 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM Agent for Hyper-Parameter Optimization
Jun 18, 2025



Hyper-parameters are essential and critical for the performance of communication algorithms. However, current hyper-parameters tuning methods for warm-start particles swarm optimization with cross and mutation (WS-PSO-CM) algortihm for radio map-enabled unmanned aerial vehicle (UAV) trajectory and communication are primarily heuristic-based, exhibiting low levels of automation and unsatisfactory performance. In this paper, we design an large language model (LLM) agent for automatic hyper-parameters-tuning, where an iterative framework and model context protocol (MCP) are applied. In particular, the LLM agent is first setup via a profile, which specifies the mission, background, and output format. Then, the LLM agent is driven by the prompt requirement, and iteratively invokes WS-PSO-CM algorithm for exploration. Finally, the LLM agent autonomously terminates the loop and returns a set of hyper-parameters. Our experiment results show that the minimal sum-rate achieved by hyper-parameters generated via our LLM agent is significantly higher than those by both human heuristics and random generation methods. This indicates that an LLM agent with PSO knowledge and WS-PSO-CM algorithm background is useful in finding high-performance hyper-parameters.
Communication-Efficient Federated Learning by Quantized Variance Reduction for Heterogeneous Wireless Edge Networks
Jan 20, 2025



Federated learning (FL) has been recognized as a viable solution for local-privacy-aware collaborative model training in wireless edge networks, but its practical deployment is hindered by the high communication overhead caused by frequent and costly server-device synchronization. Notably, most existing communication-efficient FL algorithms fail to reduce the significant inter-device variance resulting from the prevalent issue of device heterogeneity. This variance severely decelerates algorithm convergence, increasing communication overhead and making it more challenging to achieve a well-performed model. In this paper, we propose a novel communication-efficient FL algorithm, named FedQVR, which relies on a sophisticated variance-reduced scheme to achieve heterogeneity-robustness in the presence of quantized transmission and heterogeneous local updates among active edge devices. Comprehensive theoretical analysis justifies that FedQVR is inherently resilient to device heterogeneity and has a comparable convergence rate even with a small number of quantization bits, yielding significant communication savings. Besides, considering non-ideal wireless channels, we propose FedQVR-E which enhances the convergence of FedQVR by performing joint allocation of bandwidth and quantization bits across devices under constrained transmission delays. Extensive experimental results are also presented to demonstrate the superior performance of the proposed algorithms over their counterparts in terms of both communication efficiency and application performance.
Downlink MIMO Channel Estimation from Bits: Recoverability and Algorithm
Nov 25, 2024



In frequency division duplex (FDD) massive MIMO systems, a major challenge lies in acquiring the downlink channel state information}\ (CSI) at the base station (BS) from limited feedback sent by the user equipment (UE). To tackle this fundamental task, our contribution is twofold: First, a simple feedback framework is proposed, where a compression and Gaussian dithering-based quantization strategy is adopted at the UE side, and then a maximum likelihood estimator (MLE) is formulated at the BS side. Recoverability of the MIMO channel under the widely used double directional model is established. Specifically, analyses are presented for two compression schemes -- showing one being more overhead-economical and the other computationally lighter at the UE side. Second, to realize the MLE, an alternating direction method of multipliers (ADMM) algorithm is proposed. The algorithm is carefully designed to integrate a sophisticated harmonic retrieval (HR) solver as subroutine, which turns out to be the key of effectively tackling this hard MLE problem.Extensive numerical experiments are conducted to validate the efficacy of our approach.
Language-Queried Target Sound Extraction Without Parallel Training Data
Sep 14, 2024



Language-queried target sound extraction (TSE) aims to extract specific sounds from mixtures based on language queries. Traditional fully-supervised training schemes require extensively annotated parallel audio-text data, which are labor-intensive. We introduce a language-free training scheme, requiring only unlabelled audio clips for TSE model training by utilizing the multi-modal representation alignment nature of the contrastive language-audio pre-trained model (CLAP). In a vanilla language-free training stage, target audio is encoded using the pre-trained CLAP audio encoder to form a condition embedding for the TSE model, while during inference, user language queries are encoded by CLAP text encoder. This straightforward approach faces challenges due to the modality gap between training and inference queries and information leakage from direct exposure to target audio during training. To address this, we propose a retrieval-augmented strategy. Specifically, we create an embedding cache using audio captions generated by a large language model (LLM). During training, target audio embeddings retrieve text embeddings from this cache to use as condition embeddings, ensuring consistent modalities between training and inference and eliminating information leakage. Extensive experiment results show that our retrieval-augmented approach achieves consistent and notable performance improvements over existing state-of-the-art with better generalizability.
