 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeveloping Foundation Models for Universal Segmentation from 3D Whole-Body Positron Emission Tomography
Mar 12, 2026Positron emission tomography (PET) is a key nuclear medicine imaging modality that visualizes radiotracer distributions to quantify in vivo physiological and metabolic processes, playing an irreplaceable role in disease management. Despite its clinical importance, the development of deep learning models for quantitative PET image analysis remains severely limited, driven by both the inherent segmentation challenge from PET's paucity of anatomical contrast and the high costs of data acquisition and annotation. To bridge this gap, we develop generalist foundational models for universal segmentation from 3D whole-body PET imaging. We first build the largest and most comprehensive PET dataset to date, comprising 11041 3D whole-body PET scans with 59831 segmentation masks for model development. Based on this dataset, we present SegAnyPET, an innovative foundational model with general-purpose applicability to diverse segmentation tasks. Built on a 3D architecture with a prompt engineering strategy for mask generation, SegAnyPET enables universal and scalable organ and lesion segmentation, supports efficient human correction with minimal effort, and enables a clinical human-in-the-loop workflow. Extensive evaluations on multi-center, multi-tracer, multi-disease datasets demonstrate that SegAnyPET achieves strong zero-shot performance across a wide range of segmentation tasks, highlighting its potential to advance the clinical applications of molecular imaging.
Uncovering Modality Discrepancy and Generalization Illusion for General-Purpose 3D Medical Segmentation
Feb 07, 2026While emerging 3D medical foundation models are envisioned as versatile tools with offer general-purpose capabilities, their validation remains largely confined to regional and structural imaging, leaving a significant modality discrepancy unexplored. To provide a rigorous and objective assessment, we curate the UMD dataset comprising 490 whole-body PET/CT and 464 whole-body PET/MRI scans ($\sim$675k 2D images, $\sim$12k 3D organ annotations) and conduct a thorough and comprehensive evaluation of representative 3D segmentation foundation models. Through intra-subject controlled comparisons of paired scans, we isolate imaging modality as the primary independent variable to evaluate model robustness in real-world applications. Our evaluation reveals a stark discrepancy between literature-reported benchmarks and real-world efficacy, particularly when transitioning from structural to functional domains. Such systemic failures underscore that current 3D foundation models are far from achieving truly general-purpose status, necessitating a paradigm shift toward multi-modal training and evaluation to bridge the gap between idealized benchmarking and comprehensive clinical utility. This dataset and analysis establish a foundational cornerstone for future research to develop truly modality-agnostic medical foundation models.
PET2Rep: Towards Vision-Language Model-Drived Automated Radiology Report Generation for Positron Emission Tomography
Aug 06, 2025Positron emission tomography (PET) is a cornerstone of modern oncologic and neurologic imaging, distinguished by its unique ability to illuminate dynamic metabolic processes that transcend the anatomical focus of traditional imaging technologies. Radiology reports are essential for clinical decision making, yet their manual creation is labor-intensive and time-consuming. Recent advancements of vision-language models (VLMs) have shown strong potential in medical applications, presenting a promising avenue for automating report generation. However, existing applications of VLMs in the medical domain have predominantly focused on structural imaging modalities, while the unique characteristics of molecular PET imaging have largely been overlooked. To bridge the gap, we introduce PET2Rep, a large-scale comprehensive benchmark for evaluation of general and medical VLMs for radiology report generation for PET images. PET2Rep stands out as the first dedicated dataset for PET report generation with metabolic information, uniquely capturing whole-body image-report pairs that cover dozens of organs to fill the critical gap in existing benchmarks and mirror real-world clinical comprehensiveness. In addition to widely recognized natural language generation metrics, we introduce a series of clinical efficiency metrics to evaluate the quality of radiotracer uptake pattern description in key organs in generated reports. We conduct a head-to-head comparison of 30 cutting-edge general-purpose and medical-specialized VLMs. The results show that the current state-of-the-art VLMs perform poorly on PET report generation task, falling considerably short of fulfilling practical needs. Moreover, we identify several key insufficiency that need to be addressed to advance the development in medical applications.
