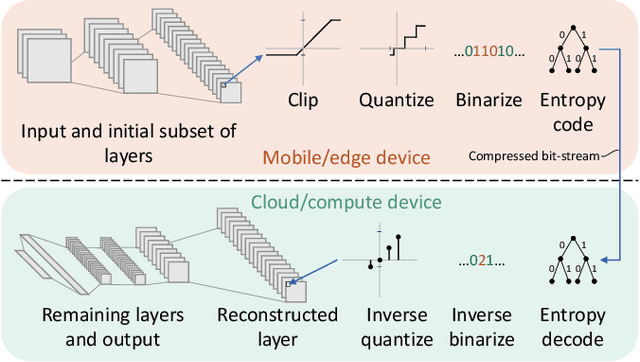
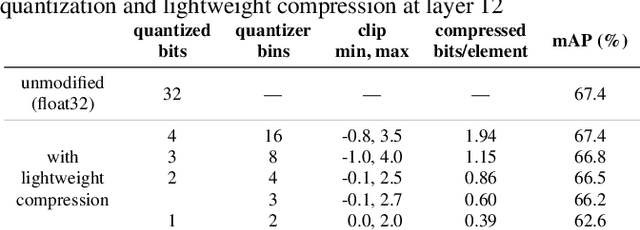
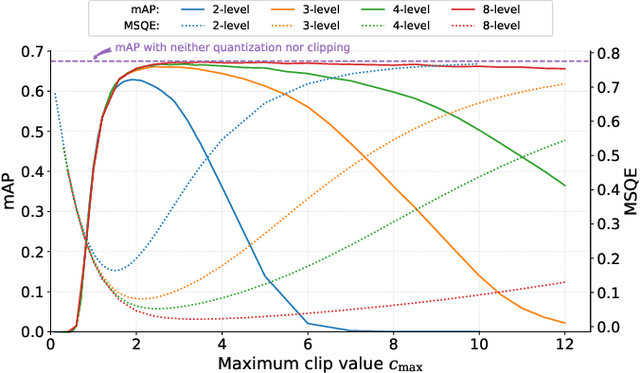
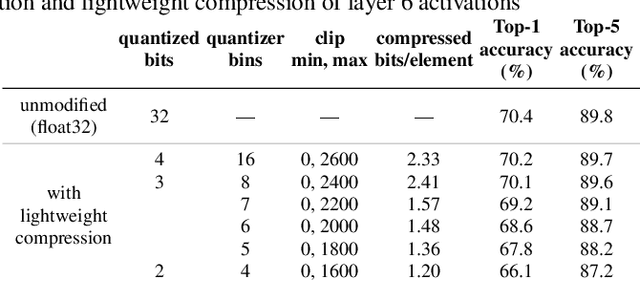
In collaborative intelligence applications, part of a deep neural network (DNN) is deployed on a relatively low-complexity device such as a mobile phone or edge device, and the remainder of the DNN is processed where more computing resources are available, such as in the cloud. This paper presents a novel lightweight compression technique designed specifically to code the activations of a split DNN layer, while having a low complexity suitable for edge devices and not requiring any retraining. We also present a modified entropy-constrained quantizer design algorithm optimized for clipped activations. When applied to popular object-detection and classification DNNs, we were able to compress the 32-bit floating point activations down to 0.6 to 0.8 bits, while keeping the loss in accuracy to less than 1%. When compared to HEVC, we found that the lightweight codec consistently provided better inference accuracy, by up to 1.3%. The performance and simplicity of this lightweight compression technique makes it an attractive option for coding a layer's activations in split neural networks for edge/cloud applications.
* Accepted for publication in IEEE ICME 2020
Back-and-Forth prediction for deep tensor compression
Feb 14, 2020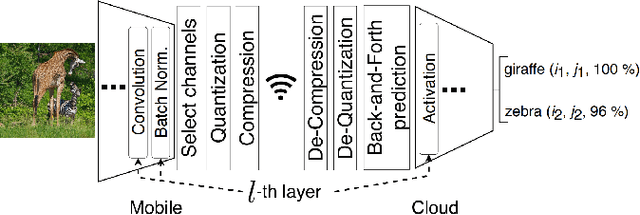
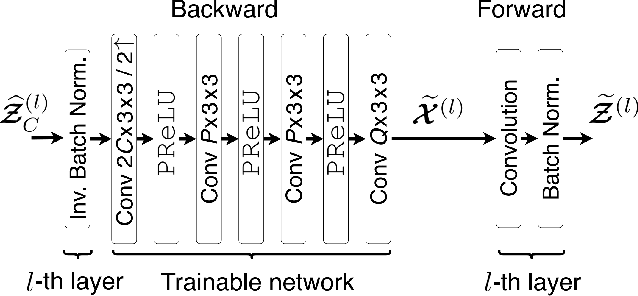
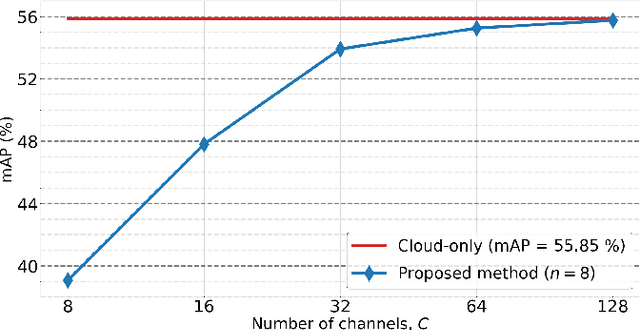
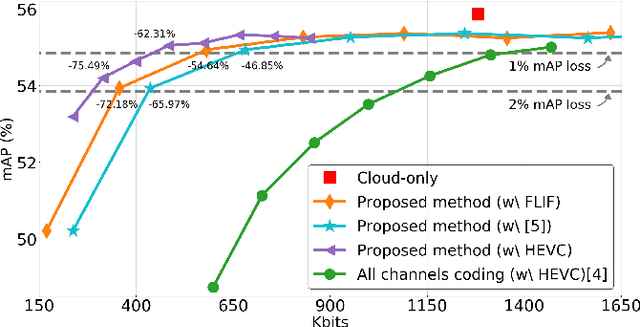
Recent AI applications such as Collaborative Intelligence with neural networks involve transferring deep feature tensors between various computing devices. This necessitates tensor compression in order to optimize the usage of bandwidth-constrained channels between devices. In this paper we present a prediction scheme called Back-and-Forth (BaF) prediction, developed for deep feature tensors, which allows us to dramatically reduce tensor size and improve its compressibility. Our experiments with a state-of-the-art object detector demonstrate that the proposed method allows us to significantly reduce the number of bits needed for compressing feature tensors extracted from deep within the model, with negligible degradation of the detection performance and without requiring any retraining of the network weights. We achieve a 62% and 75% reduction in tensor size while keeping the loss in accuracy of the network to less than 1% and 2%, respectively.