 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Deep Neural Network Training via Distributed Hybrid Order Optimization
May 02, 2025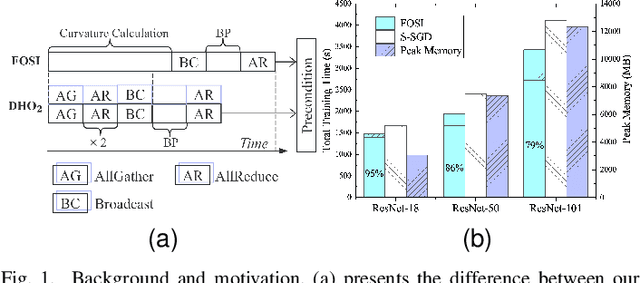
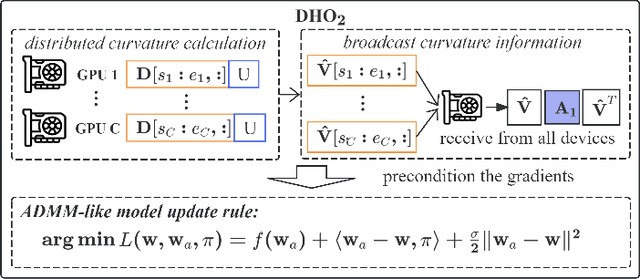
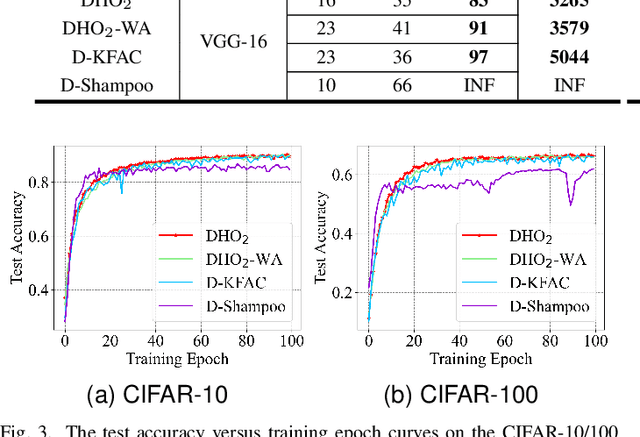
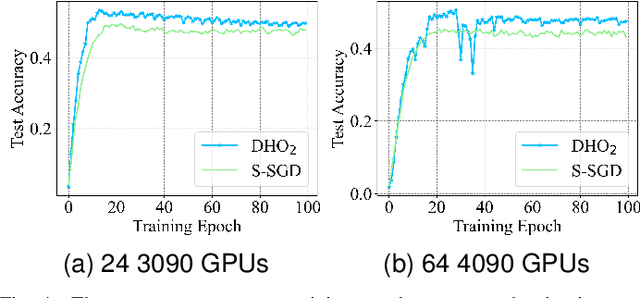
Scaling deep neural network (DNN) training to more devices can reduce time-to-solution. However, it is impractical for users with limited computing resources. FOSI, as a hybrid order optimizer, converges faster than conventional optimizers by taking advantage of both gradient information and curvature information when updating the DNN model. Therefore, it provides a new chance for accelerating DNN training in the resource-constrained setting. In this paper, we explore its distributed design, namely DHO$_2$, including distributed calculation of curvature information and model update with partial curvature information to accelerate DNN training with a low memory burden. To further reduce the training time, we design a novel strategy to parallelize the calculation of curvature information and the model update on different devices. Experimentally, our distributed design can achieve an approximate linear reduction of memory burden on each device with the increase of the device number. Meanwhile, it achieves $1.4\times\sim2.1\times$ speedup in the total training time compared with other distributed designs based on conventional first- and second-order optimizers.