TrustFed: A Reliable Federated Learning Framework with Malicious-Attack Resistance
Dec 06, 2023As a key technology in 6G research, federated learning (FL) enables collaborative learning among multiple clients while ensuring individual data privacy. However, malicious attackers among the participating clients can intentionally tamper with the training data or the trained model, compromising the accuracy and trustworthiness of the system. To address this issue, in this paper, we propose a hierarchical audit-based FL (HiAudit-FL) framework, with the aim to enhance the reliability and security of the learning process. The hierarchical audit process includes two stages, namely model-audit and parameter-audit. In the model-audit stage, a low-overhead audit method is employed to identify suspicious clients. Subsequently, in the parameter-audit stage, a resource-consuming method is used to detect all malicious clients with higher accuracy among the suspicious ones. Specifically, we execute the model audit method among partial clients for multiple rounds, which is modeled as a partial observation Markov decision process (POMDP) with the aim to enhance the robustness and accountability of the decision-making in complex and uncertain environments. Meanwhile, we formulate the problem of identifying malicious attackers through a multi-round audit as an active sequential hypothesis testing problem and leverage a diffusion model-based AI-Enabled audit selection strategy (ASS) to decide which clients should be audited in each round. To accomplish efficient and effective audit selection, we design a DRL-ASS algorithm by incorporating the ASS in a deep reinforcement learning (DRL) framework. Our simulation results demonstrate that HiAudit-FL can effectively identify and handle potential malicious users accurately, with small system overhead.
A study on the Lombard Effect in telepresence robotics
May 30, 2023In this study, we present a new experiment in order to study the Lombard effect in telepresence robotics. In this experiment, one person talks with a robot controled remotely by someone in a different room. The remote pilot (R) is immersed in both environments, while the local interlocutor (L) interacts directly with the robot. In this context, the position of the noise source, in the remote or in the local room, may modify the subjects' voice adaptations. In order to study in details this phenomenon, we propose four particular conditions: no added noise, noise in room R heard only by R, virtual noise in room L heard only by R, and noise in room L heard by both R and L. We measured the variations of maximum intensity in order to quantify the Lombard effect. Our results show that there is indeed a modification of voice intensity in all noisy conditions. However, the amplitude of this modification varies depending on the condition.
Towards a model of "social touch'' for ubiquitous communication
May 30, 2023One of the challenges of telepresence robotics is to provide ubiquitous social-interpersonalimmersion. In order to achieve this, there is a need to understand and model the factors that wouldallow the users to control the transmission of their vocal productions, and to give them perception,proprioception and inter-proprioception of this control. This model for transferring sociallyembodied vocal distance should take into account all parameters involved in the social-interpersonaleffect of vocal productions, especially intensity. It should also integrate the background informationwhich is relevant for the speakers to express their intentions. In this paper, we present a firstexperiment for measuring, analyzing and modeling how human beings perceive the distance to aninterlocutor, depending on socio-affective variations in the vocal productions of this interlocutor.These results will be the reference for the models which will be implanted in our telepresence robot:Robair Social Touch.
* in French language
Can we hear physical and social space together through prosody?
May 22, 2023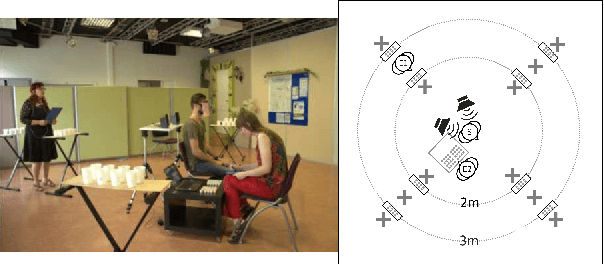
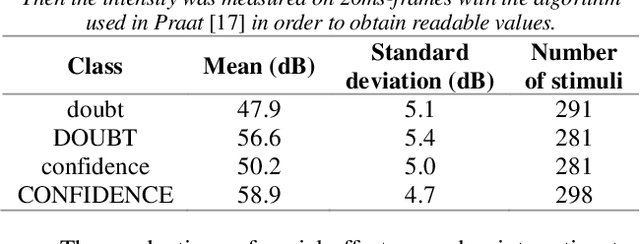

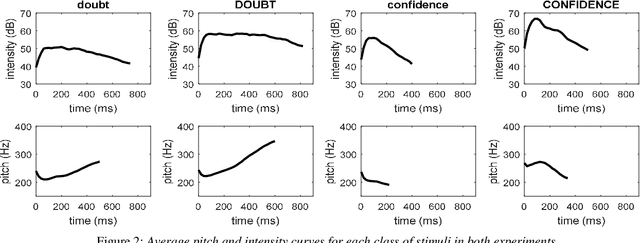
When human listeners try to guess the spatial position of a speech source, they are influenced by the speaker's production level, regardless of the intensity level reaching their ears. Because the perception of distance is a very difficult task, they rely on their own experience, which tells them that a whispering talker is close to them, and that a shouting talker is far away. This study aims to test if similar results could be obtained for prosodic variations produced by a human speaker in an everyday life environment. It consists in a localization task, during which blindfolded subjects had to estimate the incoming voice direction, speaker orientation and distance of a trained female speaker, who uttered single words, following instructions concerning intensity and social-affect to be performed. This protocol was implemented in two experiments. First, a complex pretext task was used in order to distract the subjects from the strange behavior of the speaker. On the contrary, during the second experiment, the subjects were fully aware of the prosodic variations, which allowed them to adapt their perception. Results show the importance of the pretext task, and suggest that the perception of the speaker's orientation can be influenced by voice intensity.
