 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLossy Common Information in a Learnable Gray-Wyner Network
Jan 29, 2026Many computer vision tasks share substantial overlapping information, yet conventional codecs tend to ignore this, leading to redundant and inefficient representations. The Gray-Wyner network, a classical concept from information theory, offers a principled framework for separating common and task-specific information. Inspired by this idea, we develop a learnable three-channel codec that disentangles shared information from task-specific details across multiple vision tasks. We characterize the limits of this approach through the notion of lossy common information, and propose an optimization objective that balances inherent tradeoffs in learning such representations. Through comparisons of three codec architectures on two-task scenarios spanning six vision benchmarks, we demonstrate that our approach substantially reduces redundancy and consistently outperforms independent coding. These results highlight the practical value of revisiting Gray-Wyner theory in modern machine learning contexts, bridging classic information theory with task-driven representation learning.
Rate-Distortion Optimization for Transformer Inference
Jan 29, 2026Transformers achieve superior performance on many tasks, but impose heavy compute and memory requirements during inference. This inference can be made more efficient by partitioning the process across multiple devices, which, in turn, requires compressing its intermediate representations. In this work, we introduce a principled rate-distortion-based framework for lossy compression that learns compact encodings that explicitly trade off bitrate against accuracy. Experiments on language benchmarks show that the proposed codec achieves substantial savings with improved accuracy in some cases, outperforming more complex baseline methods. We characterize and analyze the rate-distortion performance of transformers, offering a unified lens for understanding performance in representation coding. This formulation extends information-theoretic concepts to define the gap between rate and entropy, and derive some of its bounds. We further develop probably approximately correct (PAC)-style bounds for estimating this gap. For different architectures and tasks, we empirically demonstrate that their rates are driven by these bounds, adding to the explainability of the formulation.
Base Layer Efficiency in Scalable Human-Machine Coding
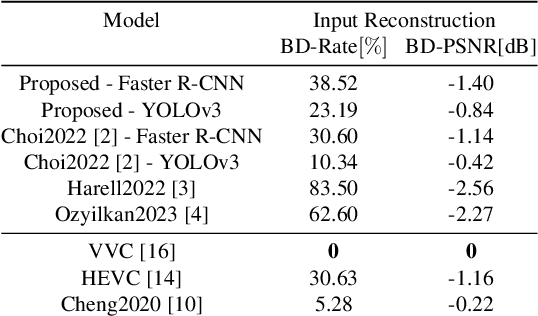
Jul 05, 2023A basic premise in scalable human-machine coding is that the base layer is intended for automated machine analysis and is therefore more compressible than the same content would be for human viewing. Use cases for such coding include video surveillance and traffic monitoring, where the majority of the content will never be seen by humans. Therefore, base layer efficiency is of paramount importance because the system would most frequently operate at the base-layer rate. In this paper, we analyze the coding efficiency of the base layer in a state-of-the-art scalable human-machine image codec, and show that it can be improved. In particular, we demonstrate that gains of 20-40% in BD-Rate compared to the currently best results on object detection and instance segmentation are possible.