Analytic Personalized Federated Meta-Learning
Feb 10, 2025
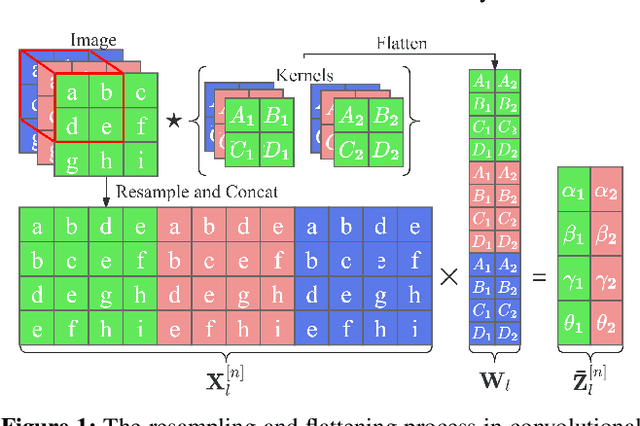
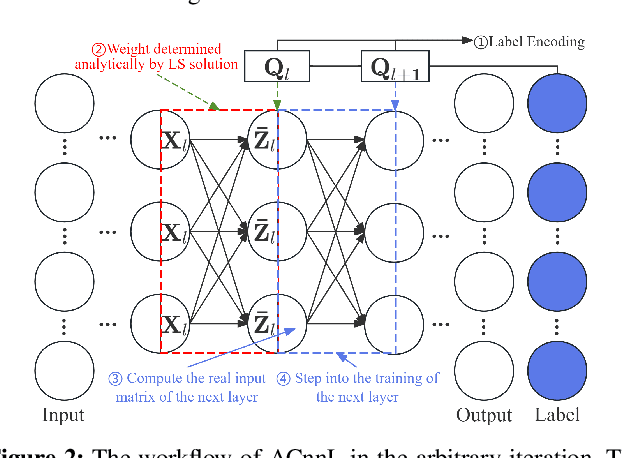

Analytic federated learning (AFL) which updates model weights only once by using closed-form least-square (LS) solutions can reduce abundant training time in gradient-free federated learning (FL). The current AFL framework cannot support deep neural network (DNN) training, which hinders its implementation on complex machine learning tasks. Meanwhile, it overlooks the heterogeneous data distribution problem that restricts the single global model from performing well on each client's task. To overcome the first challenge, we propose an AFL framework, namely FedACnnL, in which we resort to a novel local analytic learning method (ACnnL) and model the training of each layer as a distributed LS problem. For the second challenge, we propose an analytic personalized federated meta-learning framework, namely pFedACnnL, which is inherited from FedACnnL. In pFedACnnL, clients with similar data distribution share a common robust global model for fast adapting it to local tasks in an analytic manner. FedACnnL is theoretically proven to require significantly shorter training time than the conventional zeroth-order (i.e. gradient-free) FL frameworks on DNN training while the reduction ratio is $98\%$ in the experiment. Meanwhile, pFedACnnL achieves state-of-the-art (SOTA) model performance in most cases of convex and non-convex settings, compared with the previous SOTA frameworks.
Communication-Efficient Federated Learning by Quantized Variance Reduction for Heterogeneous Wireless Edge Networks
Jan 20, 2025



Federated learning (FL) has been recognized as a viable solution for local-privacy-aware collaborative model training in wireless edge networks, but its practical deployment is hindered by the high communication overhead caused by frequent and costly server-device synchronization. Notably, most existing communication-efficient FL algorithms fail to reduce the significant inter-device variance resulting from the prevalent issue of device heterogeneity. This variance severely decelerates algorithm convergence, increasing communication overhead and making it more challenging to achieve a well-performed model. In this paper, we propose a novel communication-efficient FL algorithm, named FedQVR, which relies on a sophisticated variance-reduced scheme to achieve heterogeneity-robustness in the presence of quantized transmission and heterogeneous local updates among active edge devices. Comprehensive theoretical analysis justifies that FedQVR is inherently resilient to device heterogeneity and has a comparable convergence rate even with a small number of quantization bits, yielding significant communication savings. Besides, considering non-ideal wireless channels, we propose FedQVR-E which enhances the convergence of FedQVR by performing joint allocation of bandwidth and quantization bits across devices under constrained transmission delays. Extensive experimental results are also presented to demonstrate the superior performance of the proposed algorithms over their counterparts in terms of both communication efficiency and application performance.
