 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSituation Monitor: Diversity-Driven Zero-Shot Out-of-Distribution Detection using Budding Ensemble Architecture for Object Detection
Jun 05, 2024We introduce Situation Monitor, a novel zero-shot Out-of-Distribution (OOD) detection approach for transformer-based object detection models to enhance reliability in safety-critical machine learning applications such as autonomous driving. The Situation Monitor utilizes the Diversity-based Budding Ensemble Architecture (DBEA) and increases the OOD performance by integrating a diversity loss into the training process on top of the budding ensemble architecture, detecting Far-OOD samples and minimizing false positives on Near-OOD samples. Moreover, utilizing the resulting DBEA increases the model's OOD performance and improves the calibration of confidence scores, particularly concerning the intersection over union of the detected objects. The DBEA model achieves these advancements with a 14% reduction in trainable parameters compared to the vanilla model. This signifies a substantial improvement in efficiency without compromising the model's ability to detect OOD instances and calibrate the confidence scores accurately.
Global Clipper: Enhancing Safety and Reliability of Transformer-based Object Detection Models
Jun 05, 2024As transformer-based object detection models progress, their impact in critical sectors like autonomous vehicles and aviation is expected to grow. Soft errors causing bit flips during inference have significantly impacted DNN performance, altering predictions. Traditional range restriction solutions for CNNs fall short for transformers. This study introduces the Global Clipper and Global Hybrid Clipper, effective mitigation strategies specifically designed for transformer-based models. It significantly enhances their resilience to soft errors and reduces faulty inferences to ~ 0\%. We also detail extensive testing across over 64 scenarios involving two transformer models (DINO-DETR and Lite-DETR) and two CNN models (YOLOv3 and SSD) using three datasets, totalling approximately 3.3 million inferences, to assess model robustness comprehensively. Moreover, the paper explores unique aspects of attention blocks in transformers and their operational differences from CNNs.
BEA: Revisiting anchor-based object detection DNN using Budding Ensemble Architecture
Sep 19, 2023



This paper introduces the Budding Ensemble Architecture (BEA), a novel reduced ensemble architecture for anchor-based object detection models. Object detection models are crucial in vision-based tasks, particularly in autonomous systems. They should provide precise bounding box detections while also calibrating their predicted confidence scores, leading to higher-quality uncertainty estimates. However, current models may make erroneous decisions due to false positives receiving high scores or true positives being discarded due to low scores. BEA aims to address these issues. The proposed loss functions in BEA improve the confidence score calibration and lower the uncertainty error, which results in a better distinction of true and false positives and, eventually, higher accuracy of the object detection models. Both Base-YOLOv3 and SSD models were enhanced using the BEA method and its proposed loss functions. The BEA on Base-YOLOv3 trained on the KITTI dataset results in a 6% and 3.7% increase in mAP and AP50, respectively. Utilizing a well-balanced uncertainty estimation threshold to discard samples in real-time even leads to a 9.6% higher AP50 than its base model. This is attributed to a 40% increase in the area under the AP50-based retention curve used to measure the quality of calibration of confidence scores. Furthermore, BEA-YOLOV3 trained on KITTI provides superior out-of-distribution detection on Citypersons, BDD100K, and COCO datasets compared to the ensembles and vanilla models of YOLOv3 and Gaussian-YOLOv3.
VALERIE22 -- A photorealistic, richly metadata annotated dataset of urban environments
Aug 18, 2023The VALERIE tool pipeline is a synthetic data generator developed with the goal to contribute to the understanding of domain-specific factors that influence perception performance of DNNs (deep neural networks). This work was carried out under the German research project KI Absicherung in order to develop a methodology for the validation of DNNs in the context of pedestrian detection in urban environments for automated driving. The VALERIE22 dataset was generated with the VALERIE procedural tools pipeline providing a photorealistic sensor simulation rendered from automatically synthesized scenes. The dataset provides a uniquely rich set of metadata, allowing extraction of specific scene and semantic features (like pixel-accurate occlusion rates, positions in the scene and distance + angle to the camera). This enables a multitude of possible tests on the data and we hope to stimulate research on understanding performance of DNNs. Based on performance metric a comparison with several other publicly available datasets is provided, demonstrating that VALERIE22 is one of best performing synthetic datasets currently available in the open domain.