Automated Federated Learning in Mobile Edge Networks -- Fast Adaptation and Convergence
Mar 23, 2023
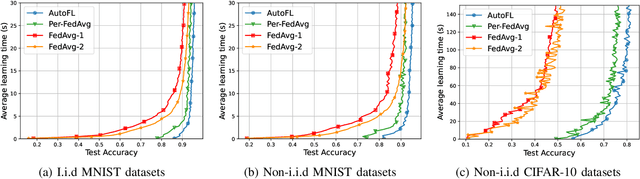
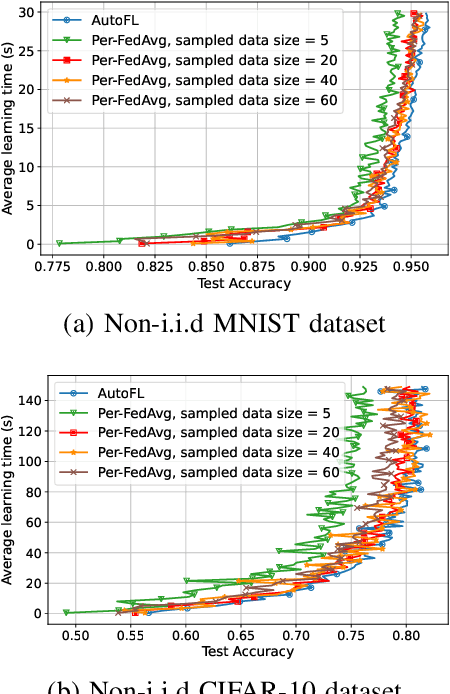
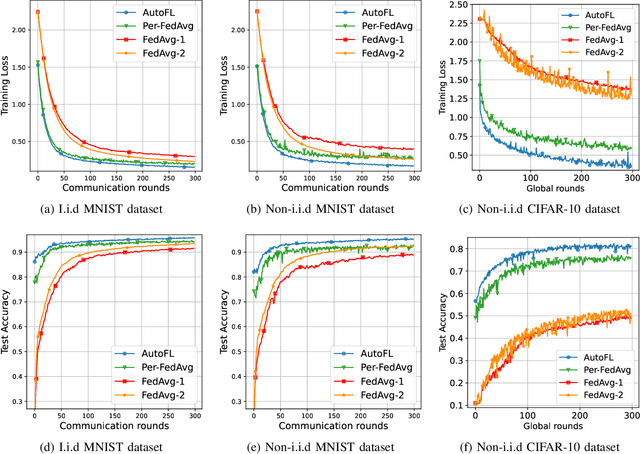
Federated Learning (FL) can be used in mobile edge networks to train machine learning models in a distributed manner. Recently, FL has been interpreted within a Model-Agnostic Meta-Learning (MAML) framework, which brings FL significant advantages in fast adaptation and convergence over heterogeneous datasets. However, existing research simply combines MAML and FL without explicitly addressing how much benefit MAML brings to FL and how to maximize such benefit over mobile edge networks. In this paper, we quantify the benefit from two aspects: optimizing FL hyperparameters (i.e., sampled data size and the number of communication rounds) and resource allocation (i.e., transmit power) in mobile edge networks. Specifically, we formulate the MAML-based FL design as an overall learning time minimization problem, under the constraints of model accuracy and energy consumption. Facilitated by the convergence analysis of MAML-based FL, we decompose the formulated problem and then solve it using analytical solutions and the coordinate descent method. With the obtained FL hyperparameters and resource allocation, we design a MAML-based FL algorithm, called Automated Federated Learning (AutoFL), that is able to conduct fast adaptation and convergence. Extensive experimental results verify that AutoFL outperforms other benchmark algorithms regarding the learning time and convergence performance.
