 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Variational Bayes by Min-Max Median Aggregation
Dec 14, 2025We propose a robust and scalable variational Bayes (VB) framework designed to effectively handle contamination and outliers in dataset. Our approach partitions the data into $m$ disjoint subsets and formulates a joint optimization problem based on robust aggregation principles. A key insight is that the full posterior distribution is equivalent to the minimizer of the mean Kullback-Leibler (KL) divergence from the $m$-powered local posterior distributions. To enhance robustness, we replace the mean KL divergence with a min-max median formulation. The min-max formulation not only ensures consistency between the KL minimizer and the Evidence Lower Bound (ELBO) maximizer but also facilitates the establishment of improved statistical rates for the mean of variational posterior. We observe a notable discrepancy in the $m$-powered marginal log likelihood function contingent on the presence of local latent variables. To address this, we treat these two scenarios separately to guarantee the consistency of the aggregated variational posterior. Specifically, when local latent variables are present, we introduce an aggregate-and-rescale strategy. Theoretically, we provide a non-asymptotic analysis of our proposed posterior, incorporating a refined analysis of Bernstein-von Mises (BvM) theorem to accommodate a diverging number of subsets $m$. Our findings indicate that the two-stage approach yields a smaller approximation error compared to directly aggregating the $m$-powered local posteriors. Furthermore, we establish a nearly optimal statistical rate for the mean of the proposed posterior, advancing existing theories related to min-max median estimators. The efficacy of our method is demonstrated through extensive simulation studies.
Efficient Medical Image Restoration via Reliability Guided Learning in Frequency Domain
Apr 15, 2025



Medical image restoration tasks aim to recover high-quality images from degraded observations, exhibiting emergent desires in many clinical scenarios, such as low-dose CT image denoising, MRI super-resolution, and MRI artifact removal. Despite the success achieved by existing deep learning-based restoration methods with sophisticated modules, they struggle with rendering computationally-efficient reconstruction results. Moreover, they usually ignore the reliability of the restoration results, which is much more urgent in medical systems. To alleviate these issues, we present LRformer, a Lightweight Transformer-based method via Reliability-guided learning in the frequency domain. Specifically, inspired by the uncertainty quantification in Bayesian neural networks (BNNs), we develop a Reliable Lesion-Semantic Prior Producer (RLPP). RLPP leverages Monte Carlo (MC) estimators with stochastic sampling operations to generate sufficiently-reliable priors by performing multiple inferences on the foundational medical image segmentation model, MedSAM. Additionally, instead of directly incorporating the priors in the spatial domain, we decompose the cross-attention (CA) mechanism into real symmetric and imaginary anti-symmetric parts via fast Fourier transform (FFT), resulting in the design of the Guided Frequency Cross-Attention (GFCA) solver. By leveraging the conjugated symmetric property of FFT, GFCA reduces the computational complexity of naive CA by nearly half. Extensive experimental results in various tasks demonstrate the superiority of the proposed LRformer in both effectiveness and efficiency.
Enhancing Intelligibility for Generative Target Speech Extraction via Joint Optimization with Target Speaker ASR
Jan 24, 2025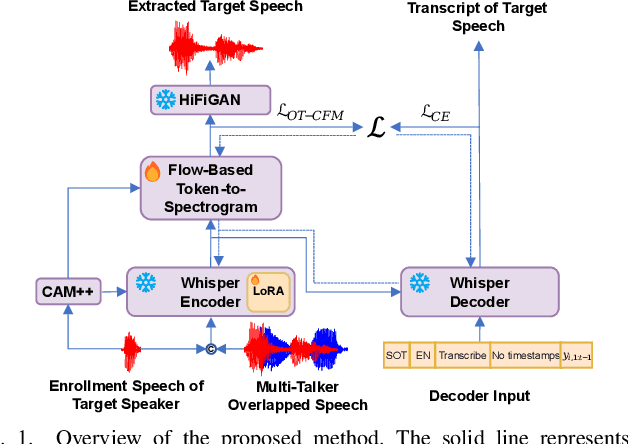
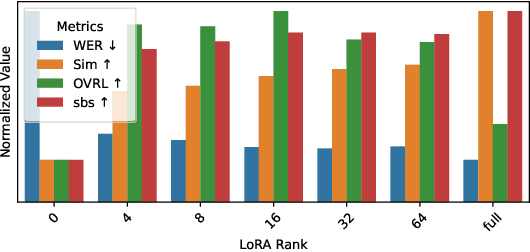