One-Bit MIMO Detection: From Global Maximum-Likelihood Detector to Amplitude Retrieval Approach
Jul 13, 2024As communication systems advance towards the future 6G era, the incorporation of large-scale antenna arrays in base stations (BSs) presents challenges such as increased hardware costs and energy consumption. To address these issues, the use of one-bit analog-to-digital converters (ADCs)/digital-to-analog converters (DACs) has gained significant attentions. This paper focuses on one-bit multiple-input multiple-output (MIMO) detection in an uplink multiuser transmission scenario where the BS employs one-bit ADCs. One-bit quantization retains only the sign information and loses the amplitude information, which poses a unique challenge in the corresponding detection problem. The maximum-likelihood (ML) formulation of one-bit MIMO detection has a challenging likelihood function that hinders the application of many high-performance detectors developed for classic MIMO detection (under high-resolution ADCs). While many approximate methods for the ML detection problem have been studied, it lacks an efficient global algorithm. This paper fills this gap by proposing an efficient branch-and-bound algorithm, which is guaranteed to find the global solution of the one-bit ML MIMO detection problem. Additionally, a new amplitude retrieval (AR) detection approach is developed, incorporating explicit amplitude variables into the problem formulation. The AR approach yields simpler objective functions that enable the development of efficient algorithms offering both global and approximate solutions. The paper also contributes to the computational complexity analysis of both ML and AR detection problems. Extensive simulations are conducted to demonstrate the effectiveness and efficiency of the proposed formulations and algorithms.
An Efficient Algorithm for Sum-Rate Maximization in Fluid Antenna-Assisted ISAC System
May 10, 2024In this letter, we investigate the fluid antenna (FA)-assisted integrated sensing and communication (ISAC) system, where communication and radar sensing employ the co-waveform design. Specifically, we focus on the beamformer design and antenna position configuration to realize a higher communication rate while guaranteeing the minimum radar probing power. Different from existing beamformer algorithms, we propose an efficient proximal distance algorithm (PDA) to solve the multiuser sum-rate maximization problem with radar sensing constraint to obtain the closed-form beamforming vector. In addition, we develop an extrapolated projected gradient (EPG) algorithm to obtain a better antenna location configuration for FA to enhance the ISAC performance. Numerical results show that the considered FA-assisted ISAC system enjoys a higher sum-rate by the proposed algorithm, compared with that in existing non-FA ISAC systems.
