 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePart of speech tagging for code switched data
Nov 03, 2019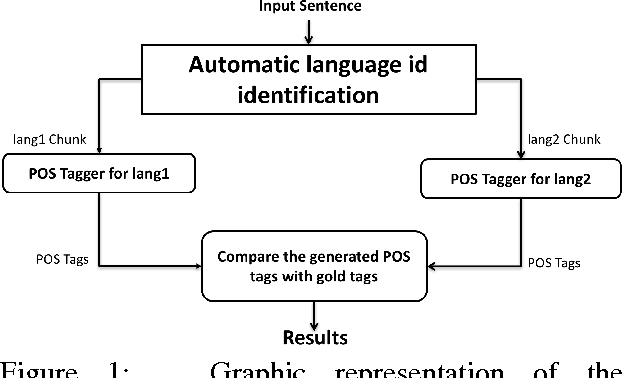
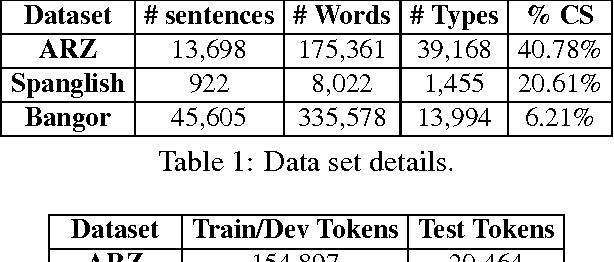
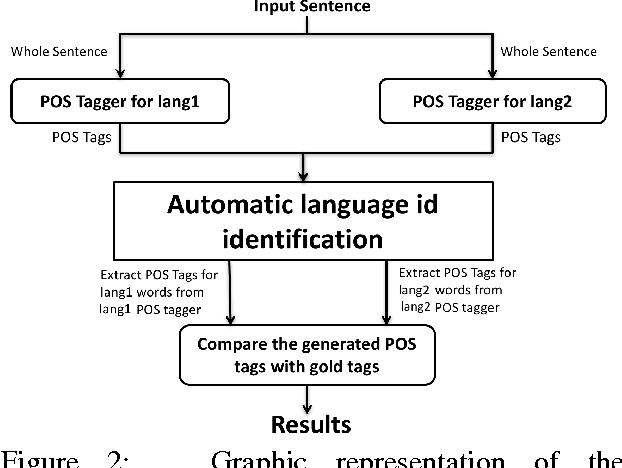
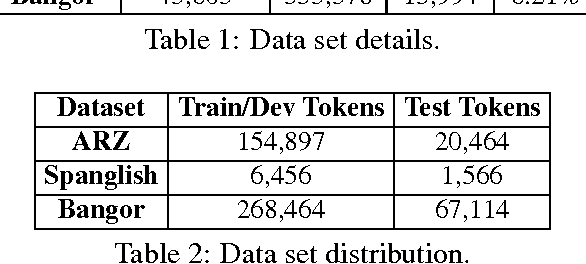
We address the problem of Part of Speech tagging (POS) in the context of linguistic code switching (CS). CS is the phenomenon where a speaker switches between two languages or variants of the same language within or across utterances, known as intra-sentential or inter-sentential CS, respectively. Processing CS data is especially challenging in intra-sentential data given state of the art monolingual NLP technology since such technology is geared toward the processing of one language at a time. In this paper we explore multiple strategies of applying state of the art POS taggers to CS data. We investigate the landscape in two CS language pairs, Spanish-English and Modern Standard Arabic-Arabic dialects. We compare the use of two POS taggers vs. a unified tagger trained on CS data. Our results show that applying a machine learning framework using two state of the art POS taggers achieves better performance compared to all other approaches that we investigate.