Rate-Distortion Theory in Coding for Machines and its Application
May 26, 2023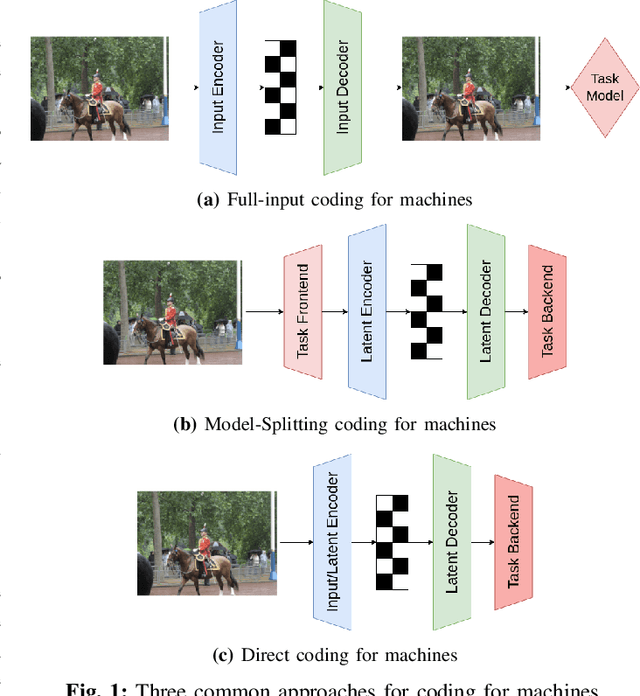
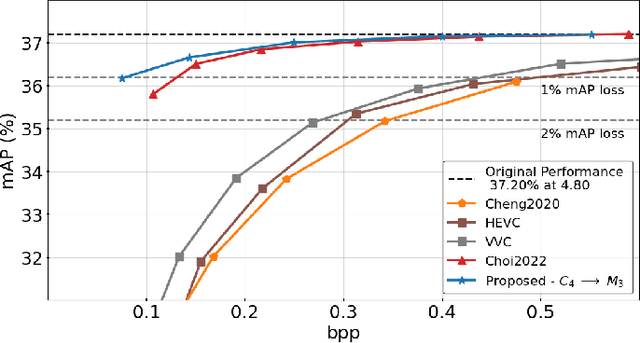
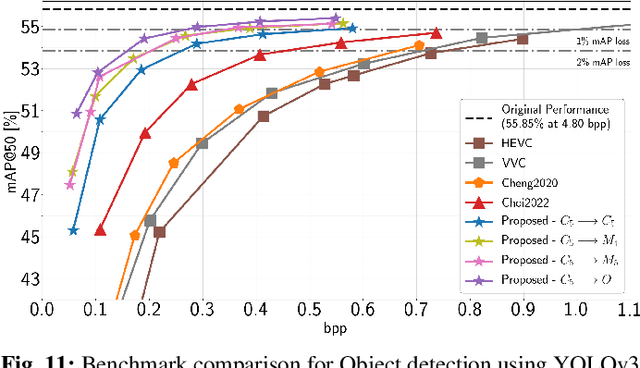
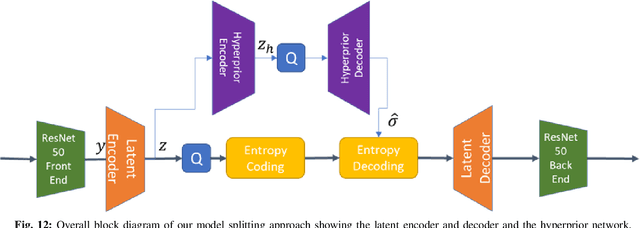
Recent years have seen a tremendous growth in both the capability and popularity of automatic machine analysis of images and video. As a result, a growing need for efficient compression methods optimized for machine vision, rather than human vision, has emerged. To meet this growing demand, several methods have been developed for image and video coding for machines. Unfortunately, while there is a substantial body of knowledge regarding rate-distortion theory for human vision, the same cannot be said of machine analysis. In this paper, we extend the current rate-distortion theory for machines, providing insight into important design considerations of machine-vision codecs. We then utilize this newfound understanding to improve several methods for learnable image coding for machines. Our proposed methods achieve state-of-the-art rate-distortion performance on several computer vision tasks such as classification, instance segmentation, and object detection.
VVC+M: Plug and Play Scalable Image Coding for Humans and Machines
May 17, 2023


Compression for machines is an emerging field, where inputs are encoded while optimizing the performance of downstream automated analysis. In scalable coding for humans and machines, the compressed representation used for machines is further utilized to enable input reconstruction. Often performed by jointly optimizing the compression scheme for both machine task and human perception, this results in sub-optimal rate-distortion (RD) performance for the machine side. We focus on the case of images, proposing to utilize the pre-existing residual coding capabilities of video codecs such as VVC to create a scalable codec from any image compression for machines (ICM) scheme. Using our approach we improve an existing scalable codec to achieve superior RD performance on the machine task, while remaining competitive for human perception. Moreover, our approach can be trained post-hoc for any given ICM scheme, and without creating a coupling between the quality of the machine analysis and human vision.
