 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOverview for the Second Shared Task on Language Identification in Code-Switched Data
Sep 28, 2019

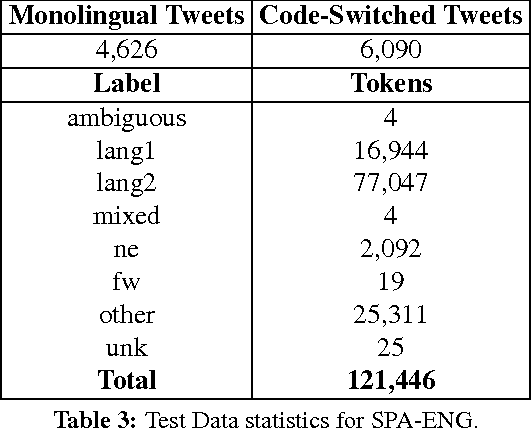
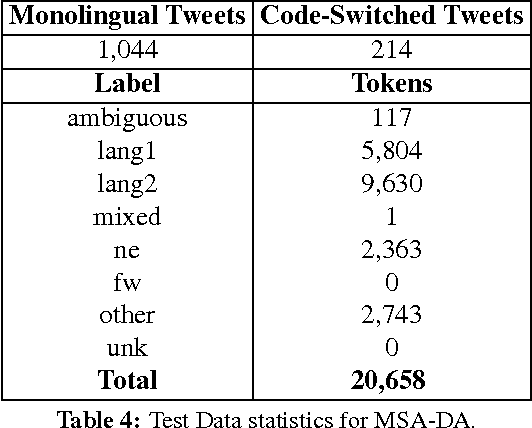
We present an overview of the second shared task on language identification in code-switched data. For the shared task, we had code-switched data from two different language pairs: Modern Standard Arabic-Dialectal Arabic (MSA-DA) and Spanish-English (SPA-ENG). We had a total of nine participating teams, with all teams submitting a system for SPA-ENG and four submitting for MSA-DA. Through evaluation, we found that once again language identification is more difficult for the language pair that is more closely related. We also found that this year's systems performed better overall than the systems from the previous shared task indicating overall progress in the state of the art for this task.
Creating a Large Multi-Layered Representational Repository of Linguistic Code Switched Arabic Data
