 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-Scale AI in Telecom: Charting the Roadmap for Innovation, Scalability, and Enhanced Digital Experiences
Mar 06, 2025



This white paper discusses the role of large-scale AI in the telecommunications industry, with a specific focus on the potential of generative AI to revolutionize network functions and user experiences, especially in the context of 6G systems. It highlights the development and deployment of Large Telecom Models (LTMs), which are tailored AI models designed to address the complex challenges faced by modern telecom networks. The paper covers a wide range of topics, from the architecture and deployment strategies of LTMs to their applications in network management, resource allocation, and optimization. It also explores the regulatory, ethical, and standardization considerations for LTMs, offering insights into their future integration into telecom infrastructure. The goal is to provide a comprehensive roadmap for the adoption of LTMs to enhance scalability, performance, and user-centric innovation in telecom networks.
PromptDet: A Lightweight 3D Object Detection Framework with LiDAR Prompts
Dec 17, 2024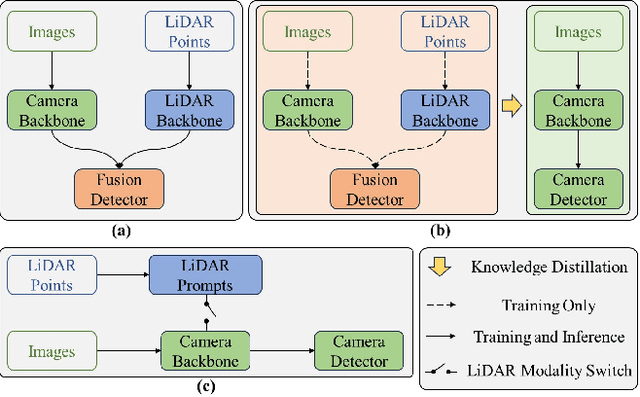
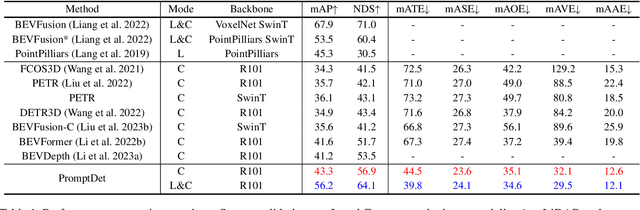
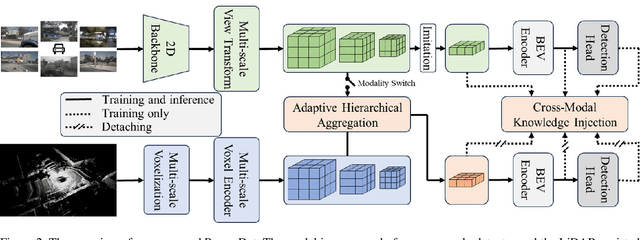
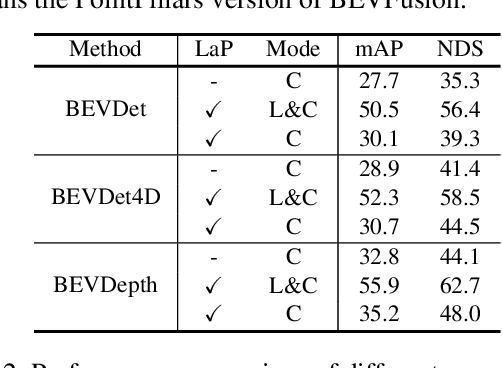
Multi-camera 3D object detection aims to detect and localize objects in 3D space using multiple cameras, which has attracted more attention due to its cost-effectiveness trade-off. However, these methods often struggle with the lack of accurate depth estimation caused by the natural weakness of the camera in ranging. Recently, multi-modal fusion and knowledge distillation methods for 3D object detection have been proposed to solve this problem, which are time-consuming during the training phase and not friendly to memory cost. In light of this, we propose PromptDet, a lightweight yet effective 3D object detection framework motivated by the success of prompt learning in 2D foundation model. Our proposed framework, PromptDet, comprises two integral components: a general camera-based detection module, exemplified by models like BEVDet and BEVDepth, and a LiDAR-assisted prompter. The LiDAR-assisted prompter leverages the LiDAR points as a complementary signal, enriched with a minimal set of additional trainable parameters. Notably, our framework is flexible due to our prompt-like design, which can not only be used as a lightweight multi-modal fusion method but also as a camera-only method for 3D object detection during the inference phase. Extensive experiments on nuScenes validate the effectiveness of the proposed PromptDet. As a multi-modal detector, PromptDet improves the mAP and NDS by at most 22.8\% and 21.1\% with fewer than 2\% extra parameters compared with the camera-only baseline. Without LiDAR points, PromptDet still achieves an improvement of at most 2.4\% mAP and 4.0\% NDS with almost no impact on camera detection inference time.
