 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMergeME: Model Merging Techniques for Homogeneous and Heterogeneous MoEs
Feb 04, 2025



The recent success of specialized Large Language Models (LLMs) in domains such as mathematical reasoning and coding has led to growing interest in methods for merging these expert LLMs into a unified Mixture-of-Experts (MoE) model, with the goal of enhancing performance in each domain while retaining effectiveness on general tasks. However, the effective merging of expert models remains an open challenge, especially for models with highly divergent weight parameters or different architectures. State-of-the-art MoE merging methods only work with homogeneous model architectures and rely on simple unweighted averaging to merge expert layers, which does not address parameter interference and requires extensive fine-tuning of the merged MoE to restore performance. To address these limitations, this paper introduces new MoE merging techniques, including strategies to mitigate parameter interference, routing heuristics to reduce the need for MoE fine-tuning, and a novel method for merging experts with different architectures. Extensive experiments across multiple domains demonstrate the effectiveness of our proposed methods, reducing fine-tuning costs, improving performance over state-of-the-art methods, and expanding the applicability of MoE merging.
MAML-en-LLM: Model Agnostic Meta-Training of LLMs for Improved In-Context Learning
May 19, 2024



Adapting large language models (LLMs) to unseen tasks with in-context training samples without fine-tuning remains an important research problem. To learn a robust LLM that adapts well to unseen tasks, multiple meta-training approaches have been proposed such as MetaICL and MetaICT, which involve meta-training pre-trained LLMs on a wide variety of diverse tasks. These meta-training approaches essentially perform in-context multi-task fine-tuning and evaluate on a disjointed test set of tasks. Even though they achieve impressive performance, their goal is never to compute a truly general set of parameters. In this paper, we propose MAML-en-LLM, a novel method for meta-training LLMs, which can learn truly generalizable parameters that not only perform well on disjointed tasks but also adapts to unseen tasks. We see an average increase of 2% on unseen domains in the performance while a massive 4% improvement on adaptation performance. Furthermore, we demonstrate that MAML-en-LLM outperforms baselines in settings with limited amount of training data on both seen and unseen domains by an average of 2%. Finally, we discuss the effects of type of tasks, optimizers and task complexity, an avenue barely explored in meta-training literature. Exhaustive experiments across 7 task settings along with two data settings demonstrate that models trained with MAML-en-LLM outperform SOTA meta-training approaches.
