 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Automated End-to-End Open-Source Software for High-Quality Text-to-Speech Dataset Generation
Feb 26, 2024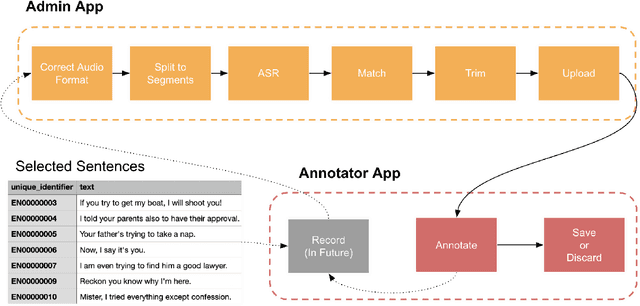


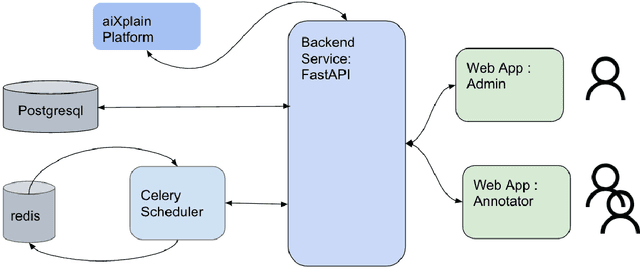
Data availability is crucial for advancing artificial intelligence applications, including voice-based technologies. As content creation, particularly in social media, experiences increasing demand, translation and text-to-speech (TTS) technologies have become essential tools. Notably, the performance of these TTS technologies is highly dependent on the quality of the training data, emphasizing the mutual dependence of data availability and technological progress. This paper introduces an end-to-end tool to generate high-quality datasets for text-to-speech (TTS) models to address this critical need for high-quality data. The contributions of this work are manifold and include: the integration of language-specific phoneme distribution into sample selection, automation of the recording process, automated and human-in-the-loop quality assurance of recordings, and processing of recordings to meet specified formats. The proposed application aims to streamline the dataset creation process for TTS models through these features, thereby facilitating advancements in voice-based technologies.
Bayesian Structured Prediction Using Gaussian Processes
Jul 15, 2013
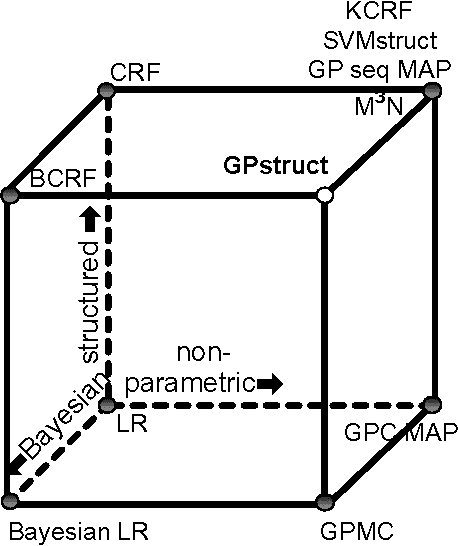
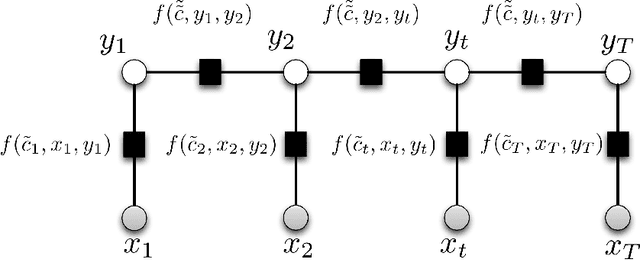
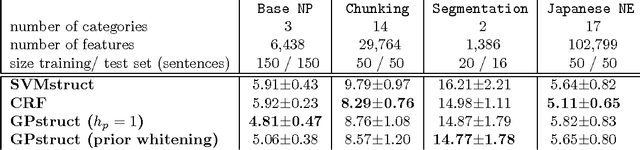
We introduce a conceptually novel structured prediction model, GPstruct, which is kernelized, non-parametric and Bayesian, by design. We motivate the model with respect to existing approaches, among others, conditional random fields (CRFs), maximum margin Markov networks (M3N), and structured support vector machines (SVMstruct), which embody only a subset of its properties. We present an inference procedure based on Markov Chain Monte Carlo. The framework can be instantiated for a wide range of structured objects such as linear chains, trees, grids, and other general graphs. As a proof of concept, the model is benchmarked on several natural language processing tasks and a video gesture segmentation task involving a linear chain structure. We show prediction accuracies for GPstruct which are comparable to or exceeding those of CRFs and SVMstruct.