 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMediaMind: Revolutionizing Media Monitoring using Agentification
Feb 18, 2025In an era of rapid technological advancements, agentification of software tools has emerged as a critical innovation, enabling systems to function autonomously and adaptively. This paper introduces MediaMind as a case study to demonstrate the agentification process, highlighting how existing software can be transformed into intelligent agents capable of independent decision-making and dynamic interaction. Developed by aiXplain, MediaMind leverages agent-based architecture to autonomously monitor, analyze, and provide insights from multilingual media content in real time. The focus of this paper is on the technical methodologies and design principles behind agentifying MediaMind, showcasing how agentification enhances adaptability, efficiency, and responsiveness. Through detailed case studies and practical examples, we illustrate how the agentification of MediaMind empowers organizations to streamline workflows, optimize decision-making, and respond to evolving trends. This work underscores the broader potential of agentification to revolutionize software tools across various domains.
ChamaleonLLM: Batch-Aware Dynamic Low-Rank Adaptation via Inference-Time Clusters
Feb 09, 2025
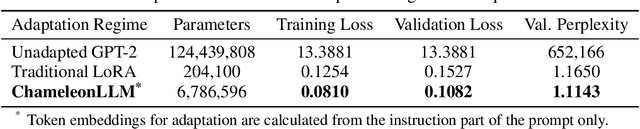
Recent advances in large language models (LLMs) have shown remarkable performance across diverse tasks. However, these models are typically deployed with fixed weights, which limits their ability to adapt dynamically to the variability inherent in real-world data during inference. This paper introduces ChamaleonLLM, a novel framework that enables inference-time adaptation of LLMs by leveraging batch-aware clustering and on-the-fly generation of low-rank updates. Unlike traditional fine-tuning approaches such as Low-Rank Adaptation (LoRA) or methods that rely on a fixed set of pre-learned uniforms (changeable masks), our method dynamically generates adaptive modifications to the decoder weights based on the aggregated statistics of clustered batches. By intelligently grouping similar inputs and computing context-aware low-rank updates via a hyper-network, ChamaleonLLM achieves significant performance gains, outperforming conventional LoRA methods while eliminating the overhead of maintaining multiple expert models. Our experiments highlight the potential of our approach to serve as a versatile and highly adaptive solution for language model inference. ChamaleonLLM is open-sourced to ensure the reproducibility of our experiments: https://anonymous.4open.science/r/ChamaleonLLM/
A Multi-AI Agent System for Autonomous Optimization of Agentic AI Solutions via Iterative Refinement and LLM-Driven Feedback Loops
Dec 22, 2024



Agentic AI systems use specialized agents to handle tasks within complex workflows, enabling automation and efficiency. However, optimizing these systems often requires labor-intensive, manual adjustments to refine roles, tasks, and interactions. This paper introduces a framework for autonomously optimizing Agentic AI solutions across industries, such as NLP-driven enterprise applications. The system employs agents for Refinement, Execution, Evaluation, Modification, and Documentation, leveraging iterative feedback loops powered by an LLM (Llama 3.2-3B). The framework achieves optimal performance without human input by autonomously generating and testing hypotheses to improve system configurations. This approach enhances scalability and adaptability, offering a robust solution for real-world applications in dynamic environments. Case studies across diverse domains illustrate the transformative impact of this framework, showcasing significant improvements in output quality, relevance, and actionability. All data for these case studies, including original and evolved agent codes, along with their outputs, are here: https://anonymous.4open.science/r/evolver-1D11/
Bel Esprit: Multi-Agent Framework for Building AI Model Pipelines
Dec 19, 2024


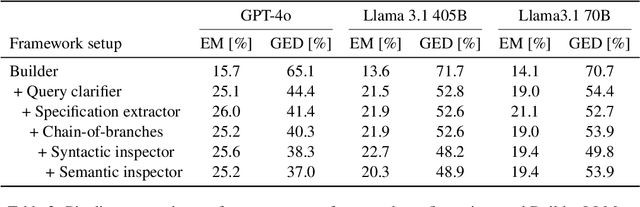
As the demand for artificial intelligence (AI) grows to address complex real-world tasks, single models are often insufficient, requiring the integration of multiple models into pipelines. This paper introduces Bel Esprit, a conversational agent designed to construct AI model pipelines based on user-defined requirements. Bel Esprit employs a multi-agent framework where subagents collaborate to clarify requirements, build, validate, and populate pipelines with appropriate models. We demonstrate the effectiveness of this framework in generating pipelines from ambiguous user queries, using both human-curated and synthetic data. A detailed error analysis highlights ongoing challenges in pipeline construction. Bel Esprit is available for a free trial at https://belesprit.aixplain.com.
