 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBel Esprit: Multi-Agent Framework for Building AI Model Pipelines
Dec 19, 2024


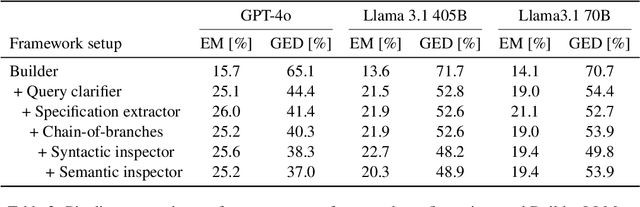
As the demand for artificial intelligence (AI) grows to address complex real-world tasks, single models are often insufficient, requiring the integration of multiple models into pipelines. This paper introduces Bel Esprit, a conversational agent designed to construct AI model pipelines based on user-defined requirements. Bel Esprit employs a multi-agent framework where subagents collaborate to clarify requirements, build, validate, and populate pipelines with appropriate models. We demonstrate the effectiveness of this framework in generating pipelines from ambiguous user queries, using both human-curated and synthetic data. A detailed error analysis highlights ongoing challenges in pipeline construction. Bel Esprit is available for a free trial at https://belesprit.aixplain.com.
Word-Level ASR Quality Estimation for Efficient Corpus Sampling and Post-Editing through Analyzing Attentions of a Reference-Free Metric
Feb 02, 2024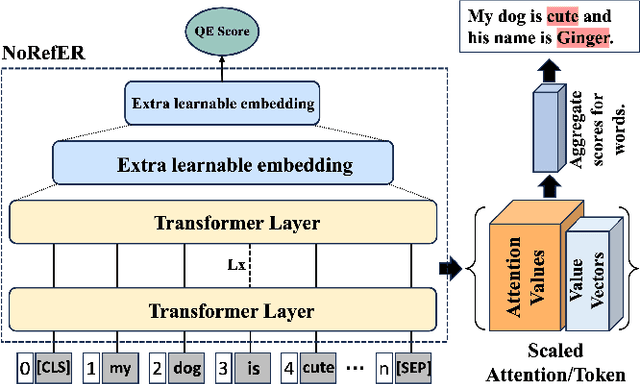

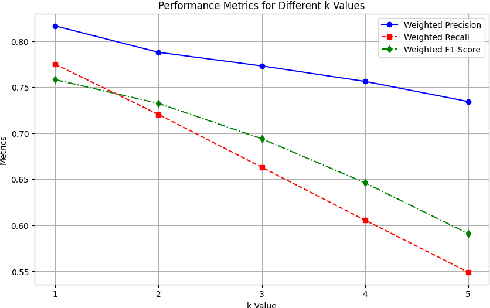
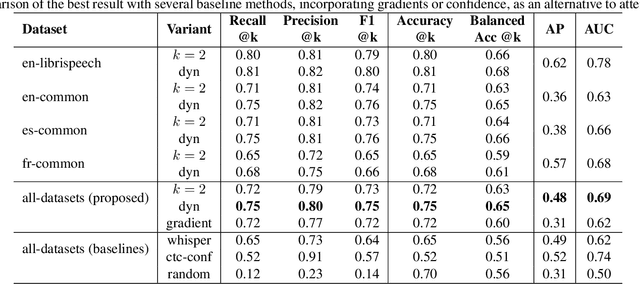
In the realm of automatic speech recognition (ASR), the quest for models that not only perform with high accuracy but also offer transparency in their decision-making processes is crucial. The potential of quality estimation (QE) metrics is introduced and evaluated as a novel tool to enhance explainable artificial intelligence (XAI) in ASR systems. Through experiments and analyses, the capabilities of the NoRefER (No Reference Error Rate) metric are explored in identifying word-level errors to aid post-editors in refining ASR hypotheses. The investigation also extends to the utility of NoRefER in the corpus-building process, demonstrating its effectiveness in augmenting datasets with insightful annotations. The diagnostic aspects of NoRefER are examined, revealing its ability to provide valuable insights into model behaviors and decision patterns. This has proven beneficial for prioritizing hypotheses in post-editing workflows and fine-tuning ASR models. The findings suggest that NoRefER is not merely a tool for error detection but also a comprehensive framework for enhancing ASR systems' transparency, efficiency, and effectiveness. To ensure the reproducibility of the results, all source codes of this study are made publicly available.
