 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Fidelity Generative Audio Compression at 0.275kbps
Jan 31, 2026High-fidelity general audio compression at ultra-low bitrates is crucial for applications ranging from low-bandwidth communication to generative audio-language modeling. Traditional audio compression methods and contemporary neural codecs are fundamentally designed for waveform reconstruction. As a result, when operating at ultra-low bitrates, these methods degrade rapidly and often fail to preserve essential information, leading to severe acoustic artifacts and pronounced semantic distortion. To overcome these limitations, we introduce Generative Audio Compression (GAC), a novel paradigm shift from signal fidelity to task-oriented effectiveness. Implemented within the AI Flow framework, GAC is theoretically grounded in the Law of Information Capacity. These foundations posit that abundant computational power can be leveraged at the receiver to offset extreme communication bottlenecks--exemplifying the More Computation, Less Bandwidth philosophy. By integrating semantic understanding at the transmitter with scalable generative synthesis at the receiver, GAC offloads the information burden to powerful model priors. Our 1.8B-parameter model achieves high-fidelity reconstruction of 32kHz general audio at an unprecedented bitrate of 0.275kbps. Even at 0.175kbps, it still preserves a strong intelligible audio transmission capability, which represents an about 3000x compression ratio, significantly outperforming current state-of-the-art neural codecs in maintaining both perceptual quality and semantic consistency.
Rare Word Recognition and Translation Without Fine-Tuning via Task Vector in Speech Models
Dec 26, 2025Rare words remain a critical bottleneck for speech-to-text systems. While direct fine-tuning improves recognition of target words, it often incurs high cost, catastrophic forgetting, and limited scalability. To address these challenges, we propose a training-free paradigm based on task vectors for rare word recognition and translation. By defining task vectors as parameter differences and introducing word-level task vector arithmetic, our approach enables flexible composition of rare-word capabilities, greatly enhancing scalability and reusability. Extensive experiments across multiple domains show that the proposed method matches or surpasses fine-tuned models on target words, improves general performance by about 5 BLEU, and mitigates catastrophic forgetting.
Bridging the Gap between Continuous and Informative Discrete Representations by Random Product Quantization
Apr 07, 2025Self-supervised learning has become a core technique in speech processing, but the high dimensionality of its representations makes discretization essential for improving efficiency. However, existing discretization methods still suffer from significant information loss, resulting in a notable performance gap compared to continuous representations. To overcome these limitations, we propose two quantization-based discretization methods: Product Quantization (PQ) and Random Product Quantization (RPQ). PQ partitions the original feature space into multiple subspaces and independently quantizes each sub-vector, producing a fused set of discrete units that retain diverse information from different subspaces, thus mitigating the loss associated with single-cluster quantization. RPQ further enhances representation diversity by randomly sampling a fixed proportion of feature dimensions multiple times to construct sub-vectors, thereby better capturing the variability in the data distribution. Theoretical analysis shows that RPQ reduces the correlation coefficient rho (where 0 <= rho <= 1) between sub-quantizers. Its quantization error is lower-bounded by the product of rho and epsilon-kms, where epsilon-kms denotes the quantization error of a single K-means quantizer. Experimental results on a combined dataset built from LibriSpeech and ML-SUPERB show that PQ and RPQ outperform standard K-means discretization, achieving relative improvements of 21.8 percent and 20.0 percent in WER on LibriSpeech, and 24.1 percent and 19.6 percent in CER on ML-SUPERB, respectively. Moreover, their performance is competitive with, and in some cases even surpasses, that of continuous SSL representations.