Extreme Point Pursuit -- Part II: Further Error Bound Analysis and Applications
Mar 11, 2024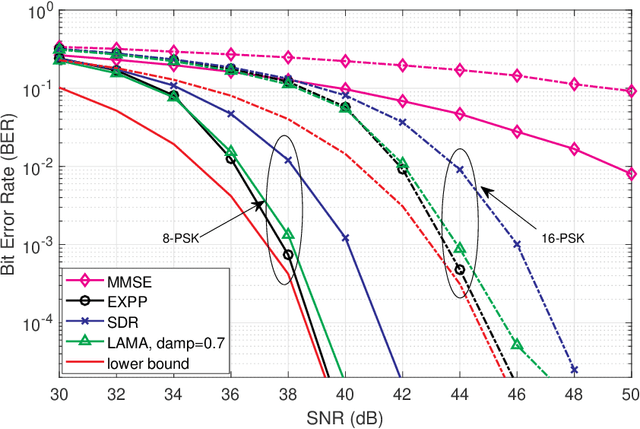
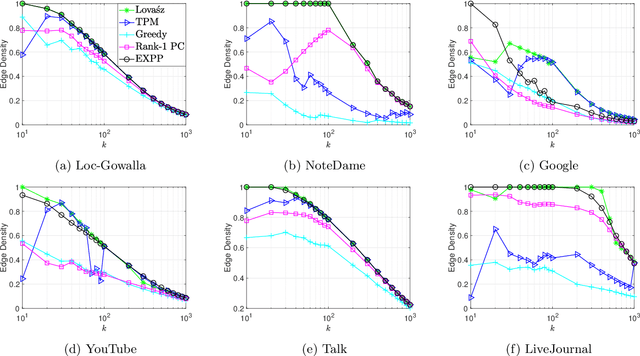
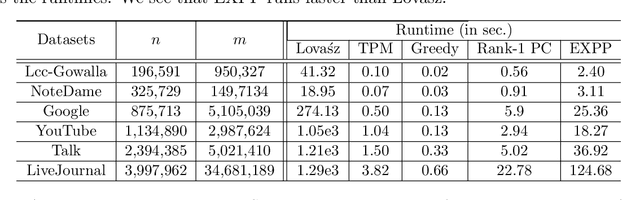
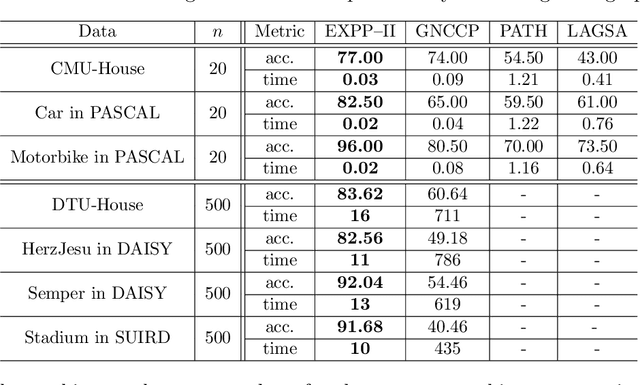
In the first part of this study, a convex-constrained penalized formulation was studied for a class of constant modulus (CM) problems. In particular, the error bound techniques were shown to play a vital role in providing exact penalization results. In this second part of the study, we continue our error bound analysis for the cases of partial permutation matrices, size-constrained assignment matrices and non-negative semi-orthogonal matrices. We develop new error bounds and penalized formulations for these three cases, and the new formulations possess good structures for building computationally efficient algorithms. Moreover, we provide numerical results to demonstrate our framework in a variety of applications such as the densest k-subgraph problem, graph matching, size-constrained clustering, non-negative orthogonal matrix factorization and sparse fair principal component analysis.
Extreme Point Pursuit -- Part I: A Framework for Constant Modulus Optimization
Mar 11, 2024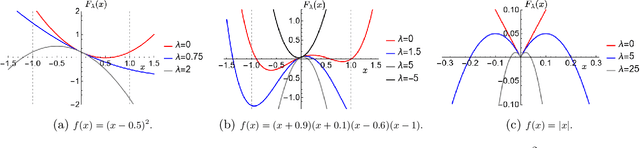
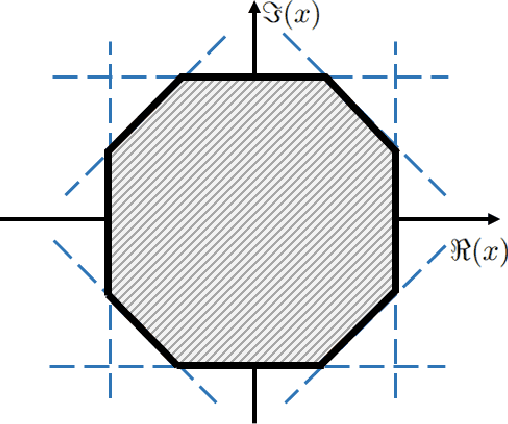
This study develops a framework for a class of constant modulus (CM) optimization problems, which covers binary constraints, discrete phase constraints, semi-orthogonal matrix constraints, non-negative semi-orthogonal matrix constraints, and several types of binary assignment constraints. Capitalizing on the basic principles of concave minimization and error bounds, we study a convex-constrained penalized formulation for general CM problems. The advantage of such formulation is that it allows us to leverage non-convex optimization techniques, such as the simple projected gradient method, to build algorithms. As the first part of this study, we explore the theory of this framework. We study conditions under which the formulation provides exact penalization results. We also examine computational aspects relating to the use of the projected gradient method for each type of CM constraint. Our study suggests that the proposed framework has a broad scope of applicability.
