 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemRerank: Preference Memory for Personalized Product Reranking
Apr 02, 2026LLM-based shopping agents increasingly rely on long purchase histories and multi-turn interactions for personalization, yet naively appending raw history to prompts is often ineffective due to noise, length, and relevance mismatch. We propose MemRerank, a preference memory framework that distills user purchase history into concise, query-independent signals for personalized product reranking. To study this problem, we build an end-to-end benchmark and evaluation framework centered on an LLM-based \textbf{1-in-5} selection task, which measures both memory quality and downstream reranking utility. We further train the memory extractor with reinforcement learning (RL), using downstream reranking performance as supervision. Experiments with two LLM-based rerankers show that MemRerank consistently outperforms no-memory, raw-history, and off-the-shelf memory baselines, yielding up to \textbf{+10.61} absolute points in 1-in-5 accuracy. These results suggest that explicit preference memory is a practical and effective building block for personalization in agentic e-commerce systems.
Submodular Evaluation Subset Selection in Automatic Prompt Optimization
Jan 07, 2026Automatic prompt optimization reduces manual prompt engineering, but relies on task performance measured on a small, often randomly sampled evaluation subset as its main source of feedback signal. Despite this, how to select that evaluation subset is usually treated as an implementation detail. We study evaluation subset selection for prompt optimization from a principled perspective and propose SESS, a submodular evaluation subset selection method. We frame selection as maximizing an objective set function and show that, under mild conditions, it is monotone and submodular, enabling greedy selection with theoretical guarantees. Across GSM8K, MATH, and GPQA-Diamond, submodularly selected evaluation subsets can yield better optimized prompts than random or heuristic baselines.
Achievable Rate and Coding Principle for MIMO Multicarrier Systems With Cross-Domain MAMP Receiver Over Doubly Selective Channels
Jan 07, 2026The integration of multicarrier modulation and multiple-input-multiple-output (MIMO) is critical for reliable transmission of wireless signals in complex environments, which significantly improve spectrum efficiency. Existing studies have shown that popular orthogonal time frequency space (OTFS) and affine frequency division multiplexing (AFDM) offer significant advantages over orthogonal frequency division multiplexing (OFDM) in uncoded doubly selective channels. However, it remains uncertain whether these benefits extend to coded systems. Meanwhile, the information-theoretic limit analysis of coded MIMO multicarrier systems and the corresponding low-complexity receiver design remain unclear. To overcome these challenges, this paper proposes a multi-slot cross-domain memory approximate message passing (MS-CD-MAMP) receiver as well as develops its information-theoretic (i.e., achievable rate) limit and optimal coding principle for MIMO-multicarrier modulation (e.g., OFDM, OTFS, and AFDM) systems. The proposed MS-CD-MAMP receiver can exploit not only the time domain channel sparsity for low complexity but also the corresponding symbol domain constellation constraints for performance enhancement. Meanwhile, limited by the high-dimensional complex state evolution (SE), a simplified single-input single-output variational SE is proposed to derive the achievable rate of MS-CD-MAMP and the optimal coding principle with the goal of maximizing the achievable rate. Numerical results show that coded MIMO-OFDM/OTFS/AFDM with MS-CD-MAMP achieve the same maximum achievable rate in doubly selective channels, whose finite-length performance with practical optimized low-density parity-check (LDPC) codes is only 0.5 $\sim$ 1.8 dB away from the associated theoretical limit, and has 0.8 $\sim$ 4.4 dB gain over the well-designed point-to-point LDPC codes.
