 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Automated End-to-End Open-Source Software for High-Quality Text-to-Speech Dataset Generation
Paper and Code
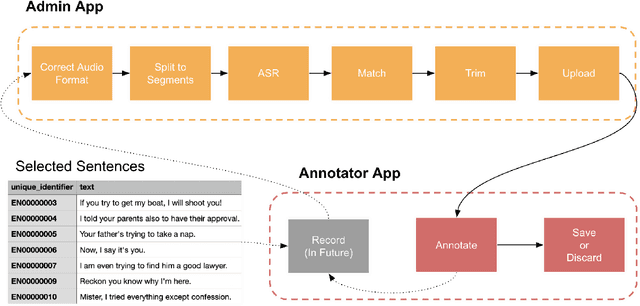


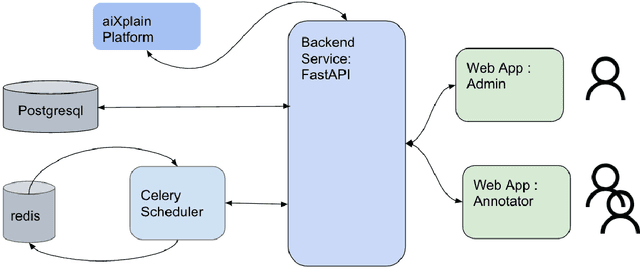
Data availability is crucial for advancing artificial intelligence applications, including voice-based technologies. As content creation, particularly in social media, experiences increasing demand, translation and text-to-speech (TTS) technologies have become essential tools. Notably, the performance of these TTS technologies is highly dependent on the quality of the training data, emphasizing the mutual dependence of data availability and technological progress. This paper introduces an end-to-end tool to generate high-quality datasets for text-to-speech (TTS) models to address this critical need for high-quality data. The contributions of this work are manifold and include: the integration of language-specific phoneme distribution into sample selection, automation of the recording process, automated and human-in-the-loop quality assurance of recordings, and processing of recordings to meet specified formats. The proposed application aims to streamline the dataset creation process for TTS models through these features, thereby facilitating advancements in voice-based technologies.