Overview for the Second Shared Task on Language Identification in Code-Switched Data
Sep 28, 2019

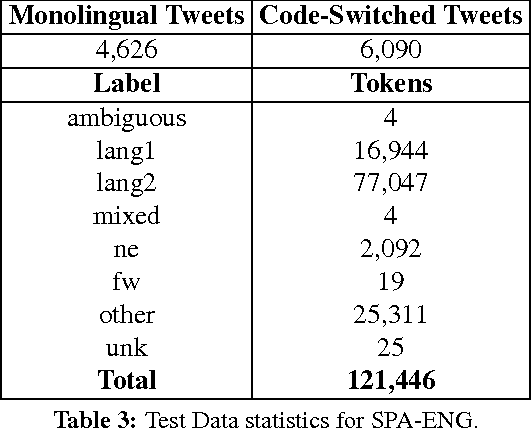
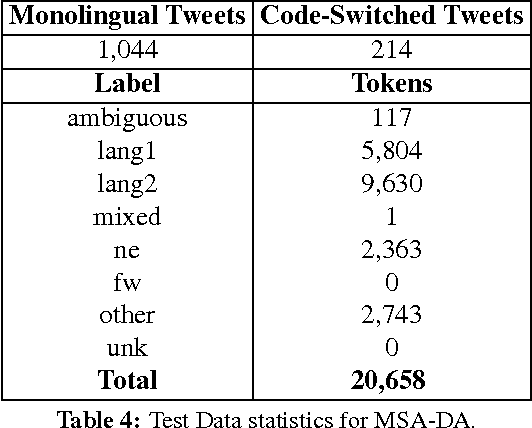
We present an overview of the second shared task on language identification in code-switched data. For the shared task, we had code-switched data from two different language pairs: Modern Standard Arabic-Dialectal Arabic (MSA-DA) and Spanish-English (SPA-ENG). We had a total of nine participating teams, with all teams submitting a system for SPA-ENG and four submitting for MSA-DA. Through evaluation, we found that once again language identification is more difficult for the language pair that is more closely related. We also found that this year's systems performed better overall than the systems from the previous shared task indicating overall progress in the state of the art for this task.
Creating a Large Multi-Layered Representational Repository of Linguistic Code Switched Arabic Data