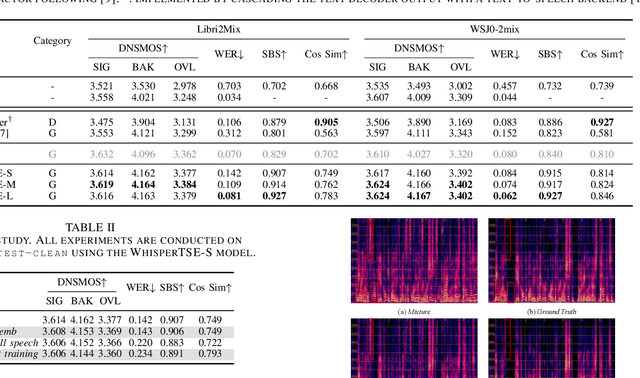
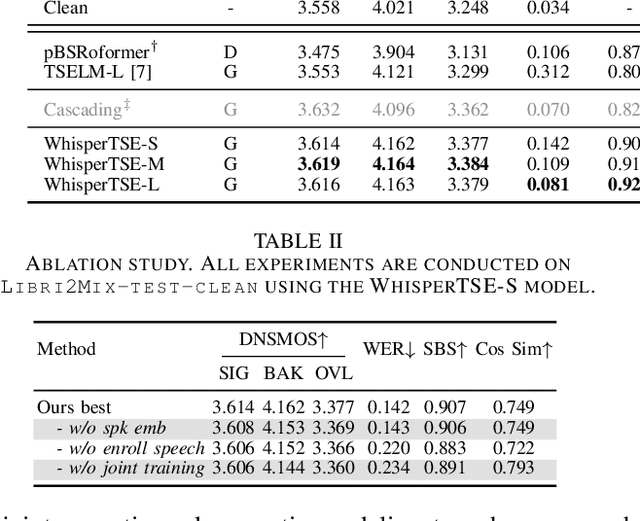
Target speech extraction (TSE) isolates the speech of a specific speaker from a multi-talker overlapped speech mixture. Most existing TSE models rely on discriminative methods, typically predicting a time-frequency spectrogram mask for the target speech. However, imperfections in these masks often result in over-/under-suppression of target/non-target speech, degrading perceptual quality. Generative methods, by contrast, re-synthesize target speech based on the mixture and target speaker cues, achieving superior perceptual quality. Nevertheless, these methods often overlook speech intelligibility, leading to alterations or loss of semantic content in the re-synthesized speech. Inspired by the Whisper model's success in target speaker ASR, we propose a generative TSE framework based on the pre-trained Whisper model to address the above issues. This framework integrates semantic modeling with flow-based acoustic modeling to achieve both high intelligibility and perceptual quality. Results from multiple benchmarks demonstrate that the proposed method outperforms existing generative and discriminative baselines. We present speech samples on our demo page.
Language-Queried Target Sound Extraction Without Parallel Training Data
Sep 14, 2024



Language-queried target sound extraction (TSE) aims to extract specific sounds from mixtures based on language queries. Traditional fully-supervised training schemes require extensively annotated parallel audio-text data, which are labor-intensive. We introduce a language-free training scheme, requiring only unlabelled audio clips for TSE model training by utilizing the multi-modal representation alignment nature of the contrastive language-audio pre-trained model (CLAP). In a vanilla language-free training stage, target audio is encoded using the pre-trained CLAP audio encoder to form a condition embedding for the TSE model, while during inference, user language queries are encoded by CLAP text encoder. This straightforward approach faces challenges due to the modality gap between training and inference queries and information leakage from direct exposure to target audio during training. To address this, we propose a retrieval-augmented strategy. Specifically, we create an embedding cache using audio captions generated by a large language model (LLM). During training, target audio embeddings retrieve text embeddings from this cache to use as condition embeddings, ensuring consistent modalities between training and inference and eliminating information leakage. Extensive experiment results show that our retrieval-augmented approach achieves consistent and notable performance improvements over existing state-of-the-art with better generalizability.
An Efficient Algorithm for Sum-Rate Maximization in Fluid Antenna-Assisted ISAC System
May 10, 2024In this letter, we investigate the fluid antenna (FA)-assisted integrated sensing and communication (ISAC) system, where communication and radar sensing employ the co-waveform design. Specifically, we focus on the beamformer design and antenna position configuration to realize a higher communication rate while guaranteeing the minimum radar probing power. Different from existing beamformer algorithms, we propose an efficient proximal distance algorithm (PDA) to solve the multiuser sum-rate maximization problem with radar sensing constraint to obtain the closed-form beamforming vector. In addition, we develop an extrapolated projected gradient (EPG) algorithm to obtain a better antenna location configuration for FA to enhance the ISAC performance. Numerical results show that the considered FA-assisted ISAC system enjoys a higher sum-rate by the proposed algorithm, compared with that in existing non-FA ISAC systems.