Exploiting Storage for Computing: Computation Reuse in Collaborative Edge Computing
Jan 08, 2024Collaborative Edge Computing (CEC) is a new edge computing paradigm that enables neighboring edge servers to share computational resources with each other. Although CEC can enhance the utilization of computational resources, it still suffers from resource waste. The primary reason is that end-users from the same area are likely to offload similar tasks to edge servers, thereby leading to duplicate computations. To improve system efficiency, the computation results of previously executed tasks can be cached and then reused by subsequent tasks. However, most existing computation reuse algorithms only consider one edge server, which significantly limits the effectiveness of computation reuse. To address this issue, this paper applies computation reuse in CEC networks to exploit the collaboration among edge servers. We formulate an optimization problem that aims to minimize the overall task response time and decompose it into a caching subproblem and a scheduling subproblem. By analyzing the properties of optimal solutions, we show that the optimal caching decisions can be efficiently searched using the bisection method. For the scheduling subproblem, we utilize projected gradient descent and backtracking to find a local minimum. Numerical results show that our algorithm significantly reduces the response time in various situations.
Age-Based Scheduling for Mobile Edge Computing: A Deep Reinforcement Learning Approach
Dec 01, 2023With the rapid development of Mobile Edge Computing (MEC), various real-time applications have been deployed to benefit people's daily lives. The performance of these applications relies heavily on the freshness of collected environmental information, which can be quantified by its Age of Information (AoI). In the traditional definition of AoI, it is assumed that the status information can be actively sampled and directly used. However, for many MEC-enabled applications, the desired status information is updated in an event-driven manner and necessitates data processing. To better serve these applications, we propose a new definition of AoI and, based on the redefined AoI, we formulate an online AoI minimization problem for MEC systems. Notably, the problem can be interpreted as a Markov Decision Process (MDP), thus enabling its solution through Reinforcement Learning (RL) algorithms. Nevertheless, the traditional RL algorithms are designed for MDPs with completely unknown system dynamics and hence usually suffer long convergence times. To accelerate the learning process, we introduce Post-Decision States (PDSs) to exploit the partial knowledge of the system's dynamics. We also combine PDSs with deep RL to further improve the algorithm's applicability, scalability, and robustness. Numerical results demonstrate that our algorithm outperforms the benchmarks under various scenarios.
Automated Federated Learning in Mobile Edge Networks -- Fast Adaptation and Convergence
Mar 23, 2023
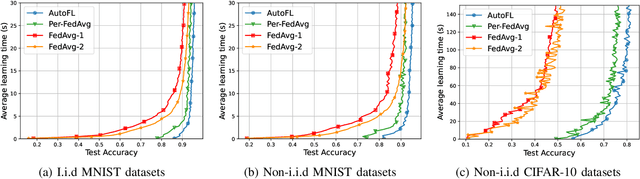