Part of speech tagging for code switched data
Nov 03, 2019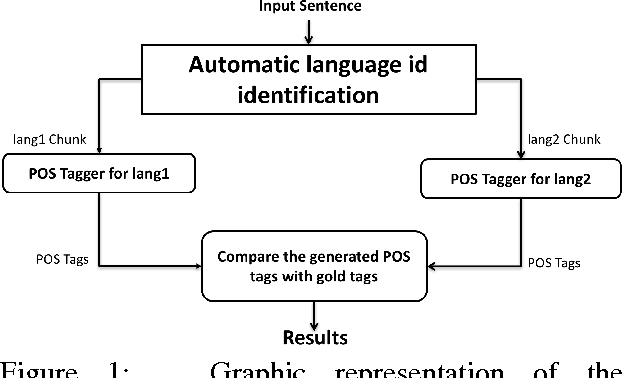
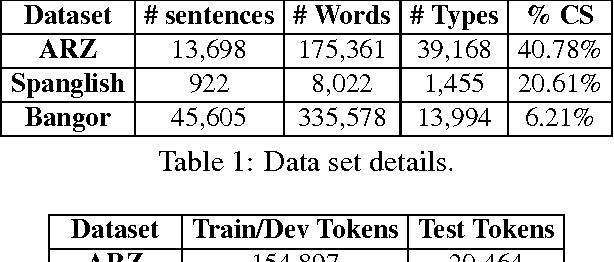
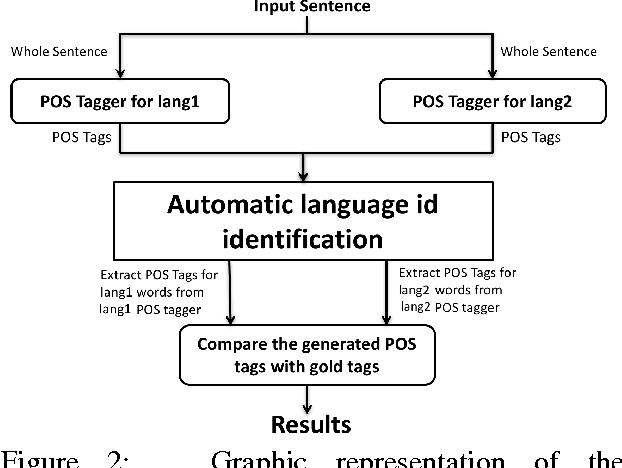
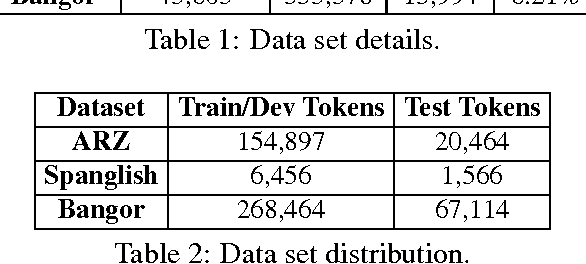
We address the problem of Part of Speech tagging (POS) in the context of linguistic code switching (CS). CS is the phenomenon where a speaker switches between two languages or variants of the same language within or across utterances, known as intra-sentential or inter-sentential CS, respectively. Processing CS data is especially challenging in intra-sentential data given state of the art monolingual NLP technology since such technology is geared toward the processing of one language at a time. In this paper we explore multiple strategies of applying state of the art POS taggers to CS data. We investigate the landscape in two CS language pairs, Spanish-English and Modern Standard Arabic-Arabic dialects. We compare the use of two POS taggers vs. a unified tagger trained on CS data. Our results show that applying a machine learning framework using two state of the art POS taggers achieves better performance compared to all other approaches that we investigate.
Named Entity Recognition on Code-Switched Data: Overview of the CALCS 2018 Shared Task
Jun 10, 2019
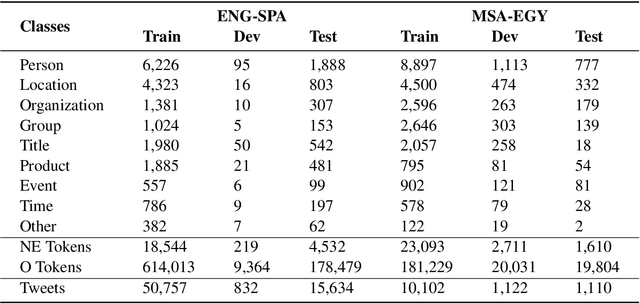
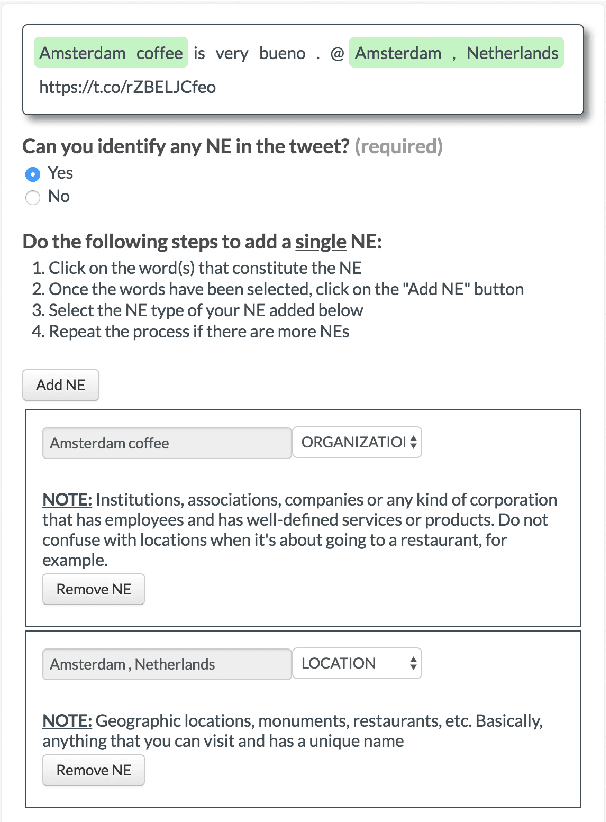
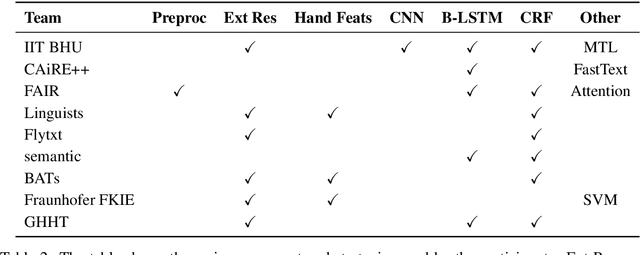
In the third shared task of the Computational Approaches to Linguistic Code-Switching (CALCS) workshop, we focus on Named Entity Recognition (NER) on code-switched social-media data. We divide the shared task into two competitions based on the English-Spanish (ENG-SPA) and Modern Standard Arabic-Egyptian (MSA-EGY) language pairs. We use Twitter data and 9 entity types to establish a new dataset for code-switched NER benchmarks. In addition to the CS phenomenon, the diversity of the entities and the social media challenges make the task considerably hard to process. As a result, the best scores of the competitions are 63.76% and 71.61% for ENG-SPA and MSA-EGY, respectively. We present the scores of 9 participants and discuss the most common challenges among submissions.