Exploring Multi-view Pixel Contrast for General and Robust Image Forgery Localization
Jun 19, 2024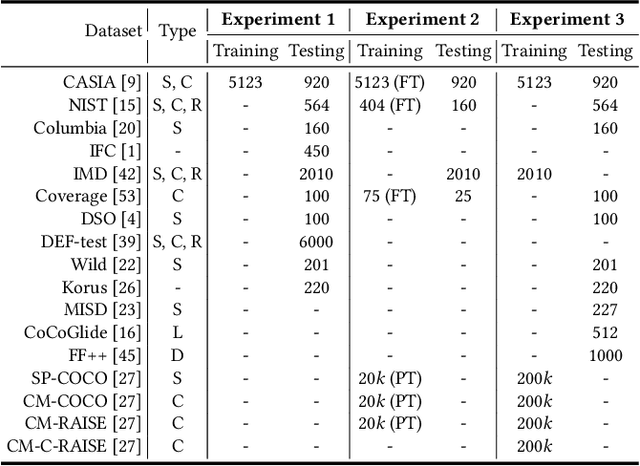
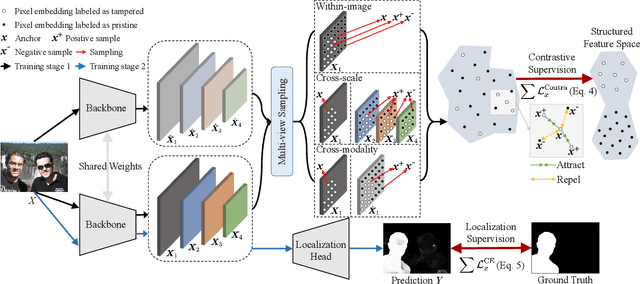
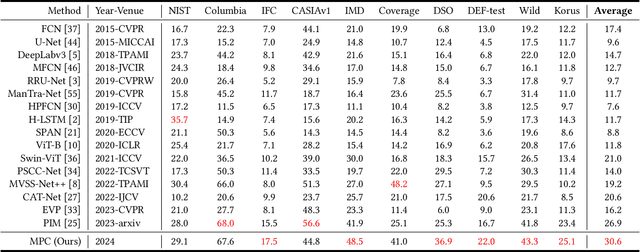
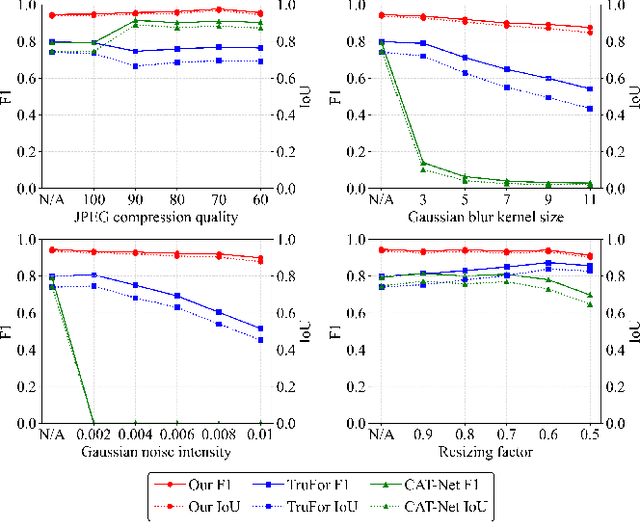
Image forgery localization, which aims to segment tampered regions in an image, is a fundamental yet challenging digital forensic task. While some deep learning-based forensic methods have achieved impressive results, they directly learn pixel-to-label mappings without fully exploiting the relationship between pixels in the feature space. To address such deficiency, we propose a Multi-view Pixel-wise Contrastive algorithm (MPC) for image forgery localization. Specifically, we first pre-train the backbone network with the supervised contrastive loss to model pixel relationships from the perspectives of within-image, cross-scale and cross-modality. That is aimed at increasing intra-class compactness and inter-class separability. Then the localization head is fine-tuned using the cross-entropy loss, resulting in a better pixel localizer. The MPC is trained on three different scale training datasets to make a comprehensive and fair comparison with existing image forgery localization algorithms. Extensive experiments on the small, medium and large scale training datasets show that the proposed MPC achieves higher generalization performance and robustness against post-processing than the state-of-the-arts. Code will be available at https://github.com/multimediaFor/MPC.