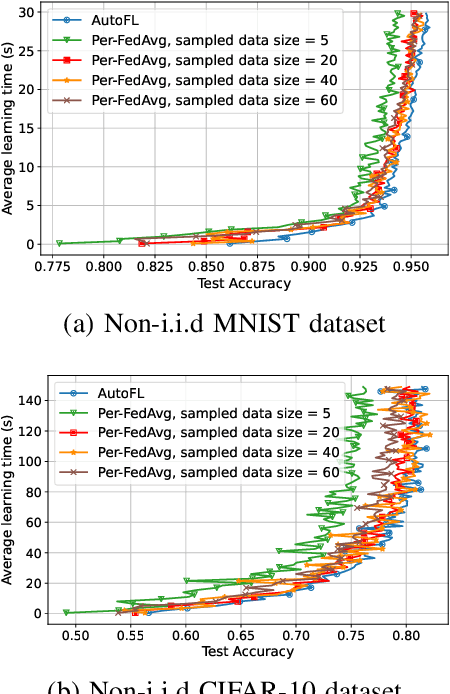
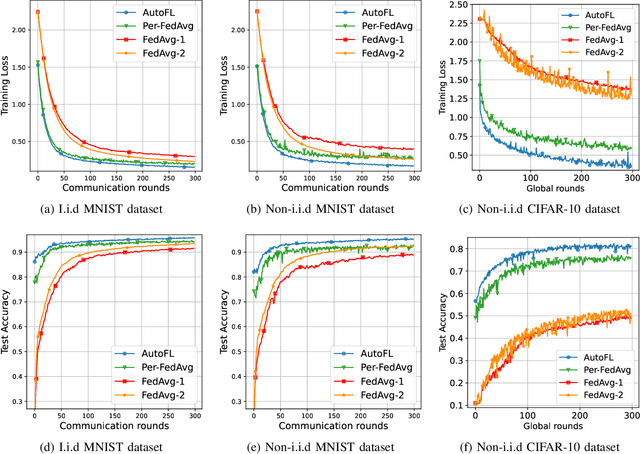
Federated Learning (FL) can be used in mobile edge networks to train machine learning models in a distributed manner. Recently, FL has been interpreted within a Model-Agnostic Meta-Learning (MAML) framework, which brings FL significant advantages in fast adaptation and convergence over heterogeneous datasets. However, existing research simply combines MAML and FL without explicitly addressing how much benefit MAML brings to FL and how to maximize such benefit over mobile edge networks. In this paper, we quantify the benefit from two aspects: optimizing FL hyperparameters (i.e., sampled data size and the number of communication rounds) and resource allocation (i.e., transmit power) in mobile edge networks. Specifically, we formulate the MAML-based FL design as an overall learning time minimization problem, under the constraints of model accuracy and energy consumption. Facilitated by the convergence analysis of MAML-based FL, we decompose the formulated problem and then solve it using analytical solutions and the coordinate descent method. With the obtained FL hyperparameters and resource allocation, we design a MAML-based FL algorithm, called Automated Federated Learning (AutoFL), that is able to conduct fast adaptation and convergence. Extensive experimental results verify that AutoFL outperforms other benchmark algorithms regarding the learning time and convergence performance.
Hierarchical Personalized Federated Learning Over Massive Mobile Edge Computing Networks
Mar 19, 2023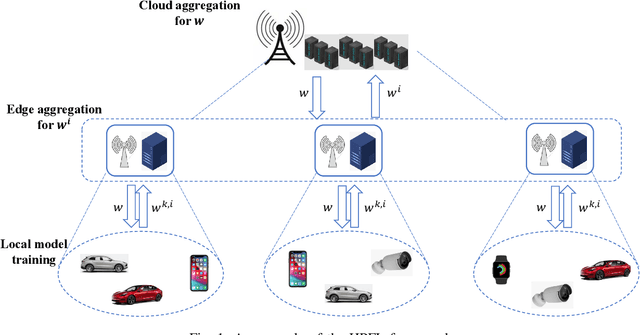
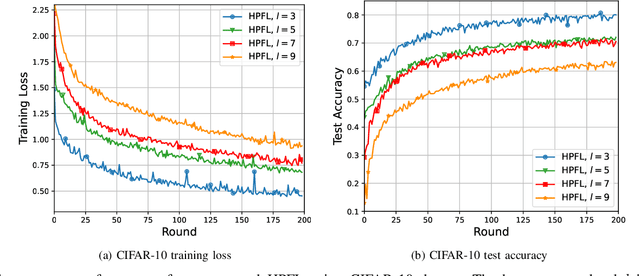
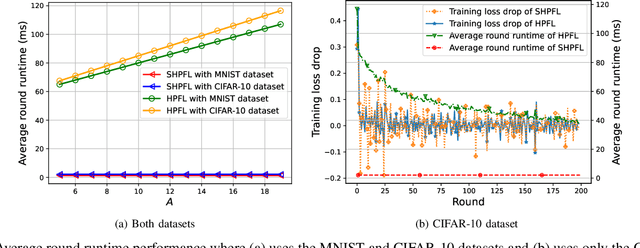
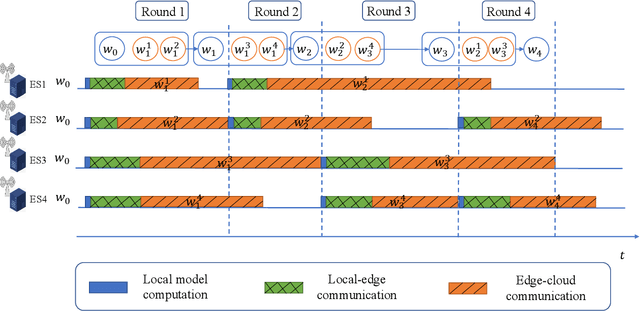
Personalized Federated Learning (PFL) is a new Federated Learning (FL) paradigm, particularly tackling the heterogeneity issues brought by various mobile user equipments (UEs) in mobile edge computing (MEC) networks. However, due to the ever-increasing number of UEs and the complicated administrative work it brings, it is desirable to switch the PFL algorithm from its conventional two-layer framework to a multiple-layer one. In this paper, we propose hierarchical PFL (HPFL), an algorithm for deploying PFL over massive MEC networks. The UEs in HPFL are divided into multiple clusters, and the UEs in each cluster forward their local updates to the edge server (ES) synchronously for edge model aggregation, while the ESs forward their edge models to the cloud server semi-asynchronously for global model aggregation. The above training manner leads to a tradeoff between the training loss in each round and the round latency. HPFL combines the objectives of training loss minimization and round latency minimization while jointly determining the optimal bandwidth allocation as well as the ES scheduling policy in the hierarchical learning framework. Extensive experiments verify that HPFL not only guarantees convergence in hierarchical aggregation frameworks but also has advantages in round training loss maximization and round latency minimization.