Sep 28, 2019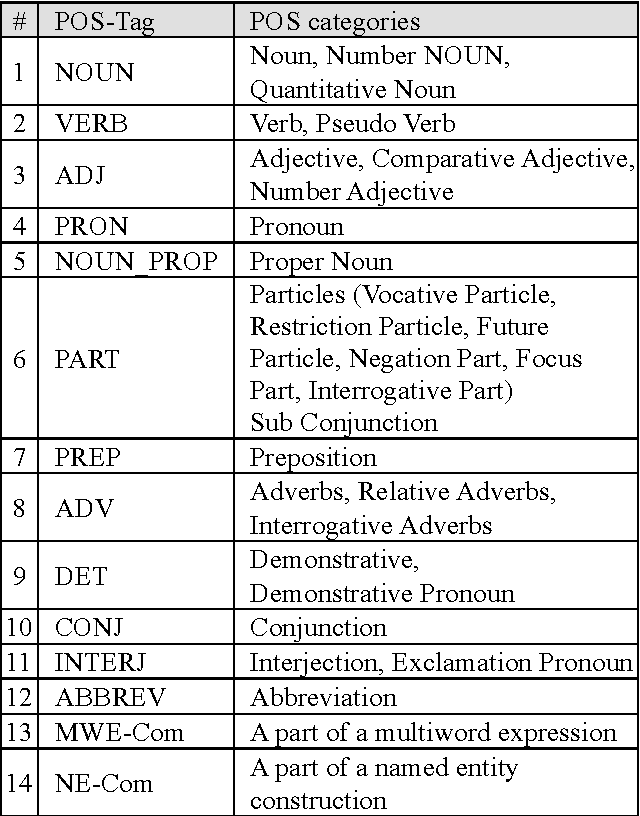
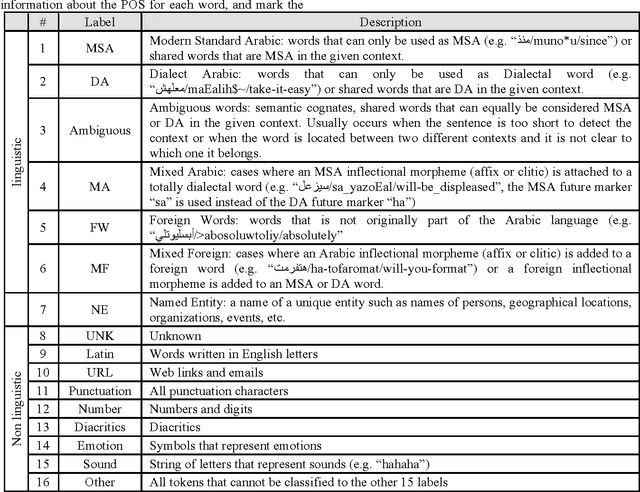
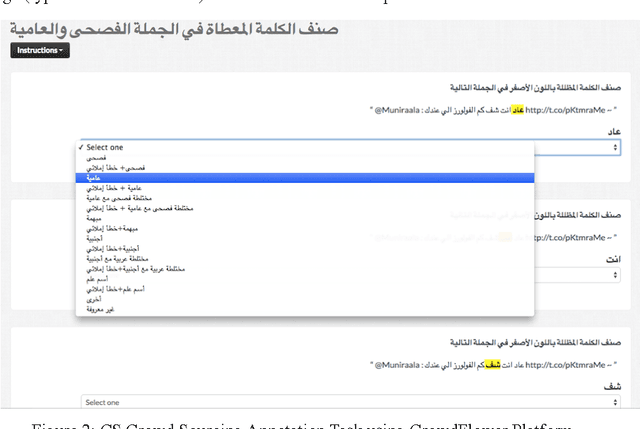
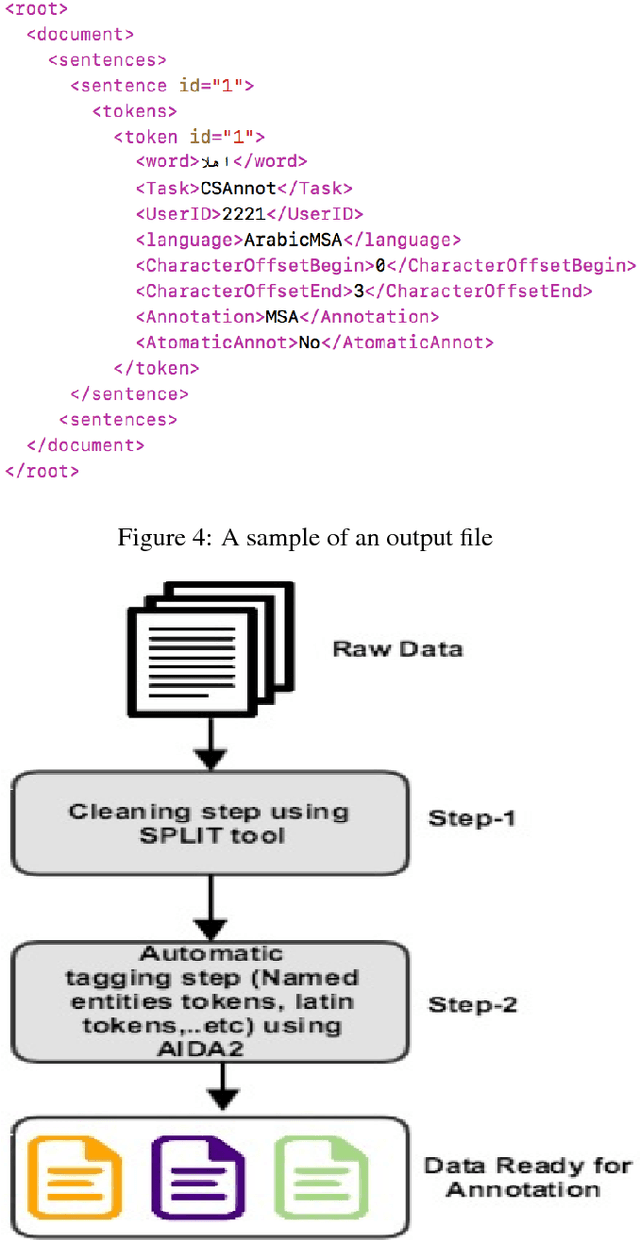
We present our effort to create a large Multi-Layered representational repository of Linguistic Code-Switched Arabic data. The process involves developing clear annotation standards and Guidelines, streamlining the annotation process, and implementing quality control measures. We used two main protocols for annotation: in-lab gold annotations and crowd sourcing annotations. We developed a web-based annotation tool to facilitate the management of the annotation process. The current version of the repository contains a total of 886,252 tokens that are tagged into one of sixteen code-switching tags. The data exhibits code switching between Modern Standard Arabic and Egyptian Dialectal Arabic representing three data genres: Tweets, commentaries, and discussion fora. The overall Inter-Annotator Agreement is 93.1%.