CLAPSep: Leveraging Contrastive Pre-trained Models for Multi-Modal Query-Conditioned Target Sound Extraction
Feb 27, 2024



Universal sound separation (USS) aims to extract arbitrary types of sounds from real-world sound recordings. Language-queried target sound extraction (TSE) is an effective approach to achieving USS. Such systems consist of two components: a query network that converts user queries into conditional embeddings, and a separation network that extracts the target sound based on conditional embeddings. Existing methods mainly suffer from two issues: firstly, they require training a randomly initialized model from scratch, lacking the utilization of pre-trained models, and substantial data and computational resources are needed to ensure model convergence; secondly, existing methods need to jointly train a query network and a separation network, which tends to lead to overfitting. To address these issues, we build the CLAPSep model based on contrastive language-audio pre-trained model (CLAP). We achieve this by using a pre-trained text encoder of CLAP as the query network and introducing pre-trained audio encoder weights of CLAP into the separation network to fully utilize the prior knowledge embedded in the pre-trained model to assist in target sound extraction tasks. Extensive experimental results demonstrate that the proposed method saves training resources while ensuring the model's performance and generalizability. Additionally, we explore the model's ability to comprehensively utilize language/audio multi-modal and positive/negative multi-valent user queries, enhancing system performance while providing diversified application modes.
MVPatch: More Vivid Patch for Adversarial Camouflaged Attacks on Object Detectors in the Physical World
Jan 12, 2024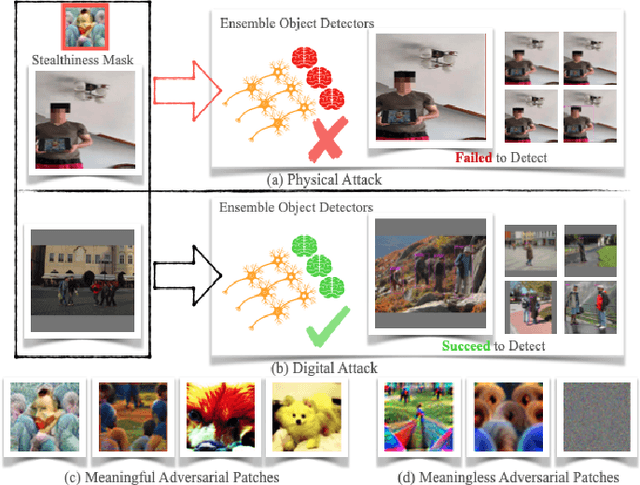
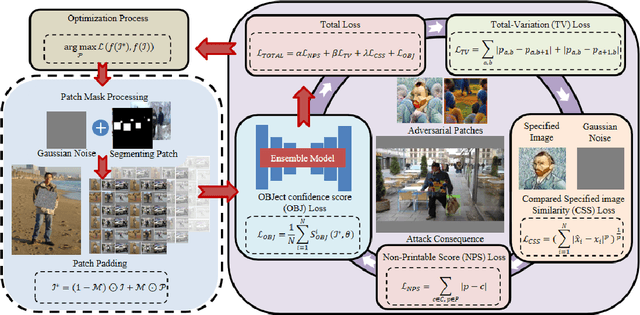


Recent investigations demonstrate that adversarial patches can be utilized to manipulate the result of object detection models. However, the conspicuous patterns on these patches may draw more attention and raise suspicions among humans. Moreover, existing works have primarily focused on enhancing the efficacy of attacks in the physical domain, rather than seeking to optimize their stealth attributes and transferability potential. To address these issues, we introduce a dual-perception-based attack framework that generates an adversarial patch known as the More Vivid Patch (MVPatch). The framework consists of a model-perception degradation method and a human-perception improvement method. To derive the MVPatch, we formulate an iterative process that simultaneously constrains the efficacy of multiple object detectors and refines the visual correlation between the generated adversarial patch and a realistic image. Our method employs a model-perception-based approach that reduces the object confidence scores of several object detectors to boost the transferability of adversarial patches. Further, within the human-perception-based framework, we put forward a lightweight technique for visual similarity measurement that facilitates the development of inconspicuous and natural adversarial patches and eliminates the reliance on additional generative models. Additionally, we introduce the naturalness score and transferability score as metrics for an unbiased assessment of various adversarial patches' natural appearance and transferability capacity. Extensive experiments demonstrate that the proposed MVPatch algorithm achieves superior attack transferability compared to similar algorithms in both digital and physical domains while also exhibiting a more natural appearance. These findings emphasize the remarkable stealthiness and transferability of the proposed MVPatch attack algorithm.