PackVFL: Efficient HE Packing for Vertical Federated Learning
May 01, 2024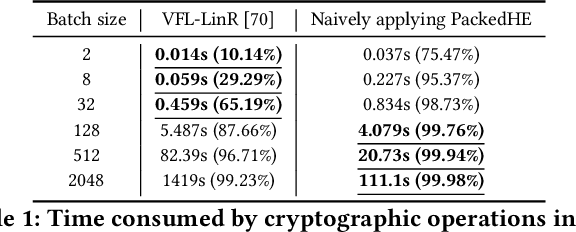
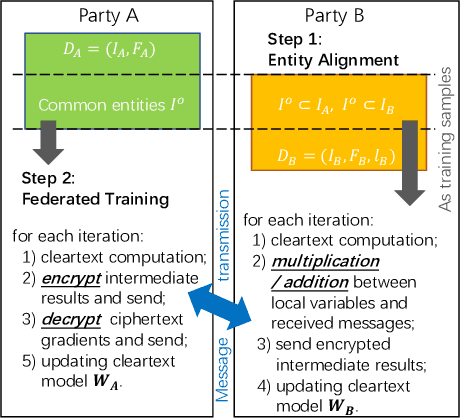
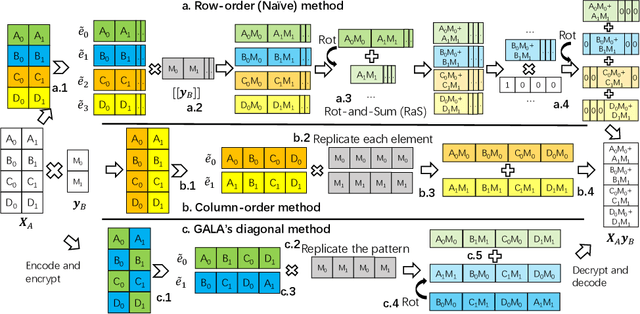

As an essential tool of secure distributed machine learning, vertical federated learning (VFL) based on homomorphic encryption (HE) suffers from severe efficiency problems due to data inflation and time-consuming operations. To this core, we propose PackVFL, an efficient VFL framework based on packed HE (PackedHE), to accelerate the existing HE-based VFL algorithms. PackVFL packs multiple cleartexts into one ciphertext and supports single-instruction-multiple-data (SIMD)-style parallelism. We focus on designing a high-performant matrix multiplication (MatMult) method since it takes up most of the ciphertext computation time in HE-based VFL. Besides, devising the MatMult method is also challenging for PackedHE because a slight difference in the packing way could predominantly affect its computation and communication costs. Without domain-specific design, directly applying SOTA MatMult methods is hard to achieve optimal. Therefore, we make a three-fold design: 1) we systematically explore the current design space of MatMult and quantify the complexity of existing approaches to provide guidance; 2) we propose a hybrid MatMult method according to the unique characteristics of VFL; 3) we adaptively apply our hybrid method in representative VFL algorithms, leveraging distinctive algorithmic properties to further improve efficiency. As the batch size, feature dimension and model size of VFL scale up to large sizes, PackVFL consistently delivers enhanced performance. Empirically, PackVFL propels existing VFL algorithms to new heights, achieving up to a 51.52X end-to-end speedup. This represents a substantial 34.51X greater speedup compared to the direct application of SOTA MatMult methods.
Effective Image Tampering Localization via Enhanced Transformer and Co-attention Fusion
Sep 17, 2023Powerful manipulation techniques have made digital image forgeries be easily created and widespread without leaving visual anomalies. The blind localization of tampered regions becomes quite significant for image forensics. In this paper, we propose an effective image tampering localization network (EITLNet) based on a two-branch enhanced transformer encoder with attention-based feature fusion. Specifically, a feature enhancement module is designed to enhance the feature representation ability of the transformer encoder. The features extracted from RGB and noise streams are fused effectively by the coordinate attention-based fusion module at multiple scales. Extensive experimental results verify that the proposed scheme achieves the state-of-the-art generalization ability and robustness in various benchmark datasets. Code will be public at https://github.com/multimediaFor/EITLNet.
