 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Medical Image Restoration via Reliability Guided Learning in Frequency Domain
Apr 15, 2025



Medical image restoration tasks aim to recover high-quality images from degraded observations, exhibiting emergent desires in many clinical scenarios, such as low-dose CT image denoising, MRI super-resolution, and MRI artifact removal. Despite the success achieved by existing deep learning-based restoration methods with sophisticated modules, they struggle with rendering computationally-efficient reconstruction results. Moreover, they usually ignore the reliability of the restoration results, which is much more urgent in medical systems. To alleviate these issues, we present LRformer, a Lightweight Transformer-based method via Reliability-guided learning in the frequency domain. Specifically, inspired by the uncertainty quantification in Bayesian neural networks (BNNs), we develop a Reliable Lesion-Semantic Prior Producer (RLPP). RLPP leverages Monte Carlo (MC) estimators with stochastic sampling operations to generate sufficiently-reliable priors by performing multiple inferences on the foundational medical image segmentation model, MedSAM. Additionally, instead of directly incorporating the priors in the spatial domain, we decompose the cross-attention (CA) mechanism into real symmetric and imaginary anti-symmetric parts via fast Fourier transform (FFT), resulting in the design of the Guided Frequency Cross-Attention (GFCA) solver. By leveraging the conjugated symmetric property of FFT, GFCA reduces the computational complexity of naive CA by nearly half. Extensive experimental results in various tasks demonstrate the superiority of the proposed LRformer in both effectiveness and efficiency.
From Diffusion to Resolution: Leveraging 2D Diffusion Models for 3D Super-Resolution Task
Nov 25, 2024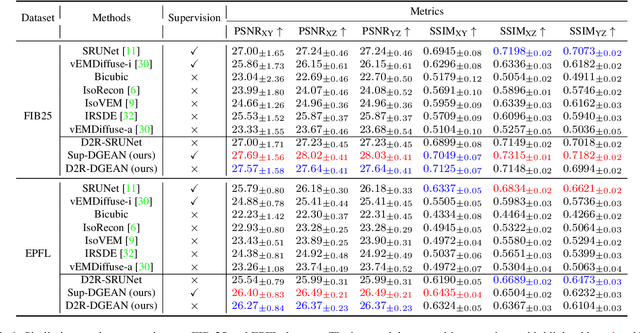
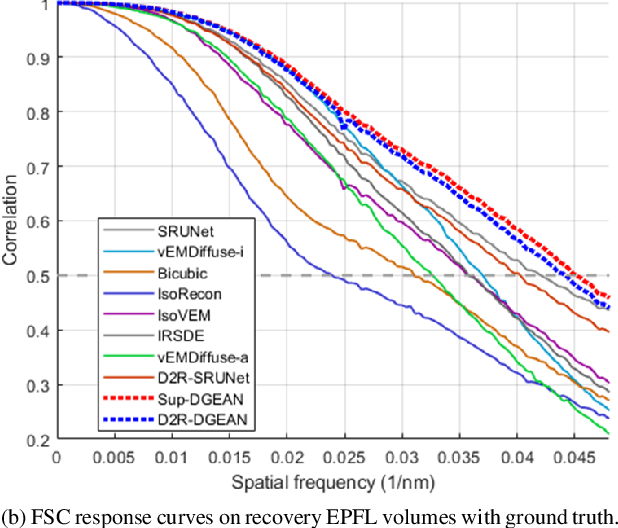
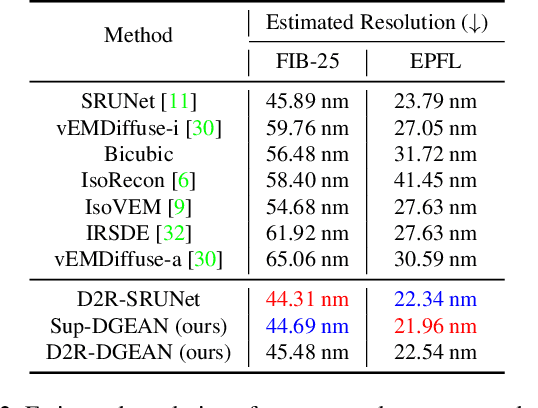

Diffusion models have recently emerged as a powerful technique in image generation, especially for image super-resolution tasks. While 2D diffusion models significantly enhance the resolution of individual images, existing diffusion-based methods for 3D volume super-resolution often struggle with structure discontinuities in axial direction and high sampling costs. In this work, we present a novel approach that leverages the 2D diffusion model and lateral continuity within the volume to enhance 3D volume electron microscopy (vEM) super-resolution. We first simulate lateral degradation with slices in the XY plane and train a 2D diffusion model to learn how to restore the degraded slices. The model is then applied slice-by-slice in the lateral direction of low-resolution volume, recovering slices while preserving inherent lateral continuity. Following this, a high-frequency-aware 3D super-resolution network is trained on the recovery lateral slice sequences to learn spatial feature transformation across slices. Finally, the network is applied to infer high-resolution volumes in the axial direction, enabling 3D super-resolution. We validate our approach through comprehensive evaluations, including image similarity assessments, resolution analysis, and performance on downstream tasks. Our results on two publicly available focused ion beam scanning electron microscopy (FIB-SEM) datasets demonstrate the robustness and practical applicability of our framework for 3D volume super-resolution.