An efficient algorithm for multiuser sum-rate maximization of large-scale active RIS-aided MIMO system
Dec 13, 2023Active reconfigurable intelligent surface (RIS) is a new RIS architecture that can reflect and amplify communication signals. It can provide enhanced performance gain compared to the conventional passive RIS systems that can only reflect the signals. On the other hand, the design problem of active RIS-aided systems is more challenging than the passive RIS-aided systems and its efficient algorithms are less studied. In this paper, we consider the sum rate maximization problem in the multiuser massive multiple-input single-output (MISO) downlink with the aid of a large-scale active RIS. Existing approaches usually resort to general optimization solvers and can be computationally prohibitive in the considered settings. We propose an efficient block successive upper bound minimization (BSUM) method, of which each step has a (semi) closed-form update. Thus, the proposed algorithm has an attractive low per-iteration complexity. By simulation, our proposed algorithm consumes much less computation than the existing approaches. In particular, when the MIMO and/or RIS sizes are large, our proposed algorithm can be orders-of-magnitude faster than existing approaches.
Extending Whisper with prompt tuning to target-speaker ASR
Dec 13, 2023

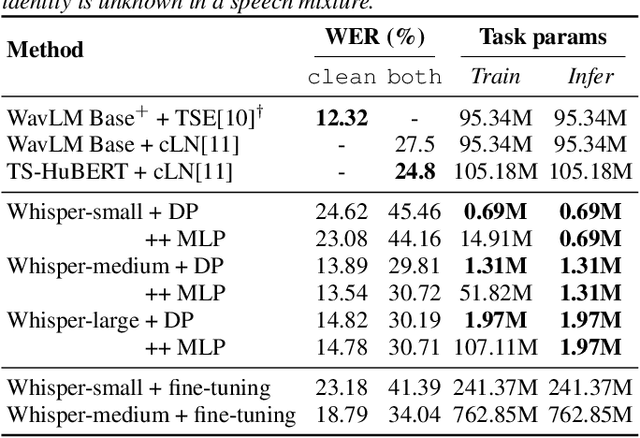

Target-speaker automatic speech recognition (ASR) aims to transcribe the desired speech of a target speaker from multi-talker overlapped utterances. Most of the existing target-speaker ASR (TS-ASR) methods involve either training from scratch or fully fine-tuning a pre-trained model, leading to significant training costs and becoming inapplicable to large foundation models. This work leverages prompt tuning, a parameter-efficient fine-tuning approach, to extend Whisper, a large-scale single-talker ASR model, to TS-ASR. Experimental results show that prompt tuning can achieve performance comparable to state-of-the-art full fine-tuning approaches while only requiring about 1% of task-specific model parameters. Notably, the original Whisper's features, such as inverse text normalization and timestamp prediction, are retained in target-speaker ASR, keeping the generated transcriptions natural and informative.
