 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Image Coding for Humans and Machines
Paper and Code
Jul 18, 2021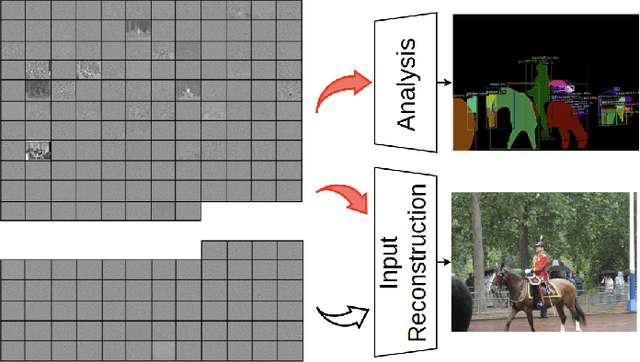
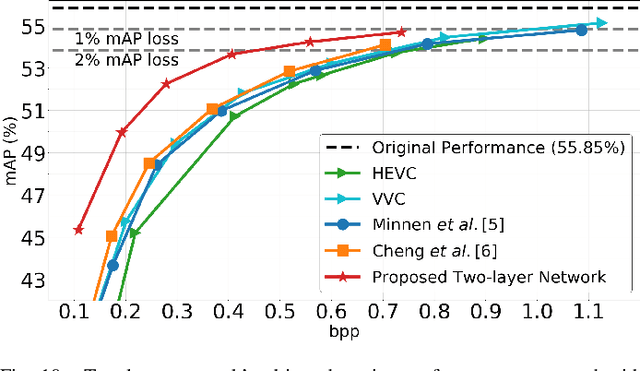
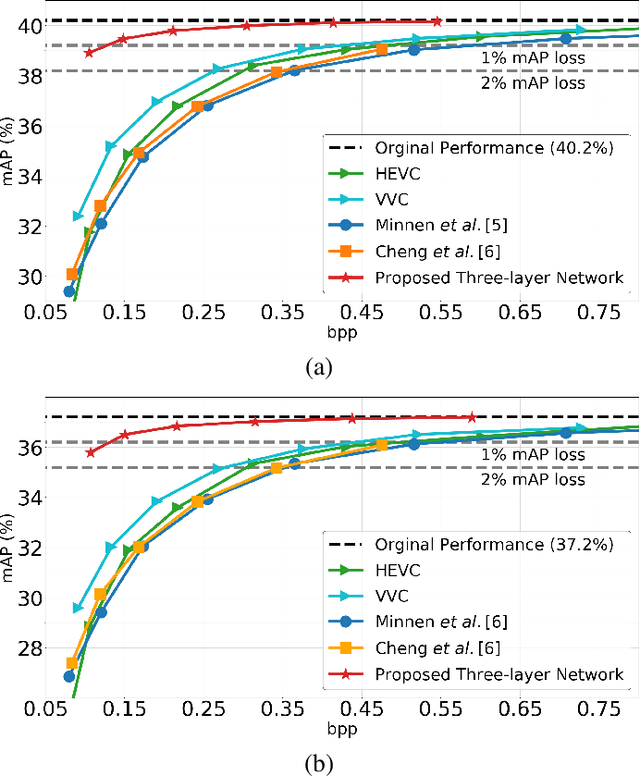
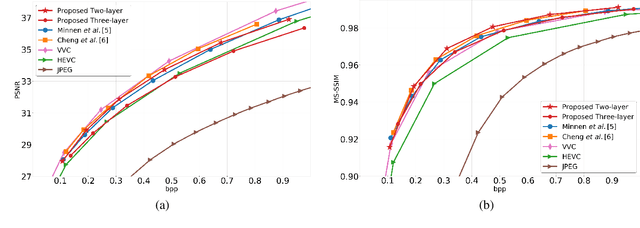
At present, and increasingly so in the future, much of the captured visual content will not be seen by humans. Instead, it will be used for automated machine vision analytics and may require occasional human viewing. Examples of such applications include traffic monitoring, visual surveillance, autonomous navigation, and industrial machine vision. To address such requirements, we develop an end-to-end learned image codec whose latent space is designed to support scalability from simpler to more complicated tasks. The simplest task is assigned to a subset of the latent space (the base layer), while more complicated tasks make use of additional subsets of the latent space, i.e., both the base and enhancement layer(s). For the experiments, we establish a 2-layer and a 3-layer model, each of which offers input reconstruction for human vision, plus machine vision task(s), and compare them with relevant benchmarks. The experiments show that our scalable codecs offer 37%-80% bitrate savings on machine vision tasks compared to best alternatives, while being comparable to state-of-the-art image codecs in terms of input reconstruction.