The Potential of LEO Satellites in 6G Space-Air-Ground Enabled Access Networks
Jul 01, 2023
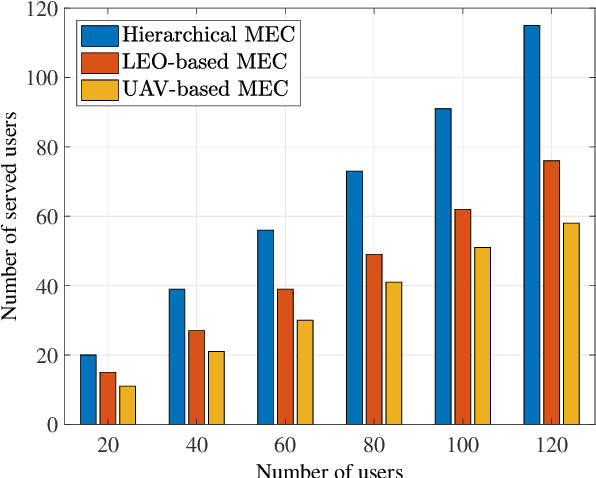

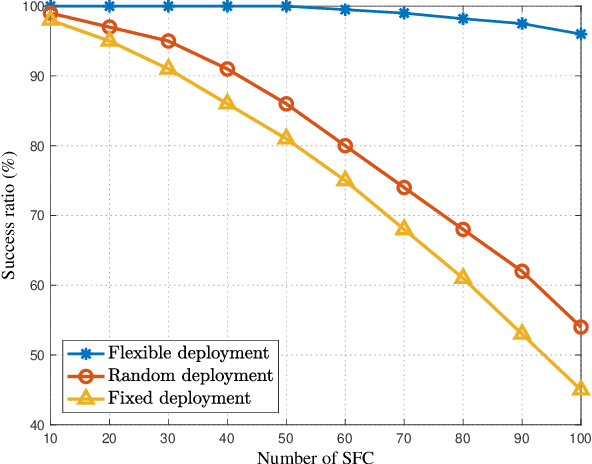
Space-air-ground integrated networks (SAGINs) help enhance the service performance in the sixth generation communication system. SAGIN is basically composed of satellites, aerial vehicles, ground facilities, as well as multiple terrestrial users. Therein, the low earth orbit (LEO) satellites are popular in recent years due to the low cost of development and launch, global coverage and delay-enabled services. Moreover, LEO satellites can support various applications, e.g., direct access, relay, caching and computation. In this work, we firstly provide the preliminaries and framework of SAGIN, in which the characteristics of LEO satellites, high altitude platforms, as well as unmanned aerial vehicles are analyzed. Then, the roles and potentials of LEO satellite in SAGIN are analyzed for access services. A couple of advanced techniques such as multi-access edge computing (MEC) and network function virtualization are introduced to enhance the LEO-based access service abilities as hierarchical MEC and network slicing in SAGIN. In addition, corresponding use cases are provided to verify the propositions. Besides, we also discuss the open issues and promising directions in LEO-enabled SAGIN access services for the future research.