CLAPSep: Leveraging Contrastive Pre-trained Models for Multi-Modal Query-Conditioned Target Sound Extraction
Feb 27, 2024



Universal sound separation (USS) aims to extract arbitrary types of sounds from real-world sound recordings. Language-queried target sound extraction (TSE) is an effective approach to achieving USS. Such systems consist of two components: a query network that converts user queries into conditional embeddings, and a separation network that extracts the target sound based on conditional embeddings. Existing methods mainly suffer from two issues: firstly, they require training a randomly initialized model from scratch, lacking the utilization of pre-trained models, and substantial data and computational resources are needed to ensure model convergence; secondly, existing methods need to jointly train a query network and a separation network, which tends to lead to overfitting. To address these issues, we build the CLAPSep model based on contrastive language-audio pre-trained model (CLAP). We achieve this by using a pre-trained text encoder of CLAP as the query network and introducing pre-trained audio encoder weights of CLAP into the separation network to fully utilize the prior knowledge embedded in the pre-trained model to assist in target sound extraction tasks. Extensive experimental results demonstrate that the proposed method saves training resources while ensuring the model's performance and generalizability. Additionally, we explore the model's ability to comprehensively utilize language/audio multi-modal and positive/negative multi-valent user queries, enhancing system performance while providing diversified application modes.
An efficient algorithm for multiuser sum-rate maximization of large-scale active RIS-aided MIMO system
Dec 13, 2023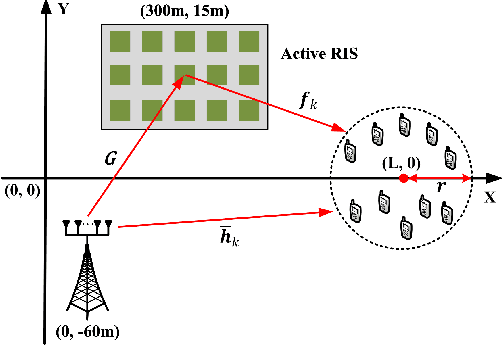
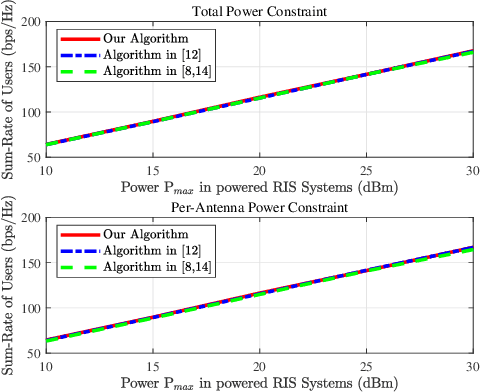
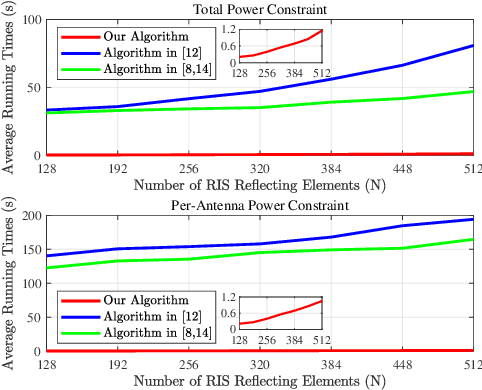
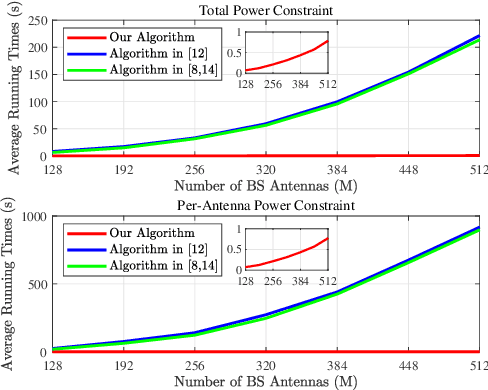
Active reconfigurable intelligent surface (RIS) is a new RIS architecture that can reflect and amplify communication signals. It can provide enhanced performance gain compared to the conventional passive RIS systems that can only reflect the signals. On the other hand, the design problem of active RIS-aided systems is more challenging than the passive RIS-aided systems and its efficient algorithms are less studied. In this paper, we consider the sum rate maximization problem in the multiuser massive multiple-input single-output (MISO) downlink with the aid of a large-scale active RIS. Existing approaches usually resort to general optimization solvers and can be computationally prohibitive in the considered settings. We propose an efficient block successive upper bound minimization (BSUM) method, of which each step has a (semi) closed-form update. Thus, the proposed algorithm has an attractive low per-iteration complexity. By simulation, our proposed algorithm consumes much less computation than the existing approaches. In particular, when the MIMO and/or RIS sizes are large, our proposed algorithm can be orders-of-magnitude faster than existing approaches.