 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHazard Detection And Avoidance For The Nova-C Lander
Apr 01, 2022
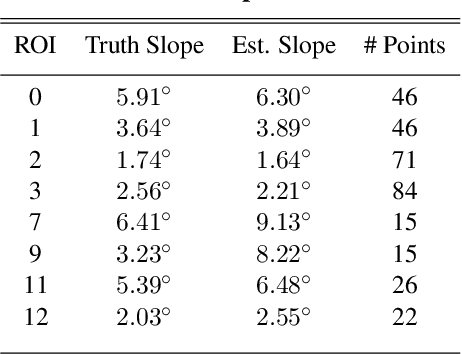


In early 2022, Intuitive Machines' NOVA-C Lander will touch down on the lunar surface becoming the first commercial endeavor to visit a celestial body. NOVA-C will deliver six payloads to the lunar surface with various scientific and engineering objectives, ushering in a new era of commercial space exploration and utilization. However, to safely accomplish the mission, the NOVA-C lander must ensure its landing site is free of hazards larger than 30 cm and the slope of local terrain at touchdown is less than 10 degrees off vertical. To accomplish this, NOVA-C utilizes Intuitive Machines' precision navigation system, coupled with machine vision algorithms for scene reduction and landing site characterization. A unique aspect to the NOVA-C approach is the real-time nature of the hazard detection and avoidance algorithms--which are performed 400 meters above and down range of the intended landing site and completed within 15 seconds. In this paper, we review the theoretical foundations for the hazard detection and avoidance algorithms, describe the practical challenges of implementation on the NOVA-C flight computer, and present test and analysis results.
Part of speech tagging for code switched data
Nov 03, 2019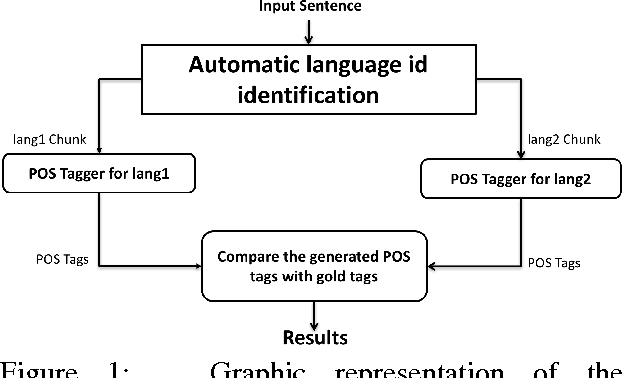
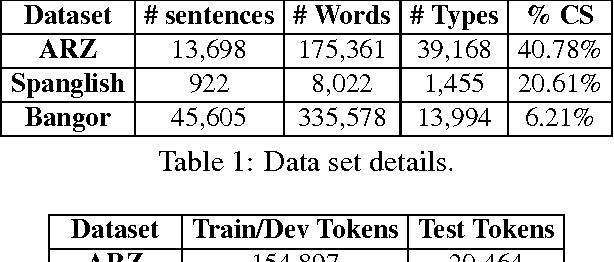
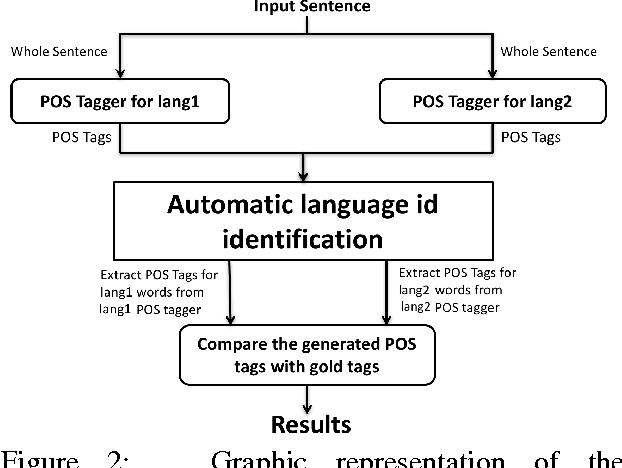
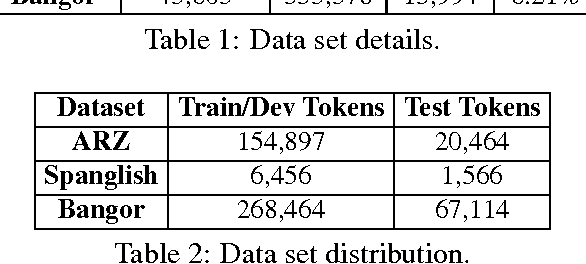
We address the problem of Part of Speech tagging (POS) in the context of linguistic code switching (CS). CS is the phenomenon where a speaker switches between two languages or variants of the same language within or across utterances, known as intra-sentential or inter-sentential CS, respectively. Processing CS data is especially challenging in intra-sentential data given state of the art monolingual NLP technology since such technology is geared toward the processing of one language at a time. In this paper we explore multiple strategies of applying state of the art POS taggers to CS data. We investigate the landscape in two CS language pairs, Spanish-English and Modern Standard Arabic-Arabic dialects. We compare the use of two POS taggers vs. a unified tagger trained on CS data. Our results show that applying a machine learning framework using two state of the art POS taggers achieves better performance compared to all other approaches that we investigate.
Overview for the Second Shared Task on Language Identification in Code-Switched Data
Sep 28, 2019

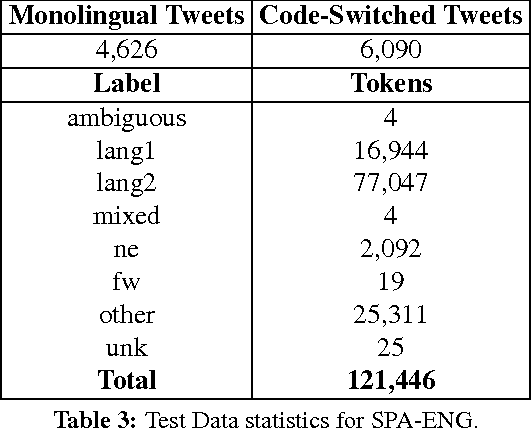
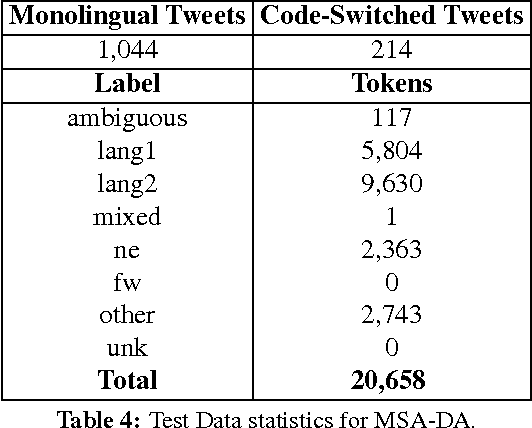
We present an overview of the second shared task on language identification in code-switched data. For the shared task, we had code-switched data from two different language pairs: Modern Standard Arabic-Dialectal Arabic (MSA-DA) and Spanish-English (SPA-ENG). We had a total of nine participating teams, with all teams submitting a system for SPA-ENG and four submitting for MSA-DA. Through evaluation, we found that once again language identification is more difficult for the language pair that is more closely related. We also found that this year's systems performed better overall than the systems from the previous shared task indicating overall progress in the state of the art for this task.