Energy-Efficient URLLC Service Provision via a Near-Space Information Network
May 05, 2023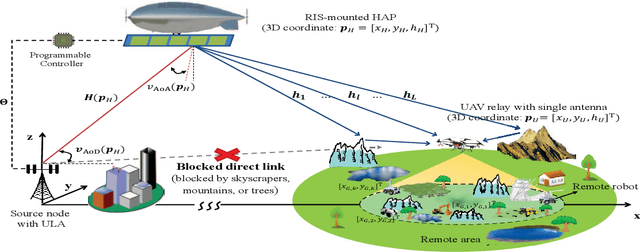
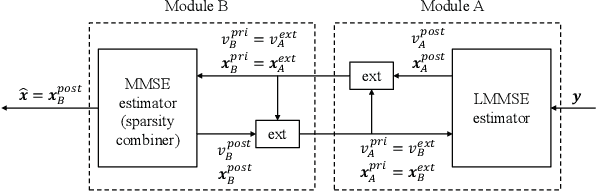
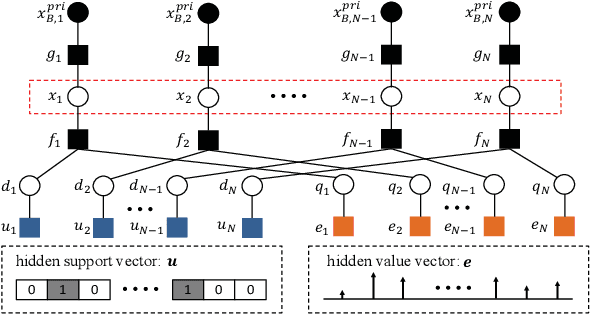
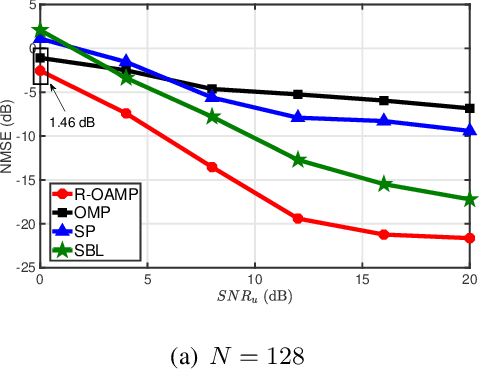
The integration of a near-space information network (NSIN) with the reconfigurable intelligent surface (RIS) is envisioned to significantly enhance the communication performance of future wireless communication systems by proactively altering wireless channels. This paper investigates the problem of deploying a RIS-integrated NSIN to provide energy-efficient, ultra-reliable and low-latency communications (URLLC) services. We mathematically formulate this problem as a resource optimization problem, aiming to maximize the effective throughput and minimize the system power consumption, subject to URLLC and physical resource constraints. The formulated problem is challenging in terms of accurate channel estimation, RIS phase alignment, theoretical analysis, and effective solution. We propose a joint resource allocation algorithm to handle these challenges. In this algorithm, we develop an accurate channel estimation approach by exploring message passing and optimize phase shifts of RIS reflecting elements to further increase the channel gain. Besides, we derive an analysis-friend expression of decoding error probability and decompose the problem into two-layered optimization problems by analyzing the monotonicity, which makes the formulated problem analytically tractable. Extensive simulations have been conducted to verify the performance of the proposed algorithm. Simulation results show that the proposed algorithm can achieve outstanding channel estimation performance and is more energy-efficient than diverse benchmark algorithms.
Automated Federated Learning in Mobile Edge Networks -- Fast Adaptation and Convergence
Mar 23, 2023
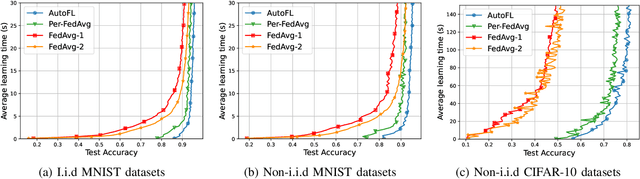
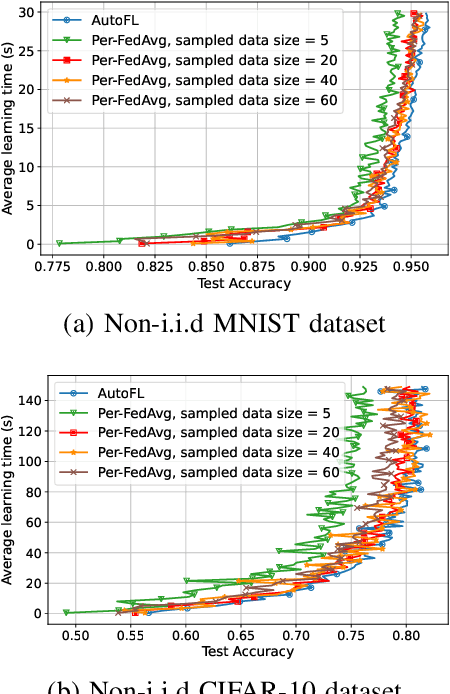
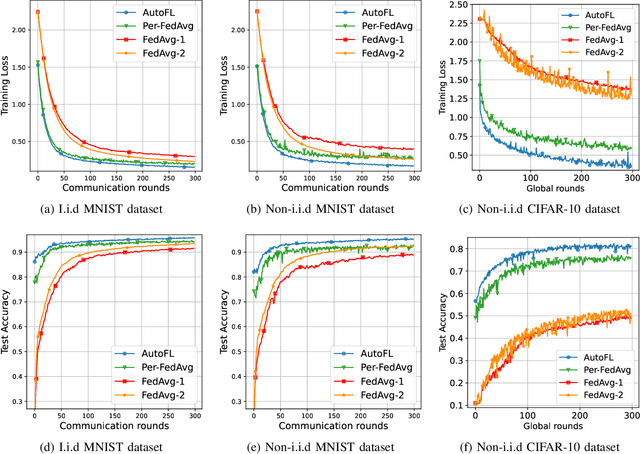
Federated Learning (FL) can be used in mobile edge networks to train machine learning models in a distributed manner. Recently, FL has been interpreted within a Model-Agnostic Meta-Learning (MAML) framework, which brings FL significant advantages in fast adaptation and convergence over heterogeneous datasets. However, existing research simply combines MAML and FL without explicitly addressing how much benefit MAML brings to FL and how to maximize such benefit over mobile edge networks. In