WASA: A Web Application for Sequence Annotation
Sep 28, 2019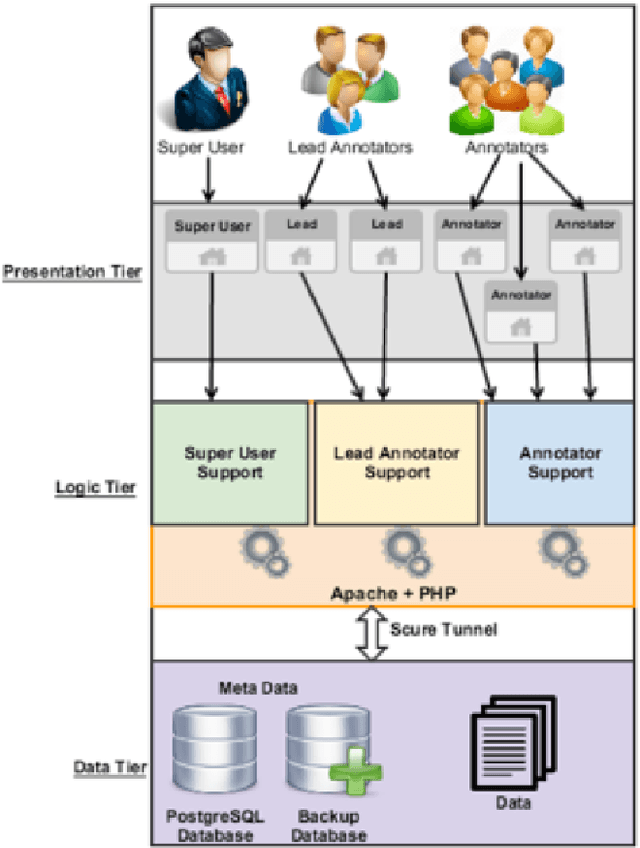

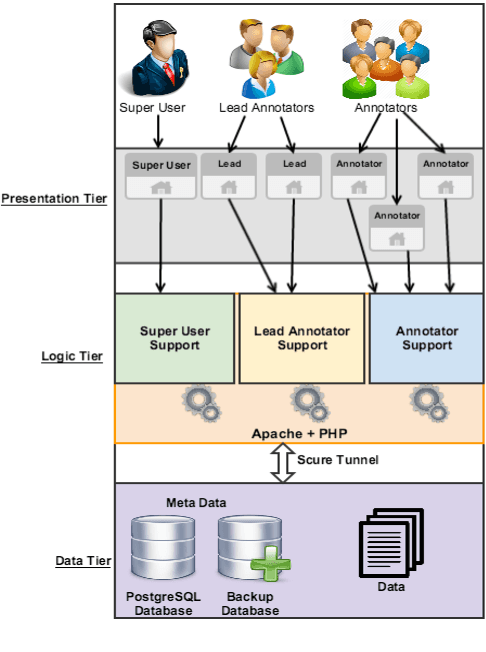
Data annotation is an important and necessary task for all NLP applications. Designing and implementing a web-based application that enables many annotators to annotate and enter their input into one central database is not a trivial task. These kinds of web-based applications require a consistent and robust backup for the underlying database and support to enhance the efficiency and speed of the annotation. Also, they need to ensure that the annotations are stored with a minimal amount of redundancy in order to take advantage of the available resources(e.g, storage space). In this paper, we introduce WASA, a web-based annotation system for managing large-scale multilingual Code Switching (CS) data annotation. Although WASA has the ability to perform the annotation for any token sequence with arbitrary tag sets, we will focus on how WASA is used for CS annotation. The system supports concurrent annotation, handles multiple encodings, allows for several levels of management control, and enables quality control measures while seamlessly reporting annotation statistics from various perspectives and at different levels of granularity. Moreover, the system is integrated with a robust language specific date prepossessing tool to enhance the speed and efficiency of the annotation. We describe the annotation and the administration interfaces as well as the backend engine.
