 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion Model-Based Data Augmentation for Enhanced Neuron Segmentation
Jan 22, 2026Neuron segmentation in electron microscopy (EM) aims to reconstruct the complete neuronal connectome; however, current deep learning-based methods are limited by their reliance on large-scale training data and extensive, time-consuming manual annotations. Traditional methods augment the training set through geometric and photometric transformations; however, the generated samples remain highly correlated with the original images and lack structural diversity. To address this limitation, we propose a diffusion-based data augmentation framework capable of generating diverse and structurally plausible image-label pairs for neuron segmentation. Specifically, the framework employs a resolution-aware conditional diffusion model with multi-scale conditioning and EM resolution priors to enable voxel-level image synthesis from 3D masks. It further incorporates a biology-guided mask remodeling module that produces augmented masks with enhanced structural realism. Together, these components effectively enrich the training set and improve segmentation performance. On the AC3 and AC4 datasets under low-annotation regimes, our method improves the ARAND metric by 32.1% and 30.7%, respectively, when combined with two different post-processing methods. Our code is available at https://github.com/HeadLiuYun/NeuroDiff.
NeuroMamba: Multi-Perspective Feature Interaction with Visual Mamba for Neuron Segmentation
Jan 22, 2026Neuron segmentation is the cornerstone of reconstructing comprehensive neuronal connectomes, which is essential for deciphering the functional organization of the brain. The irregular morphology and densely intertwined structures of neurons make this task particularly challenging. Prevailing CNN-based methods often fail to resolve ambiguous boundaries due to the lack of long-range context, whereas Transformer-based methods suffer from boundary imprecision caused by the loss of voxel-level details during patch partitioning. To address these limitations, we propose NeuroMamba, a multi-perspective framework that exploits the linear complexity of Mamba to enable patch-free global modeling and synergizes this with complementary local feature modeling, thereby efficiently capturing long-range dependencies while meticulously preserving fine-grained voxel details. Specifically, we design a channel-gated Boundary Discriminative Feature Extractor (BDFE) to enhance local morphological cues. Complementing this, we introduce the Spatial Continuous Feature Extractor (SCFE), which integrates a resolution-aware scanning mechanism into the Visual Mamba architecture to adaptively model global dependencies across varying data resolutions. Finally, a cross-modulation mechanism synergistically fuses these multi-perspective features. Our method demonstrates state-of-the-art performance across four public EM datasets, validating its exceptional adaptability to both anisotropic and isotropic resolutions. The source code will be made publicly available.
From Diffusion to Resolution: Leveraging 2D Diffusion Models for 3D Super-Resolution Task
Nov 25, 2024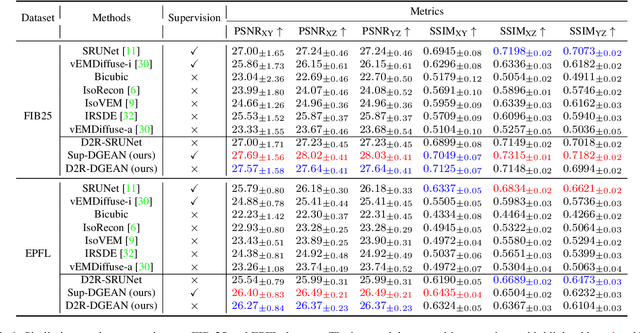
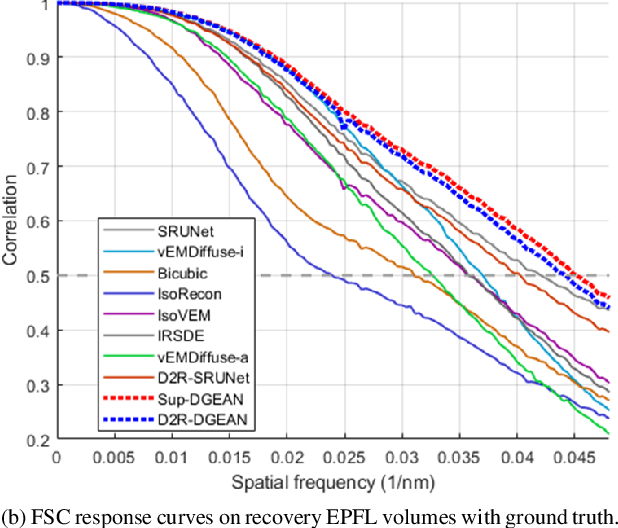