this paper, we quantify the benefit from two aspects: optimizing FL hyperparameters (i.e., sampled data size and the number of communication rounds) and resource allocation (i.e., transmit power) in mobile edge networks. Specifically, we formulate the MAML-based FL design as an overall learning time minimization problem, under the constraints of model accuracy and energy consumption. Facilitated by the convergence analysis of MAML-based FL, we decompose the formulated problem and then solve it using analytical solutions and the coordinate descent method. With the obtained FL hyperparameters and resource allocation, we design a MAML-based FL algorithm, called Automated Federated Learning (AutoFL), that is able to conduct fast adaptation and convergence. Extensive experimental results verify that AutoFL outperforms other benchmark algorithms regarding the learning time and convergence performance.
Hierarchical Personalized Federated Learning Over Massive Mobile Edge Computing Networks
Mar 19, 2023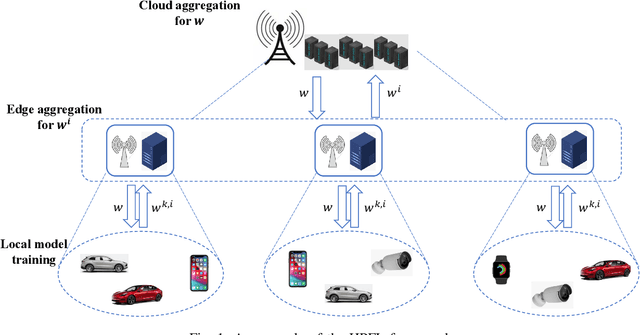
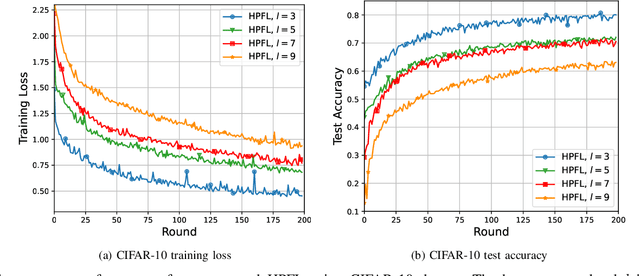
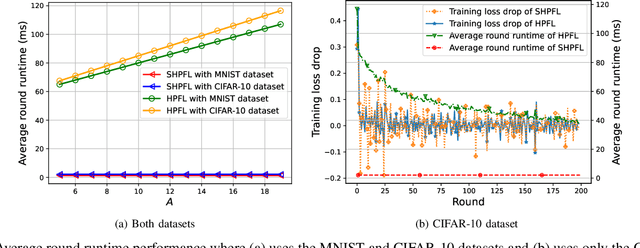
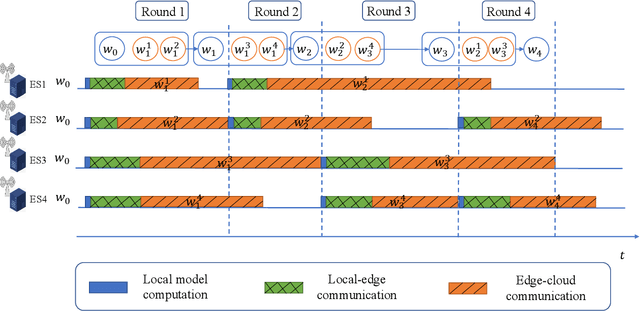
Personalized Federated Learning (PFL) is a new Federated Learning (FL) paradigm, particularly tackling the heterogeneity issues brought by various mobile user equipments (UEs) in mobile edge computing (MEC) networks. However, due to the ever-increasing number of UEs and the complicated administrative work it brings, it is desirable to switch the PFL algorithm from its conventional two-layer framework to a multiple-layer one. In this paper, we propose hierarchical PFL (HPFL), an algorithm for deploying PFL over massive MEC networks. The UEs in HPFL are divided into multiple clusters, and the UEs in each cluster forward their local updates to the edge server (ES) synchronously for edge model aggregation, while the ESs forward their edge models to the cloud server semi-asynchronously for global model aggregation. The above training manner leads to a tradeoff between the training loss in each round and the round latency. HPFL combines the objectives of training loss minimization and round latency minimization while jointly determining the optimal bandwidth allocation as well as the ES scheduling policy in the hierarchical learning framework. Extensive experiments verify that HPFL not only guarantees convergence in hierarchical aggregation frameworks but also has advantages in round training loss maximization and round latency minimization.