A Reference-less Quality Metric for Automatic Speech Recognition via Contrastive-Learning of a Multi-Language Model with Self-Supervision
Jun 21, 2023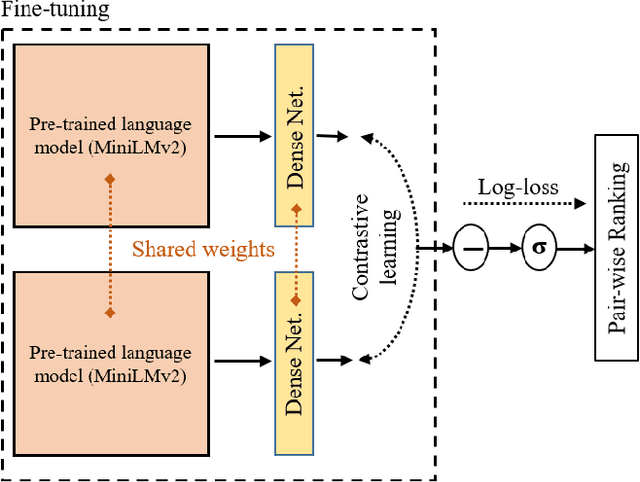
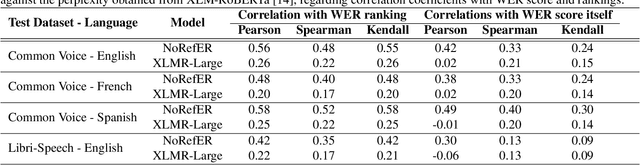
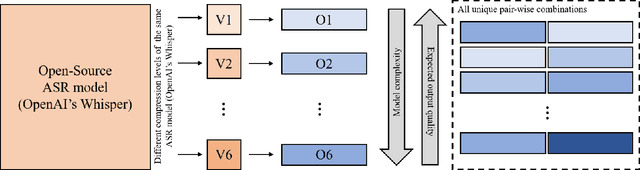
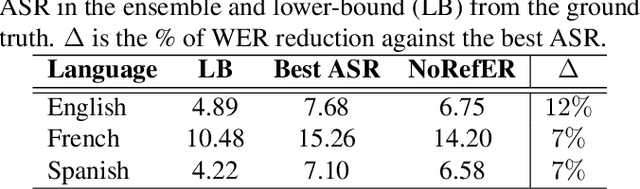
The common standard for quality evaluation of automatic speech recognition (ASR) systems is reference-based metrics such as the Word Error Rate (WER), computed using manual ground-truth transcriptions that are time-consuming and expensive to obtain. This work proposes a multi-language referenceless quality metric, which allows comparing the performance of different ASR models on a speech dataset without ground truth transcriptions. To estimate the quality of ASR hypotheses, a pre-trained language model (LM) is fine-tuned with contrastive learning in a self-supervised learning manner. In experiments conducted on several unseen test datasets consisting of outputs from top commercial ASR engines in various languages, the proposed referenceless metric obtains a much higher correlation with WER scores and their ranks than the perplexity metric from the state-of-art multi-lingual LM in all experiments, and also reduces WER by more than $7\%$ when used for ensembling hypotheses. The fine-tuned model and experiments are made available for the reproducibility: https://github.com/aixplain/NoRefER
EvolveMT: an Ensemble MT Engine Improving Itself with Usage Only
Jun 20, 2023This paper presents EvolveMT for efficiently combining multiple machine translation (MT) engines. The proposed system selects the output from a single engine for each segment by utilizing online learning techniques to predict the most suitable system for every translation request. A neural quality estimation metric supervises the method without requiring reference translations. The online learning capability of this system allows for dynamic adaptation to alterations in the domain or machine translation engines, thereby obviating the necessity for additional training. EvolveMT selects a subset of translation engines to be called based on the source sentence features. The degree of exploration is configurable according to the desired quality-cost trade-off. Results from custom datasets demonstrate that EvolveMT achieves similar translation accuracy at a lower cost than selecting the best translation of each segment from all translations using an MT quality estimator. To our knowledge, EvolveMT is the first meta MT system that adapts itself after deployment to incoming translation requests from the production environment without needing costly retraining on human feedback.