Conditional and Residual Methods in Scalable Coding for Humans and Machines
May 04, 2023We present methods for conditional and residual coding in the context of scalable coding for humans and machines. Our focus is on optimizing the rate-distortion performance of the reconstruction task using the information available in the computer vision task. We include an information analysis of both approaches to provide baselines and also propose an entropy model suitable for conditional coding with increased modelling capacity and similar tractability as previous work. We apply these methods to image reconstruction, using, in one instance, representations created for semantic segmentation on the Cityscapes dataset, and in another instance, representations created for object detection on the COCO dataset. In both experiments, we obtain similar performance between the conditional and residual methods, with the resulting rate-distortion curves contained within our baselines.
Rate-Distortion in Image Coding for Machines
Sep 21, 2022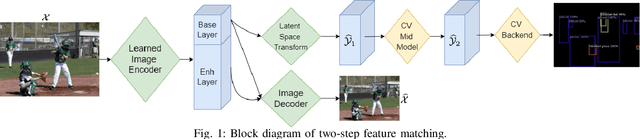
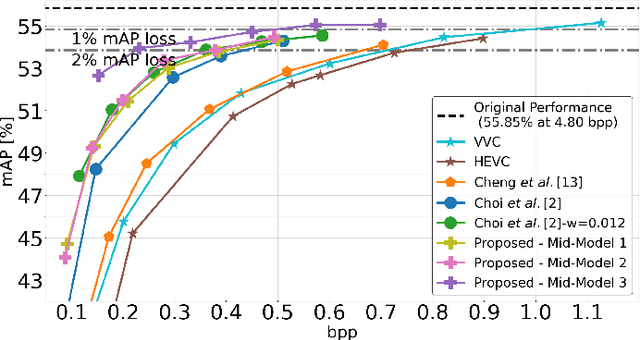
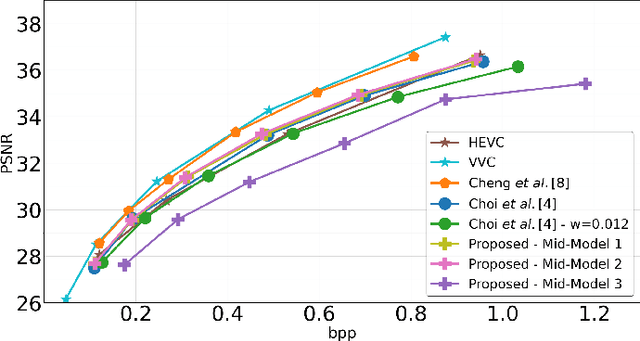
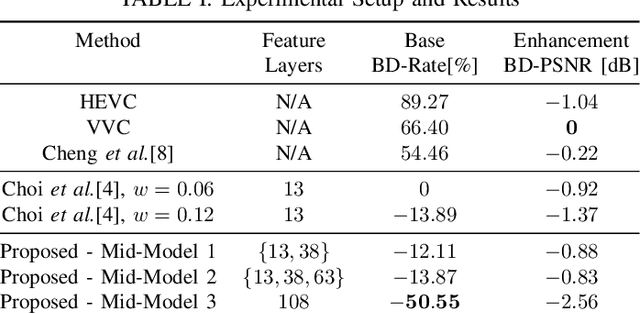
In recent years, there has been a sharp increase in transmission of images to remote servers specifically for the purpose of computer vision. In many applications, such as surveillance, images are mostly transmitted for automated analysis, and rarely seen by humans. Using traditional compression for this scenario has been shown to be inefficient in terms of bit-rate, likely due to the focus on human based distortion metrics. Thus, it is important to create specific image coding methods for joint use by humans and machines. One way to create the machine side of such a codec is to perform feature matching of some intermediate layer in a Deep Neural Network performing the machine task. In this work, we explore the effects of the layer choice used in training a learnable codec for humans and machines. We prove, using the data processing inequality, that matching features from deeper layers is preferable in the sense of rate-distortion. Next, we confirm our findings empirically by re-training an existing model for scalable human-machine coding. In our experiments we show the trade-off between the human and machine sides of such a scalable model, and discuss the benefit of using deeper layers for training in that regard.
Does Video Compression Impact Tracking Accuracy?