Enhancing Intelligibility for Generative Target Speech Extraction via Joint Optimization with Target Speaker ASR
Jan 24, 2025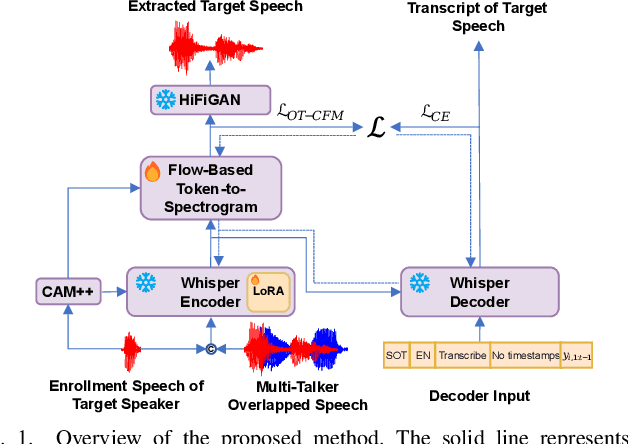
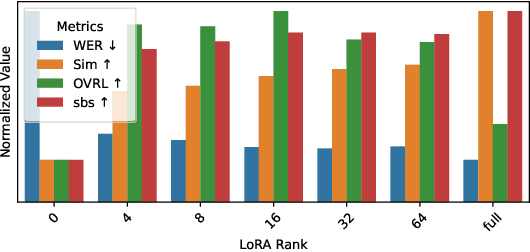
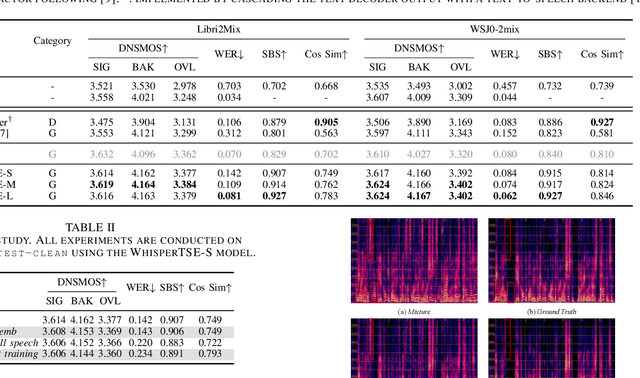
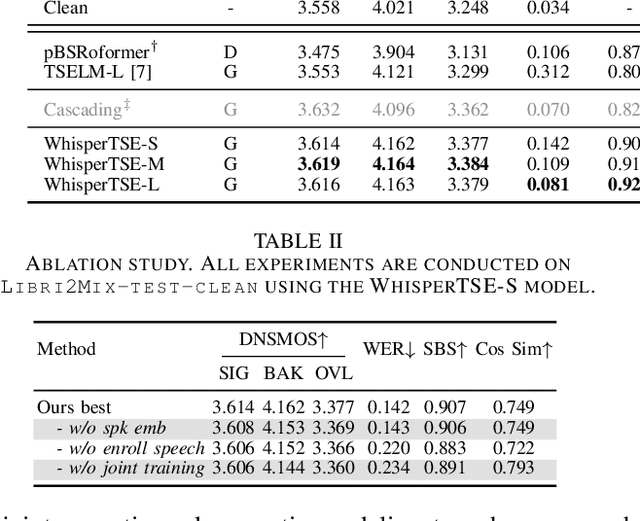
Target speech extraction (TSE) isolates the speech of a specific speaker from a multi-talker overlapped speech mixture. Most existing TSE models rely on discriminative methods, typically predicting a time-frequency spectrogram mask for the target speech. However, imperfections in these masks often result in over-/under-suppression of target/non-target speech, degrading perceptual quality. Generative methods, by contrast, re-synthesize target speech based on the mixture and target speaker cues, achieving superior perceptual quality. Nevertheless, these methods often overlook speech intelligibility, leading to alterations or loss of semantic content in the re-synthesized speech. Inspired by the Whisper model's success in target speaker ASR, we propose a generative TSE framework based on the pre-trained Whisper model to address the above issues. This framework integrates semantic modeling with flow-based acoustic modeling to achieve both high intelligibility and perceptual quality. Results from multiple benchmarks demonstrate that the proposed method outperforms existing generative and discriminative baselines. We present speech samples on our demo page.