* ACL 2018 (CALCS)
Crowdsourcing Universal Part-Of-Speech Tags for Code-Switching
Mar 24, 2017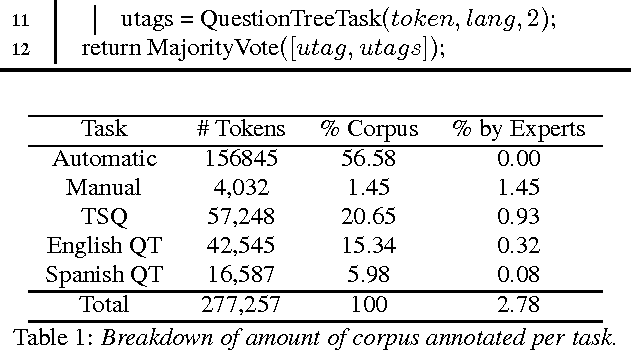
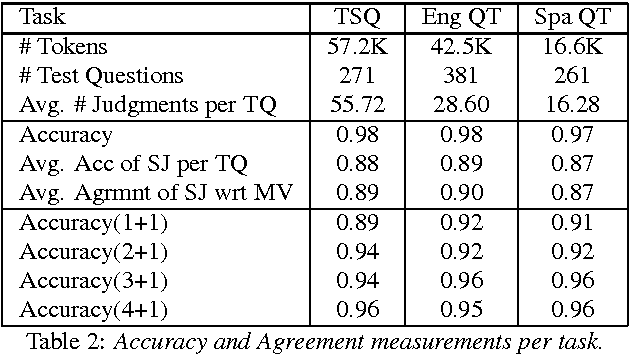
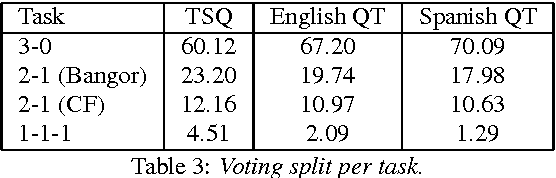
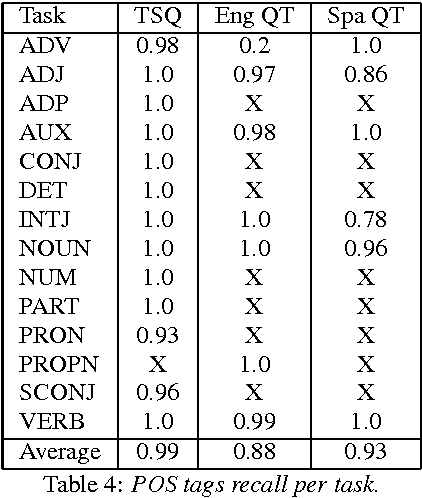
Code-switching is the phenomenon by which bilingual speakers switch between multiple languages during communication. The importance of developing language technologies for codeswitching data is immense, given the large populations that routinely code-switch. High-quality linguistic annotations are extremely valuable for any NLP task, and performance is often limited by the amount of high-quality labeled data. However, little such data exists for code-switching. In this paper, we describe crowd-sourcing universal part-of-speech tags for the Miami Bangor Corpus of Spanish-English code-switched speech. We split the annotation task into three subtasks: one in which a subset of tokens are labeled automatically, one in which questions are specifically designed to disambiguate a subset of high frequency words, and a more general cascaded approach for the remaining data in which questions are displayed to the worker following a decision tree structure. Each subtask is extended and adapted for a multilingual setting and the universal tagset. The quality of the annotation process is measured using hidden check questions annotated with gold labels. The overall agreement between gold standard labels and the majority vote is between 0.95 and 0.96 for just three labels and the average recall across part-of-speech tags is between 0.87 and 0.99, depending on the task.