Creating Arabic LLM Prompts at Scale
Aug 12, 2024
The debut of chatGPT and BARD has popularized instruction following text generation using LLMs, where a user can interrogate an LLM using natural language requests and obtain natural language answers that matches their requests. Training LLMs to respond in this manner requires a large number of worked out examples of user requests (aka prompts) with corresponding gold responses. In this paper, we introduce two methods for creating such prompts for Arabic cheaply and quickly. The first methods entails automatically translating existing prompt datasets from English, such as PromptSource and Super-NaturalInstructions, and then using machine translation quality estimation to retain high quality translations only. The second method involves creating natural language prompts on top of existing Arabic NLP datasets. Using these two methods we were able to create more than 67.4 million Arabic prompts that cover a variety of tasks including summarization, headline generation, grammar checking, open/closed question answering, creative writing, etc. We show that fine tuning an open 7 billion parameter large language model, namely base Qwen2 7B, enables it to outperform a state-of-the-art 70 billion parameter instruction tuned model, namely Llama3 70B, in handling Arabic prompts.
EvolveMT: an Ensemble MT Engine Improving Itself with Usage Only
Jun 20, 2023This paper presents EvolveMT for efficiently combining multiple machine translation (MT) engines. The proposed system selects the output from a single engine for each segment by utilizing online learning techniques to predict the most suitable system for every translation request. A neural quality estimation metric supervises the method without requiring reference translations. The online learning capability of this system allows for dynamic adaptation to alterations in the domain or machine translation engines, thereby obviating the necessity for additional training. EvolveMT selects a subset of translation engines to be called based on the source sentence features. The degree of exploration is configurable according to the desired quality-cost trade-off. Results from custom datasets demonstrate that EvolveMT achieves similar translation accuracy at a lower cost than selecting the best translation of each segment from all translations using an MT quality estimator. To our knowledge, EvolveMT is the first meta MT system that adapts itself after deployment to incoming translation requests from the production environment without needing costly retraining on human feedback.