Semi-Synchronous Personalized Federated Learning over Mobile Edge Networks
Sep 27, 2022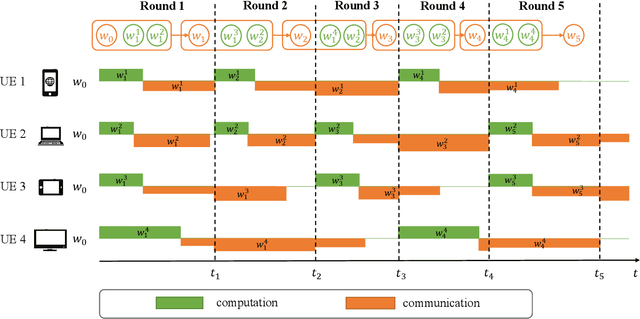
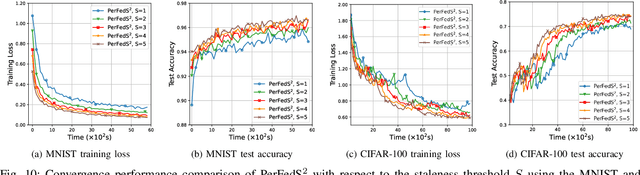
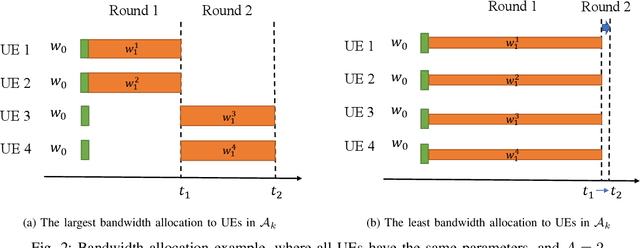
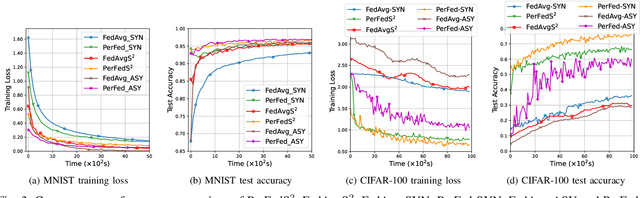
Personalized Federated Learning (PFL) is a new Federated Learning (FL) approach to address the heterogeneity issue of the datasets generated by distributed user equipments (UEs). However, most existing PFL implementations rely on synchronous training to ensure good convergence performances, which may lead to a serious straggler problem, where the training time is heavily prolonged by the slowest UE. To address this issue, we propose a semi-synchronous PFL algorithm, termed as Semi-Synchronous Personalized FederatedAveraging (PerFedS$^2$), over mobile edge networks. By jointly optimizing the wireless bandwidth allocation and UE scheduling policy, it not only mitigates the straggler problem but also provides convergent training loss guarantees. We derive an upper bound of the convergence rate of PerFedS2 in terms of the number of participants per global round and the number of rounds. On this basis, the bandwidth allocation problem can be solved using analytical solutions and the UE scheduling policy can be obtained by a greedy algorithm. Experimental results verify the effectiveness of PerFedS2 in saving training time as well as guaranteeing the convergence of training loss, in contrast to synchronous and asynchronous PFL algorithms.