Beam Management in Ultra-dense mmWave Network via Federated Reinforcement Learning: An Intelligent and Secure Approach
Oct 04, 2022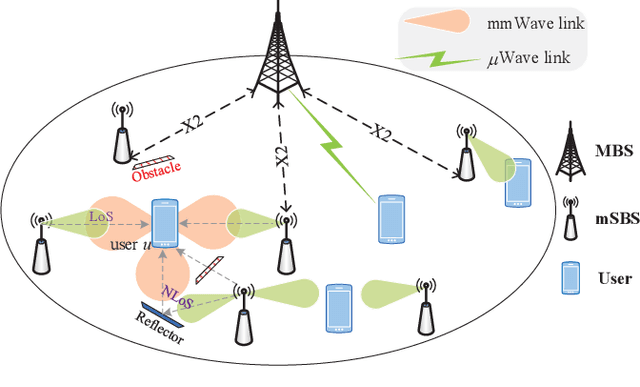
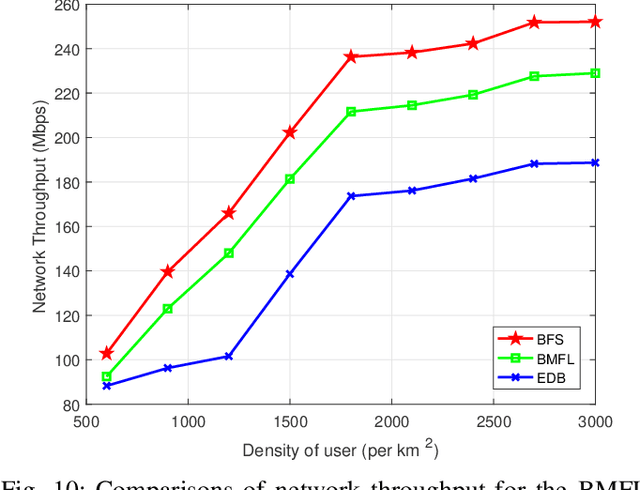
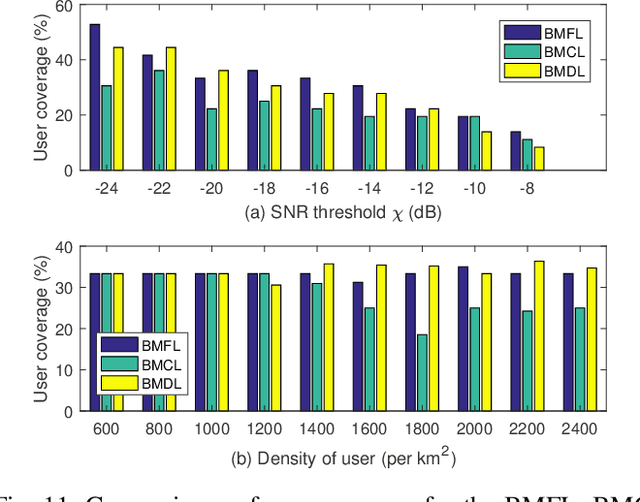
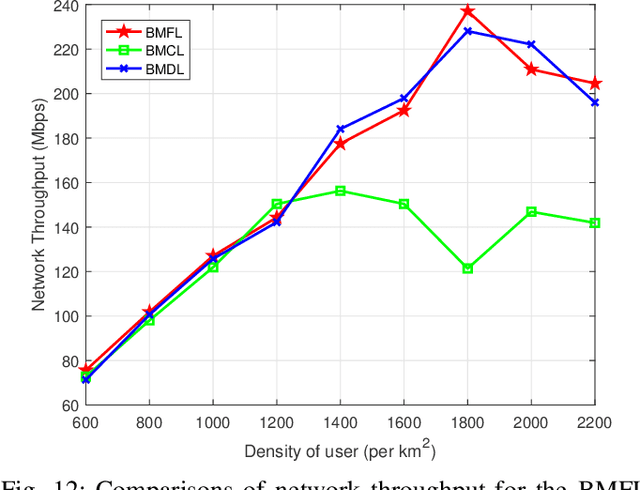
Deploying ultra-dense networks that operate on millimeter wave (mmWave) band is a promising way to address the tremendous growth on mobile data traffic. However, one key challenge of ultra-dense mmWave network (UDmmN) is beam management due to the high propagation delay, limited beam coverage as well as numerous beams and users. In this paper, a novel systematic beam control scheme is presented to tackle the beam management problem which is difficult due to the nonconvex objective function. We employ double deep Q-network (DDQN) under a federated learning (FL) framework to address the above optimization problem, and thereby fulfilling adaptive and intelligent beam management in UDmmN. In the proposed beam management scheme based on FL (BMFL), the non-rawdata aggregation can theoretically protect user privacy while reducing handoff cost. Moreover, we propose to adopt a data cleaning technique in the local model training for BMFL, with the aim to further strengthen the privacy protection of users while improving the learning convergence speed. Simulation results demonstrate the performance gain of our proposed scheme.