Feb 02, 2022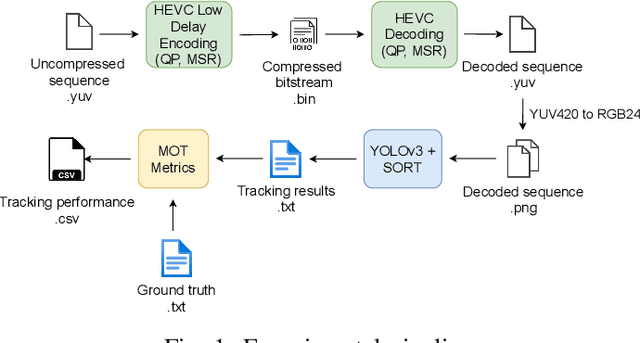
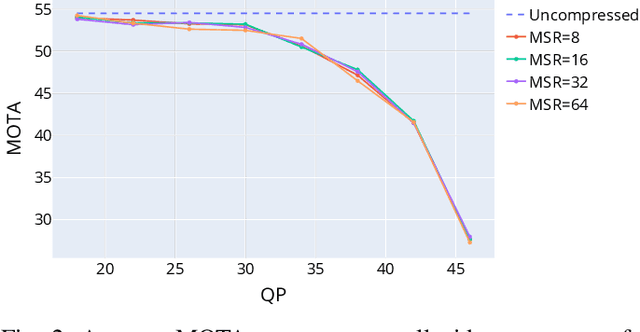
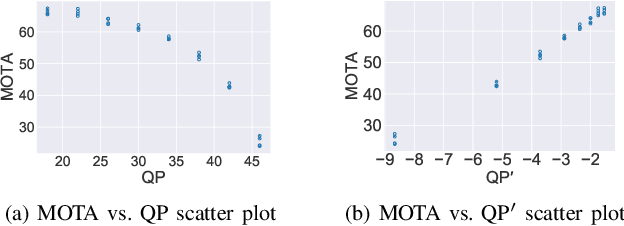
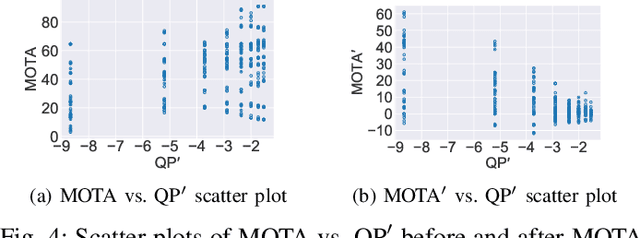
Everyone "knows" that compressing a video will degrade the accuracy of object tracking. Yet, a literature search on this topic reveals that there is very little documented evidence for this presumed fact. Part of the reason is that, until recently, there were no object tracking datasets for uncompressed video, which made studying the effects of compression on tracking accuracy difficult. In this paper, using a recently published dataset that contains tracking annotations for uncompressed videos, we examined the degradation of tracking accuracy due to video compression using rigorous statistical methods. Specifically, we examined the impact of quantization parameter (QP) and motion search range (MSR) on Multiple Object Tracking Accuracy (MOTA). The results show that QP impacts MOTA at the 95% confidence level, while there is insufficient evidence to claim that MSR impacts MOTA. Moreover, regression analysis allows us to derive a quantitative relationship between MOTA and QP for the specific tracker used in the experiments.