Named Entity Recognition on Code-Switched Data: Overview of the CALCS 2018 Shared Task
Jun 10, 2019
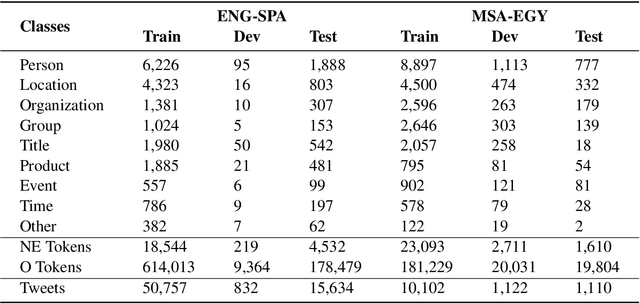
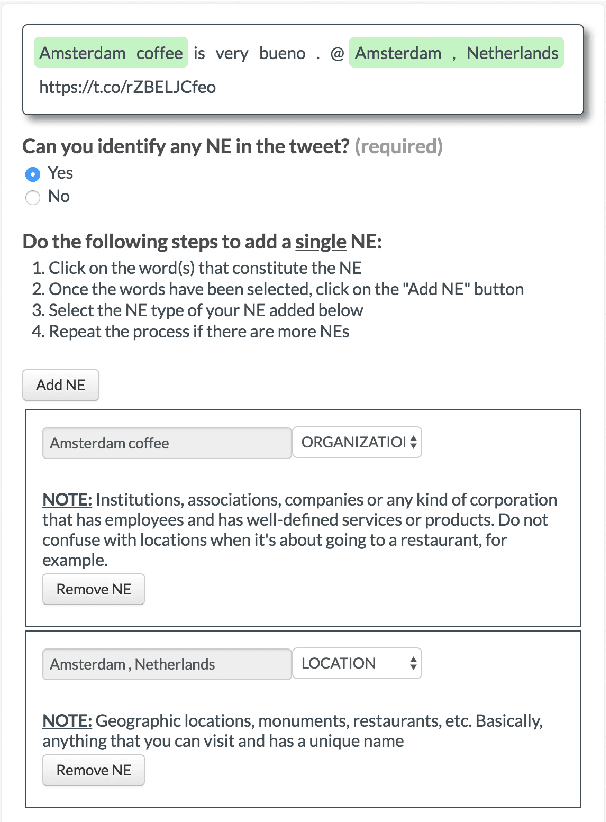
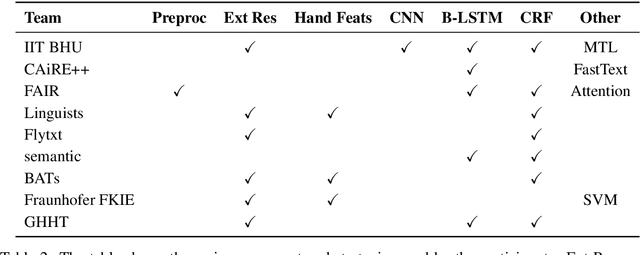
In the third shared task of the Computational Approaches to Linguistic Code-Switching (CALCS) workshop, we focus on Named Entity Recognition (NER) on code-switched social-media data. We divide the shared task into two competitions based on the English-Spanish (ENG-SPA) and Modern Standard Arabic-Egyptian (MSA-EGY) language pairs. We use Twitter data and 9 entity types to establish a new dataset for code-switched NER benchmarks. In addition to the CS phenomenon, the diversity of the entities and the social media challenges make the task considerably hard to process. As a result, the best scores of the competitions are 63.76% and 71.61% for ENG-SPA and MSA-EGY, respectively. We present the scores of 9 participants and discuss the most common challenges among submissions.
* ACL 2018 (CALCS)
Leveraging Pretrained Word Embeddings for Part-of-Speech Tagging of Code Switching Data
May 31, 2019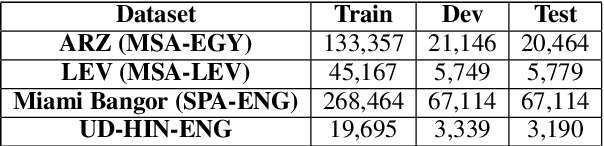
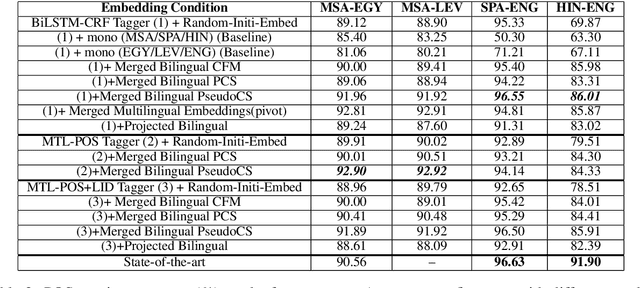


Linguistic Code Switching (CS) is a phenomenon that occurs when multilingual speakers alternate between two or more languages/dialects within a single conversation. Processing CS data is especially challenging in intra-sentential data given state-of-the-art monolingual NLP technologies since such technologies are geared toward the processing of one language at a time. In this paper, we address the problem of Part-of-Speech tagging (POS) in the context of linguistic code switching (CS). We explore leveraging multiple neural network architectures to measure the impact of different pre-trained embeddings methods on POS tagging CS data. We investigate the landscape in four CS language pairs, Spanish-English, Hindi-English, Modern Standard Arabic- Egyptian Arabic dialect (MSA-EGY), and Modern Standard Arabic- Levantine Arabic dialect (MSA-LEV). Our results show that multilingual embedding (e.g., MSA-EGY and MSA-LEV) helps closely related languages (EGY/LEV) but adds noise to the languages that are distant (SPA/HIN). Finally, we show that our proposed models outperform state-of-the-art CS taggers for MSA-EGY language pair.