FIRE: A Failure-Adaptive Reinforcement Learning Framework for Edge Computing Migrations
Sep 28, 2022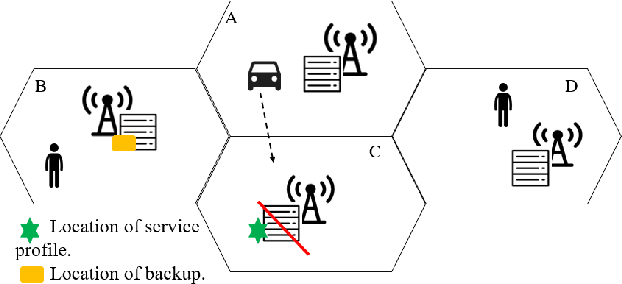
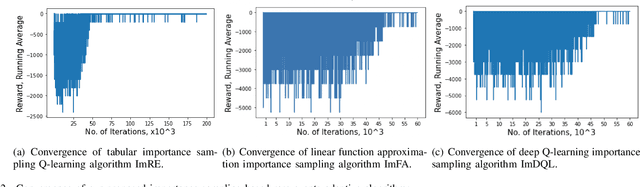
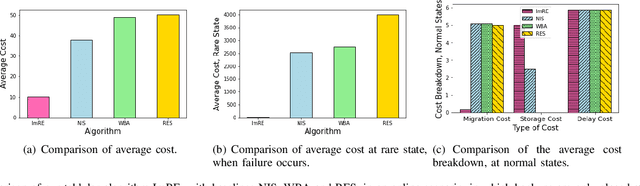
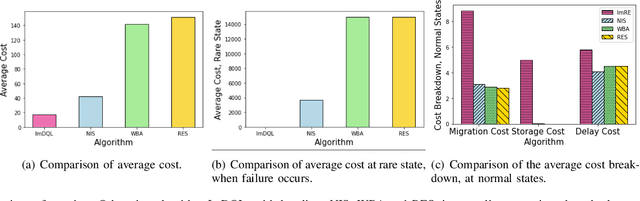
In edge computing, users' service profiles must be migrated in response to user mobility. Reinforcement learning (RL) frameworks have been proposed to do so. Nevertheless, these frameworks do not consider occasional server failures, which although rare, can prevent the smooth and safe functioning of edge computing users' latency sensitive applications such as autonomous driving and real-time obstacle detection, because users' computing jobs can no longer be completed. As these failures occur at a low probability, it is difficult for RL algorithms, which are inherently data-driven, to learn an optimal service migration solution for both the typical and rare event scenarios. Therefore, we introduce a rare events adaptive resilience framework FIRE, which integrates importance sampling into reinforcement learning to place backup services. We sample rare events at a rate proportional to their contribution to the value function, to learn an optimal policy. Our framework balances service migration trade-offs between delay and migration costs, with the costs of failure and the costs of backup placement and migration. We propose an importance sampling based Q-learning algorithm, and prove its boundedness and convergence to optimality. Following which we propose novel eligibility traces, linear function approximation and deep Q-learning versions of our algorithm to ensure it scales to real-world scenarios. We extend our framework to cater to users with different risk tolerances towards failure. Finally, we use trace driven experiments to show that our algorithm gives cost reductions in the event of failures.