 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Intelligibility for Generative Target Speech Extraction via Joint Optimization with Target Speaker ASR
Jan 24, 2025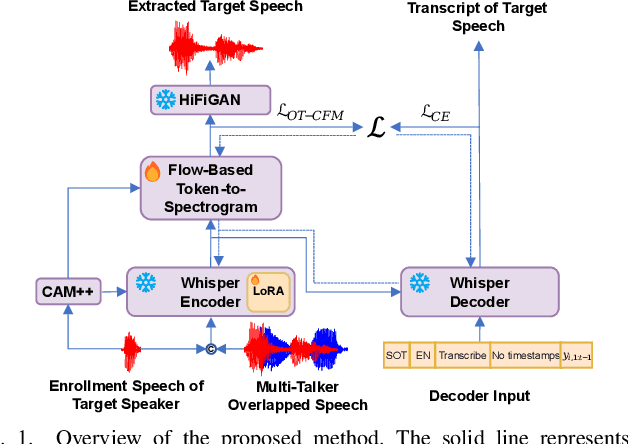
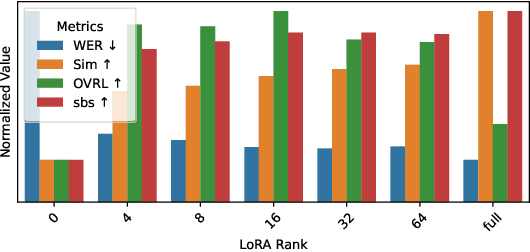
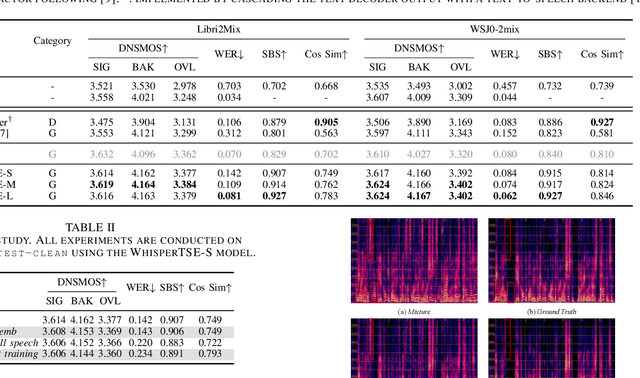
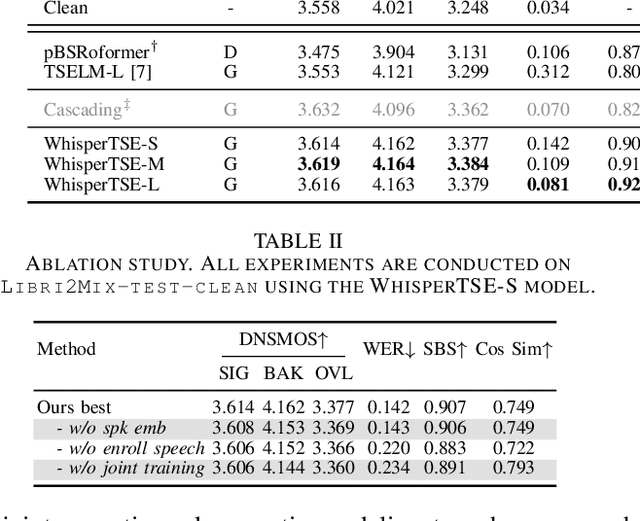
Target speech extraction (TSE) isolates the speech of a specific speaker from a multi-talker overlapped speech mixture. Most existing TSE models rely on discriminative methods, typically predicting a time-frequency spectrogram mask for the target speech. However, imperfections in these masks often result in over-/under-suppression of target/non-target speech, degrading perceptual quality. Generative methods, by contrast, re-synthesize target speech based on the mixture and target speaker cues, achieving superior perceptual quality. Nevertheless, these methods often overlook speech intelligibility, leading to alterations or loss of semantic content in the re-synthesized speech. Inspired by the Whisper model's success in target speaker ASR, we propose a generative TSE framework based on the pre-trained Whisper model to address the above issues. This framework integrates semantic modeling with flow-based acoustic modeling to achieve both high intelligibility and perceptual quality. Results from multiple benchmarks demonstrate that the proposed method outperforms existing generative and discriminative baselines. We present speech samples on our demo page.