Efficient Machine Translation Corpus Generation
Jun 20, 2023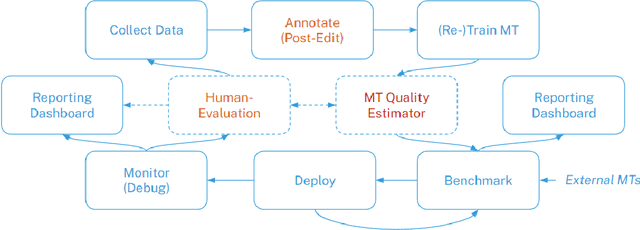
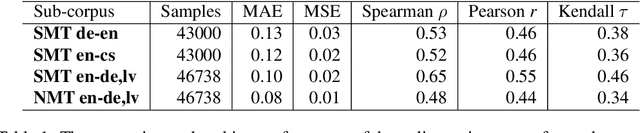
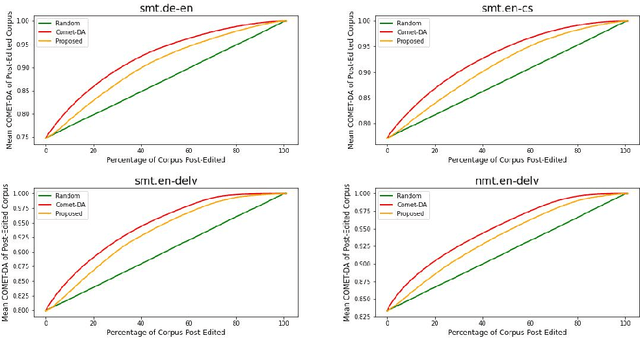
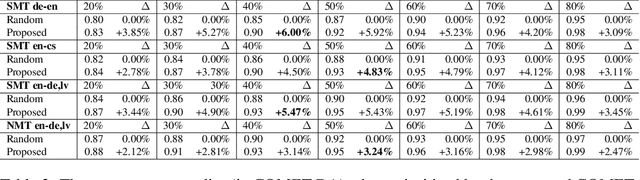
This paper proposes an efficient and semi-automated method for human-in-the-loop post-editing for machine translation (MT) corpus generation. The method is based on online training of a custom MT quality estimation metric on-the-fly as linguists perform post-edits. The online estimator is used to prioritize worse hypotheses for post-editing, and auto-close best hypotheses without post-editing. This way, significant improvements can be achieved in the resulting quality of post-edits at a lower cost due to reduced human involvement. The trained estimator can also provide an online sanity check mechanism for post-edits and remove the need for additional linguists to review them or work on the same hypotheses. In this paper, the effect of prioritizing with the proposed method on the resulting MT corpus quality is presented versus scheduling hypotheses randomly. As demonstrated by experiments, the proposed method improves the lifecycle of MT models by focusing the linguist effort on production samples and hypotheses, which matter most for expanding MT corpora to be used for re-training them.
From Speech-to-Speech Translation to Automatic Dubbing
Feb 02, 2020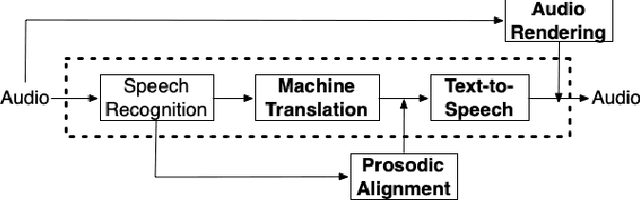

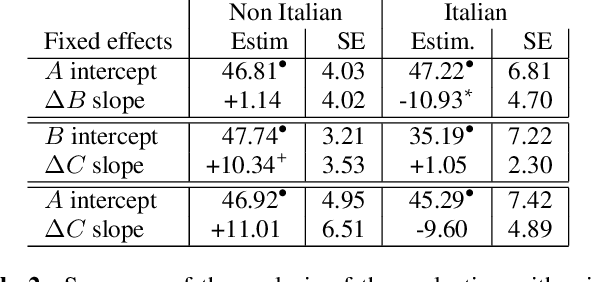
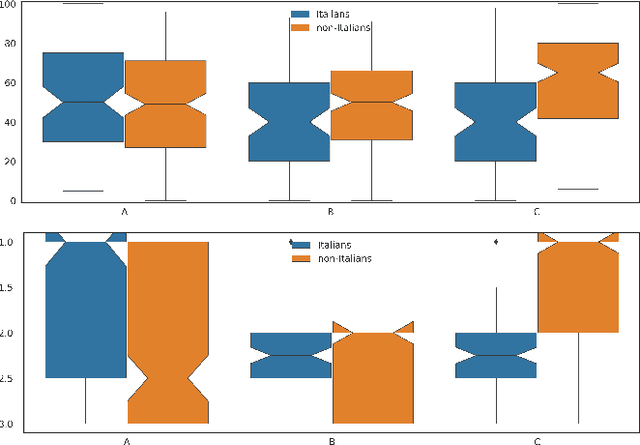
We present enhancements to a speech-to-speech translation pipeline in order to perform automatic dubbing. Our architecture features neural machine translation generating output of preferred length, prosodic alignment of the translation with the original speech segments, neural text-to-speech with fine tuning of the duration of each utterance, and, finally, audio rendering to enriches text-to-speech output with background noise and reverberation extracted from the original audio. We report on a subjective evaluation of automatic dubbing of excerpts of TED Talks from English into Italian, which measures the perceived naturalness of automatic dubbing and the relative importance of each proposed enhancement.