Sep 28, 2019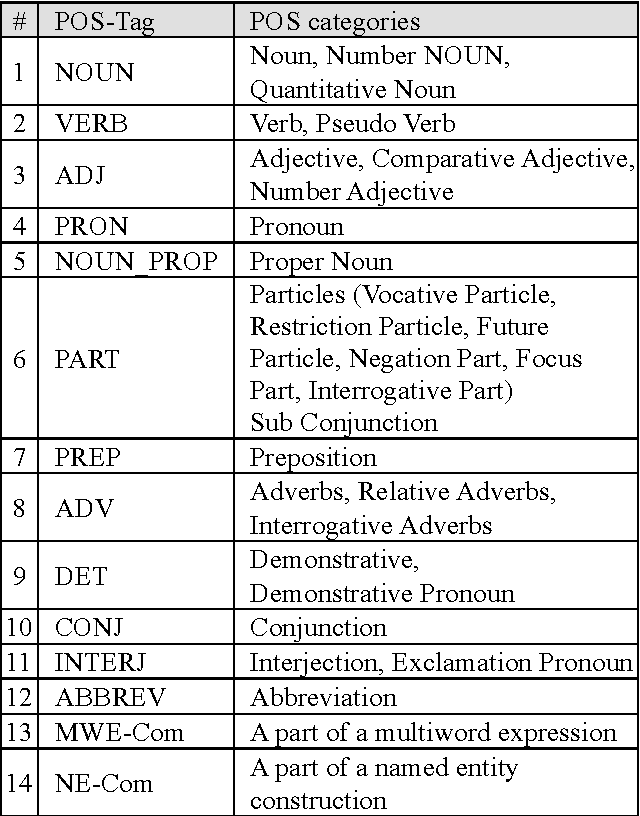
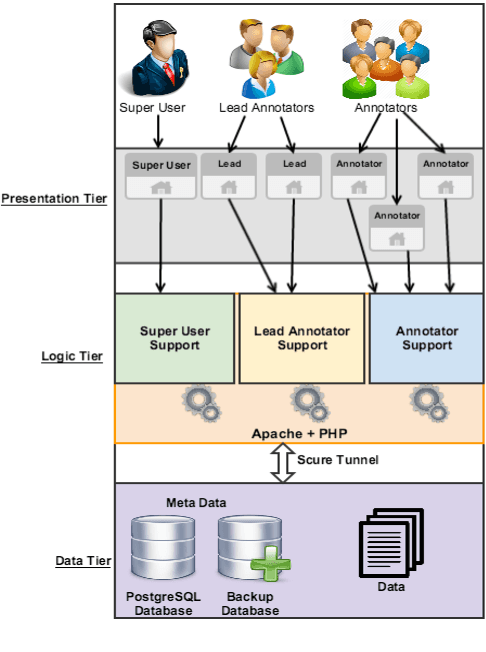
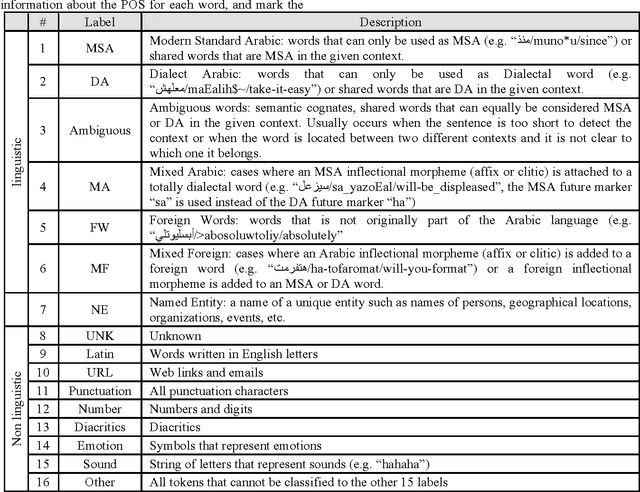
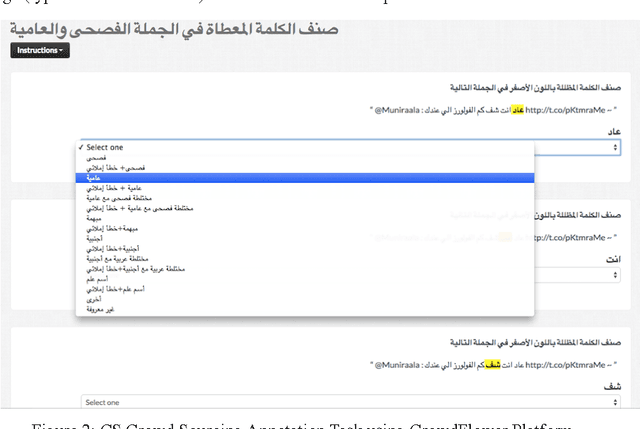
We present our effort to create a large Multi-Layered representational repository of Linguistic Code-Switched Arabic data. The process involves developing clear annotation standards and Guidelines, streamlining the annotation process, and implementing quality control measures. We used two main protocols for annotation: in-lab gold annotations and crowd sourcing annotations. We developed a web-based annotation tool to facilitate the management of the annotation process. The current version of the repository contains a total of 886,252 tokens that are tagged into one of sixteen code-switching tags. The data exhibits code switching between Modern Standard Arabic and Egyptian Dialectal Arabic representing three data genres: Tweets, commentaries, and discussion fora. The overall Inter-Annotator Agreement is 93.1%.