PowerGAN: Synthesizing Appliance Power Signatures Using Generative Adversarial Networks
Jul 20, 2020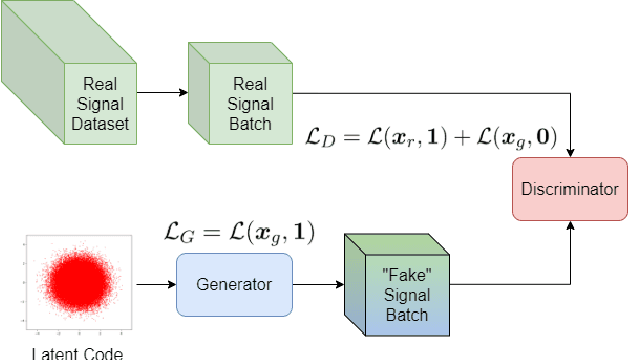
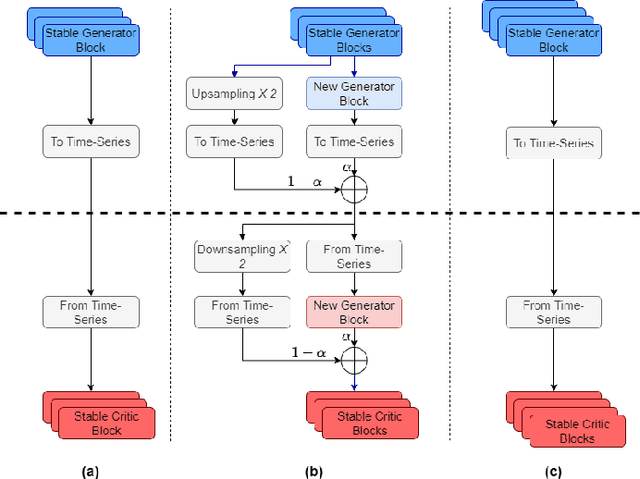
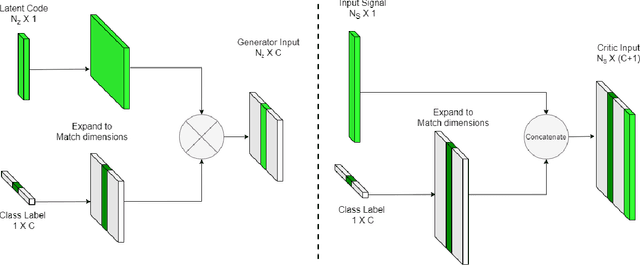
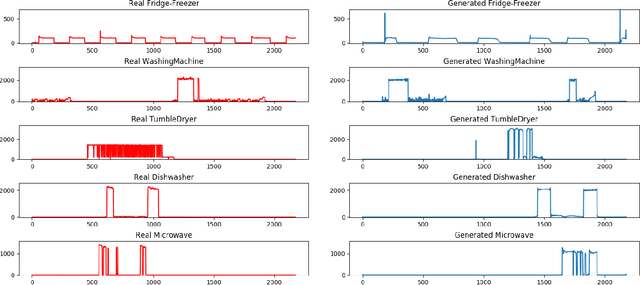
Non-intrusive load monitoring (NILM) allows users and energy providers to gain insight into home appliance electricity consumption using only the building's smart meter. Most current techniques for NILM are trained using significant amounts of labeled appliances power data. The collection of such data is challenging, making data a major bottleneck in creating well generalizing NILM solutions. To help mitigate the data limitations, we present the first truly synthetic appliance power signature generator. Our solution, PowerGAN, is based on conditional, progressively growing, 1-D Wasserstein generative adversarial network (GAN). Using PowerGAN, we are able to synthesise truly random and realistic appliance power data signatures. We evaluate the samples generated by PowerGAN in a qualitative way as well as numerically by using traditional GAN evaluation methods such as the Inception score.
Towards Automated Swimming Analytics Using Deep Neural Networks
Jan 13, 2020
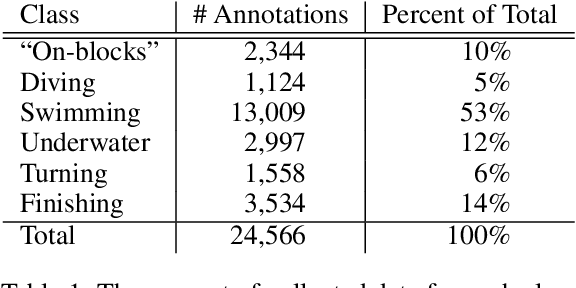


Methods for creating a system to automate the collection of swimming analytics on a pool-wide scale are considered in this paper. There has not been much work on swimmer tracking or the creation of a swimmer database for machine learning purposes. Consequently, methods for collecting swimmer data from videos of swim competitions are explored and analyzed. The result is a guide to the creation of a comprehensive collection of swimming data suitable for training swimmer detection and tracking systems. With this database in place, systems can then be created to automate the collection of swimming analytics.