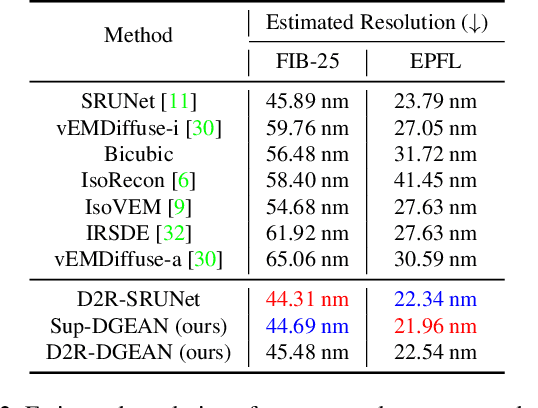

Diffusion models have recently emerged as a powerful technique in image generation, especially for image super-resolution tasks. While 2D diffusion models significantly enhance the resolution of individual images, existing diffusion-based methods for 3D volume super-resolution often struggle with structure discontinuities in axial direction and high sampling costs. In this work, we present a novel approach that leverages the 2D diffusion model and lateral continuity within the volume to enhance 3D volume electron microscopy (vEM) super-resolution. We first simulate lateral degradation with slices in the XY plane and train a 2D diffusion model to learn how to restore the degraded slices. The model is then applied slice-by-slice in the lateral direction of low-resolution volume, recovering slices while preserving inherent lateral continuity. Following this, a high-frequency-aware 3D super-resolution network is trained on the recovery lateral slice sequences to learn spatial feature transformation across slices. Finally, the network is applied to infer high-resolution volumes in the axial direction, enabling 3D super-resolution. We validate our approach through comprehensive evaluations, including image similarity assessments, resolution analysis, and performance on downstream tasks. Our results on two publicly available focused ion beam scanning electron microscopy (FIB-SEM) datasets demonstrate the robustness and practical applicability of our framework for 3D volume super-resolution.
A novel method for data augmentation: Nine Dot Moving Least Square
Aug 24, 2022



Data augmentation greatly increases the amount of data obtained based on labeled data to save on expenses and labor for data collection and labeling. We present a new approach for data augmentation called nine-dot MLS (ND-MLS). This approach is proposed based on the idea of image defor-mation. Images are deformed based on control points, which are calculated by ND-MLS. The method can generate over 2000 images for one exist-ing dataset in a short time. To verify this data augmentation method, extensive tests were performed covering 3 main tasks of computer vision, namely, classification, detection and segmentation. The results show that 1) in classification, 10 images per category were used for training, and VGGNet can obtain 92% top-1 acc on the MNIST dataset of handwritten digits by ND-MLS. In the Omniglot dataset, the few-shot accuracy usu-ally decreases with the increase in character categories. However, the ND-MLS method has stable performance and obtains 96.5 top-1 acc in Res-Net on 100 different handwritten character classification tasks; 2) in segmentation, under the premise of only ten original images, DeepLab obtains 93.5%, 85%, and 73.3% m_IOU(10) on the bottle, horse, and grass test datasets, respectively, while the cat test dataset obtains 86.7% m_IOU(10) with the SegNet model; 3) with only 10 original images from each category in object detection, YOLO v4 obtains 100% and 97.2% bottle and horse detection, respectively, while the cat dataset obtains 93.6% with YOLO v3. In summary, ND-MLS can perform well on classification, object detec-tion, and semantic segmentation tasks by using only a few data.