Towards Machine Learning-Based Optimal HAS
Aug 24, 2018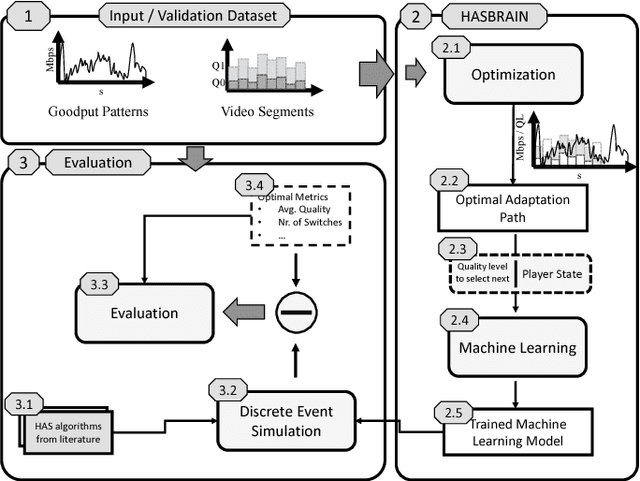
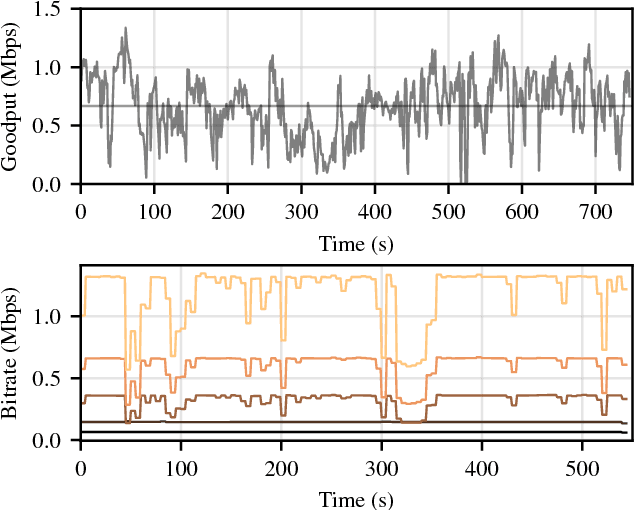
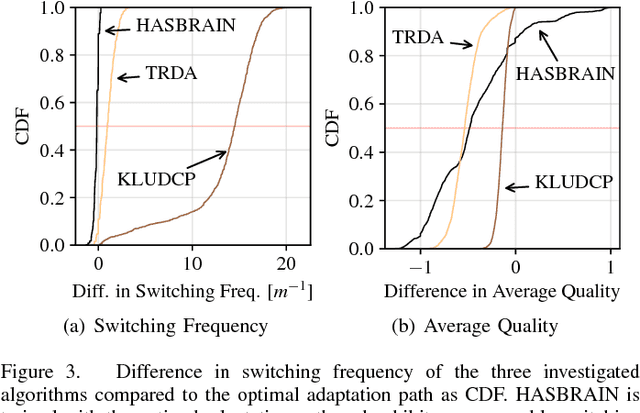
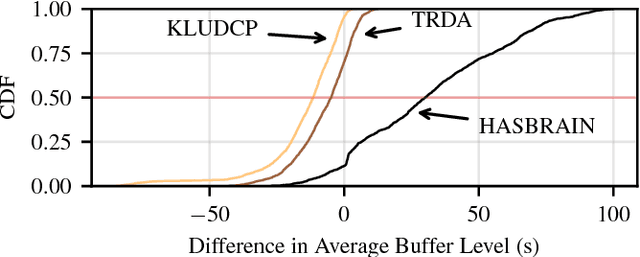
Mobile video consumption is increasing and sophisticated video quality adaptation strategies are required to deal with mobile throughput fluctuations. These adaptation strategies have to keep the switching frequency low, the average quality high and prevent stalling occurrences to ensure customer satisfaction. This paper proposes a novel methodology for the design of machine learning-based adaptation logics named HASBRAIN. Furthermore, the performance of a trained neural network against two algorithms from the literature is evaluated. We first use a modified existing optimization formulation to calculate optimal adaptation paths with a minimum number of quality switches for a wide range of videos and for challenging mobile throughput patterns. Afterwards we use the resulting optimal adaptation paths to train and compare different machine learning models. The evaluation shows that an artificial neural network-based model can reach a high average quality with a low number of switches in the mobile scenario. The proposed methodology is general enough to be extended for further designs of machine learning-based algorithms and the provided model can be deployed in on-demand streaming scenarios or be further refined using reward-based mechanisms such as reinforcement learning. All tools, models and datasets created during the work are provided as open-source software.