Wireless Resource Management in Intelligent Semantic Communication Networks
Feb 15, 2022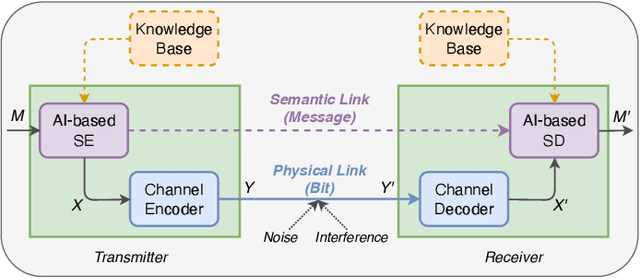
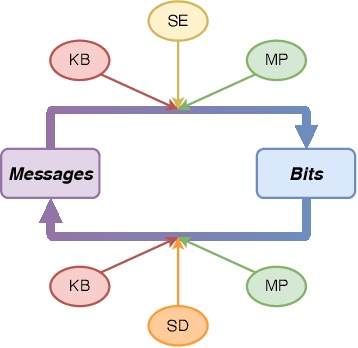
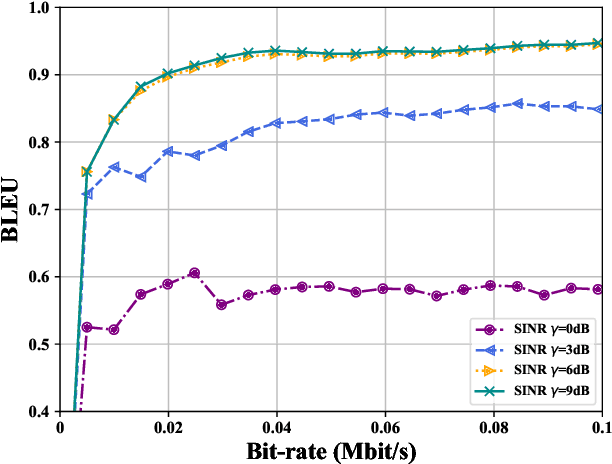
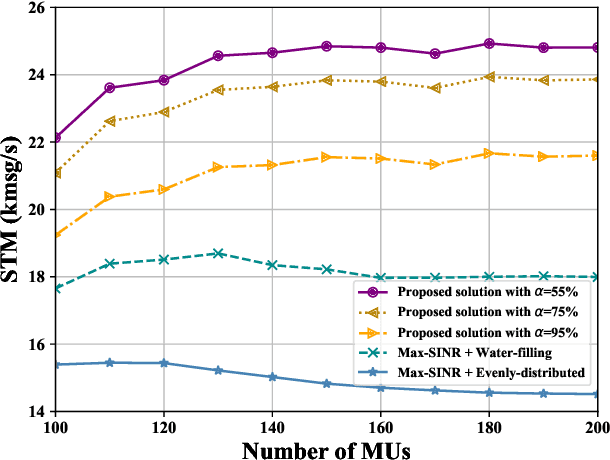
The prosperity of artificial intelligence (AI) has laid a promising paradigm of communication system, i.e., intelligent semantic communication (ISC), where semantic contents, instead of traditional bit sequences, are coded by AI models for efficient communication. Due to the unique demand of background knowledge for semantic recovery, wireless resource management faces new challenges in ISC. In this paper, we address the user association (UA) and bandwidth allocation (BA) problems in an ISC-enabled heterogeneous network (ISC-HetNet). We first introduce the auxiliary knowledge base (KB) into the system model, and develop a new performance metric for the ISC-HetNet, named system throughput in message (STM). Joint optimization of UA and BA is then formulated with the aim of STM maximization subject to KB matching and wireless bandwidth constraints. To this end, we propose a two-stage solution, including a stochastic programming method in the first stage to obtain a deterministic objective with semantic confidence, and a heuristic algorithm in the second stage to reach the optimality of UA and BA. Numerical results show great superiority and reliability of our proposed solution on the STM performance when compared with two baseline algorithms.