Creating a Large Multi-Layered Representational Repository of Linguistic Code Switched Arabic Data
Sep 28, 2019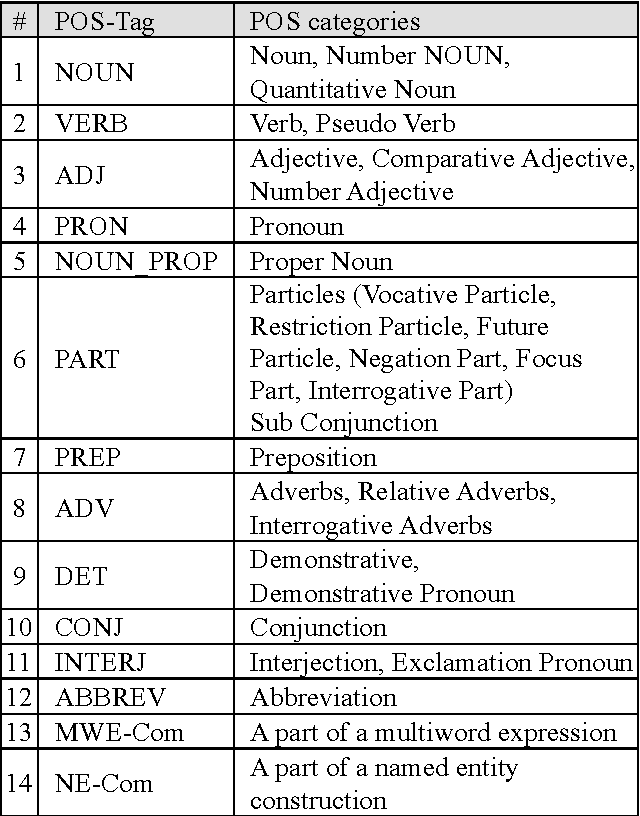
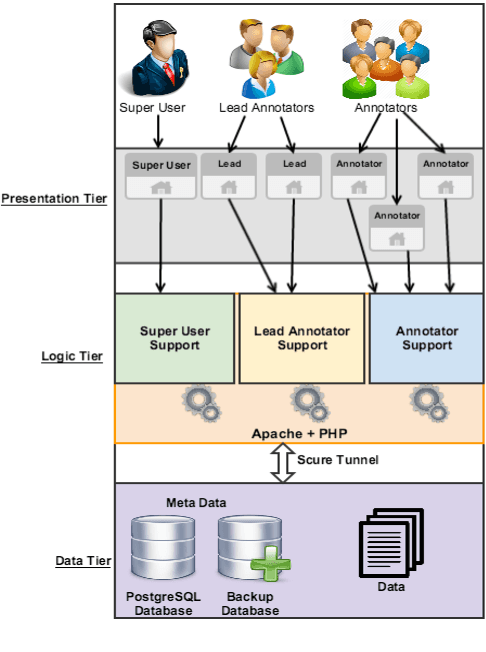
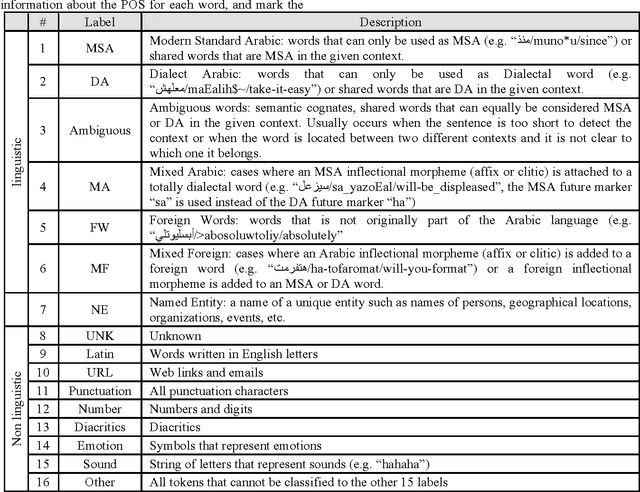
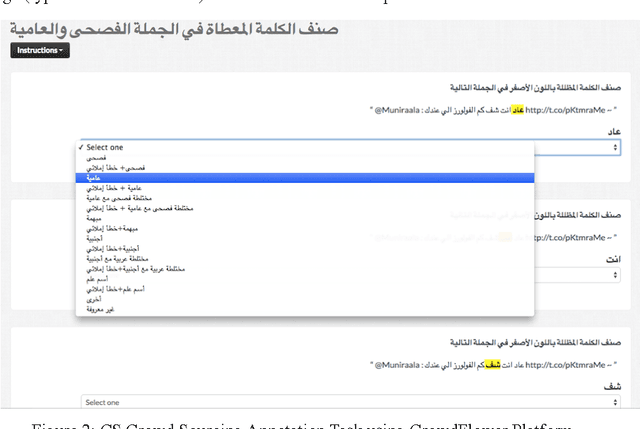
We present our effort to create a large Multi-Layered representational repository of Linguistic Code-Switched Arabic data. The process involves developing clear annotation standards and Guidelines, streamlining the annotation process, and implementing quality control measures. We used two main protocols for annotation: in-lab gold annotations and crowd sourcing annotations. We developed a web-based annotation tool to facilitate the management of the annotation process. The current version of the repository contains a total of 886,252 tokens that are tagged into one of sixteen code-switching tags. The data exhibits code switching between Modern Standard Arabic and Egyptian Dialectal Arabic representing three data genres: Tweets, commentaries, and discussion fora. The overall Inter-Annotator Agreement is 93.1%.