Nonlinear Kernel Support Vector Machine with 0-1 Soft Margin Loss
Mar 01, 2022
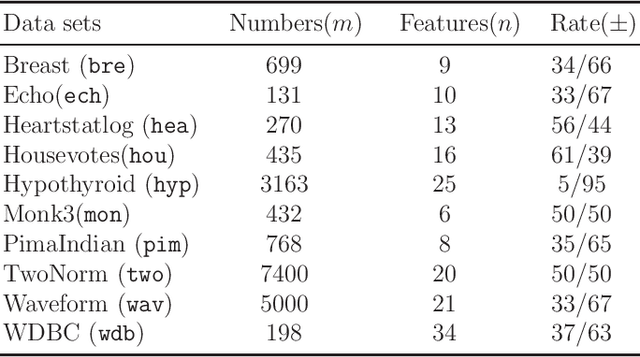
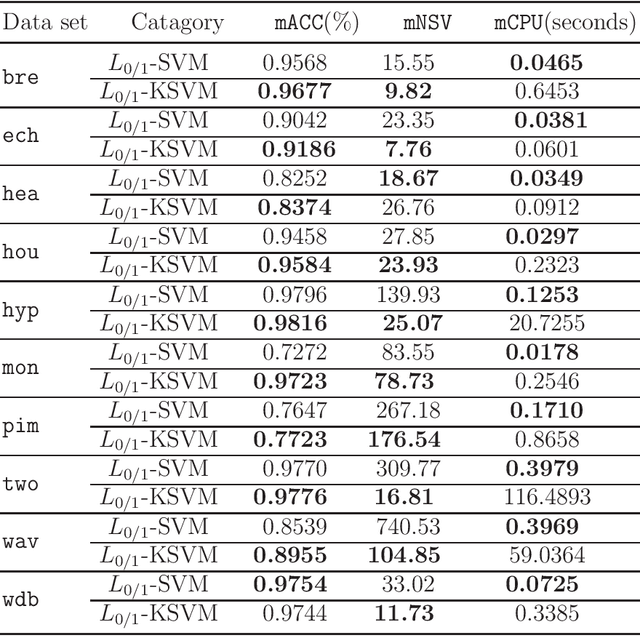
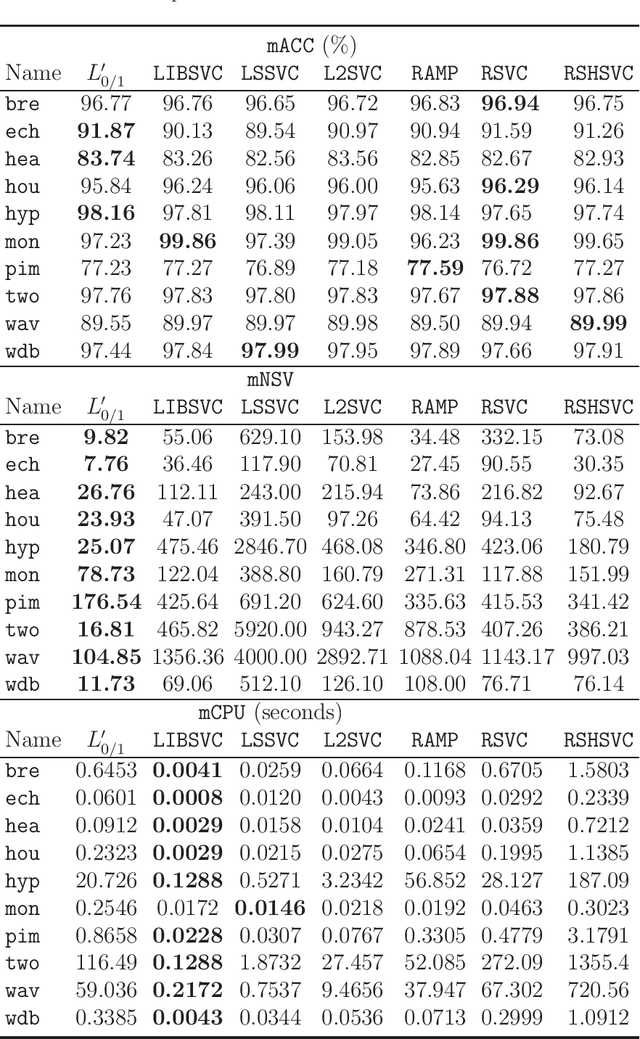
Recent advance on linear support vector machine with the 0-1 soft margin loss ($L_{0/1}$-SVM) shows that the 0-1 loss problem can be solved directly. However, its theoretical and algorithmic requirements restrict us extending the linear solving framework to its nonlinear kernel form directly, the absence of explicit expression of Lagrangian dual function of $L_{0/1}$-SVM is one big deficiency among of them. In this paper, by applying the nonparametric representation theorem, we propose a nonlinear model for support vector machine with 0-1 soft margin loss, called $L_{0/1}$-KSVM, which cunningly involves the kernel technique into it and more importantly, follows the success on systematically solving its linear task. Its optimal condition is explored theoretically and a working set selection alternating direction method of multipliers (ADMM) algorithm is introduced to acquire its numerical solution. Moreover, we firstly present a closed-form definition to the support vector (SV) of $L_{0/1}$-KSVM. Theoretically, we prove that all SVs of $L_{0/1}$-KSVM are only located on the parallel decision surfaces. The experiment part also shows that $L_{0/1}$-KSVM has much fewer SVs, simultaneously with a decent predicting accuracy, when comparing to its linear peer $L_{0/1}$-SVM and the other six nonlinear benchmark SVM classifiers.