Adversarial Robustness in Zero-Shot Learning:An Empirical Study on Class and Concept-Level Vulnerabilities
Dec 21, 2025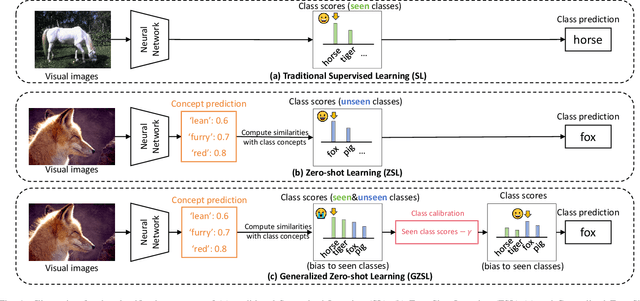

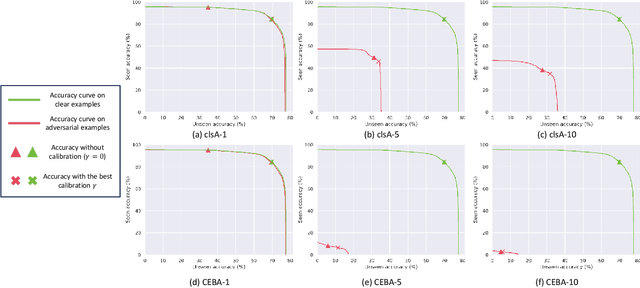
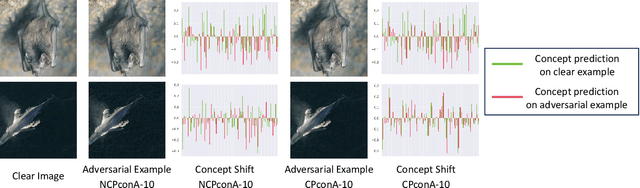
Zero-shot Learning (ZSL) aims to enable image classifiers to recognize images from unseen classes that were not included during training. Unlike traditional supervised classification, ZSL typically relies on learning a mapping from visual features to predefined, human-understandable class concepts. While ZSL models promise to improve generalization and interpretability, their robustness under systematic input perturbations remain unclear. In this study, we present an empirical analysis about the robustness of existing ZSL methods at both classlevel and concept-level. Specifically, we successfully disrupted their class prediction by the well-known non-target class attack (clsA). However, in the Generalized Zero-shot Learning (GZSL) setting, we observe that the success of clsA is only at the original best-calibrated point. After the attack, the optimal bestcalibration point shifts, and ZSL models maintain relatively strong performance at other calibration points, indicating that clsA results in a spurious attack success in the GZSL. To address this, we propose the Class-Bias Enhanced Attack (CBEA), which completely eliminates GZSL accuracy across all calibrated points by enhancing the gap between seen and unseen class probabilities.Next, at concept-level attack, we introduce two novel attack modes: Class-Preserving Concept Attack (CPconA) and NonClass-Preserving Concept Attack (NCPconA). Our extensive experiments evaluate three typical ZSL models across various architectures from the past three years and reveal that ZSL models are vulnerable not only to the traditional class attack but also to concept-based attacks. These attacks allow malicious actors to easily manipulate class predictions by erasing or introducing concepts. Our findings highlight a significant performance gap between existing approaches, emphasizing the need for improved adversarial robustness in current ZSL models.
Efficiency-Effectiveness Reranking FLOPs for LLM-based Rerankers
Jul 08, 2025Large Language Models (LLMs) have recently been applied to reranking tasks in information retrieval, achieving strong performance. However, their high computational demands often hinder practical deployment. Existing studies evaluate the efficiency of LLM-based rerankers using proxy metrics such as latency, the number of forward passes, input tokens, and output tokens. However, these metrics depend on hardware and running-time choices (\eg parallel or not, batch size, etc), and often fail to account for model size, making it difficult to interpret and obscuring the evaluation of the efficiency-effectiveness tradeoff. To address this issue, we propose E\textsuperscript{2}R-FLOPs, for LLM-based rerankers: ranking metrics per PetaFLOP (RPP) for relevance per compute and queries per PetaFLOP (QPP) for hardware-agnostic throughput. Companied with the new metrics, an interpretable FLOPs estimator is built to estimate the FLOPs of an LLM-based reranker even without running any experiments. Based on the proposed metrics, we conduct comprehensive experiments to evaluate a wide range of LLM-based rerankers with different architecture, studying the efficiency-effectiveness trade-off and bringing this issue to the attention of the research community.
Rank-Based Modeling for Universal Packets Compression in Multi-Modal Communications
Mar 24, 2025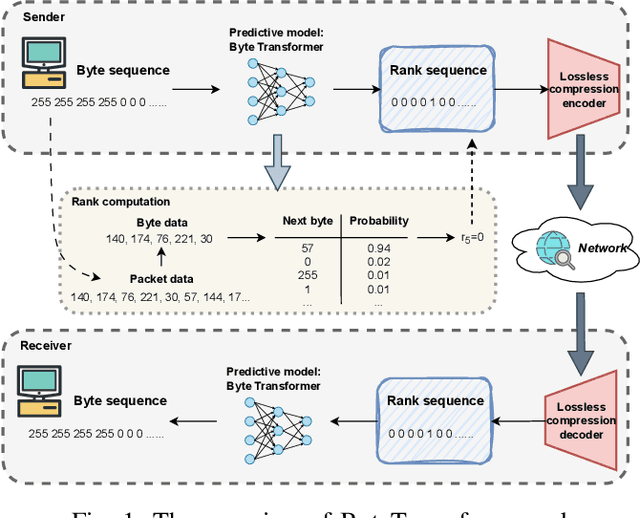
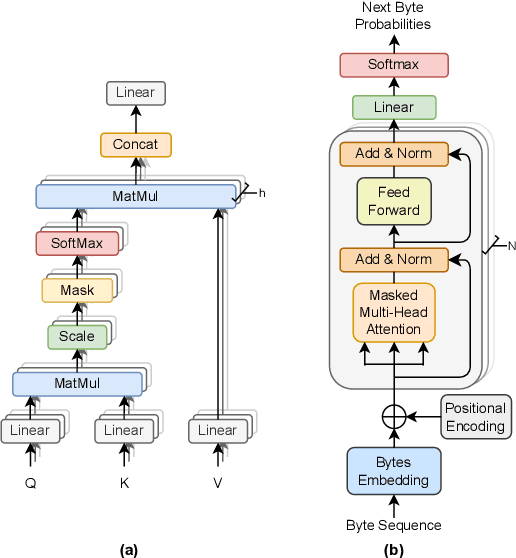
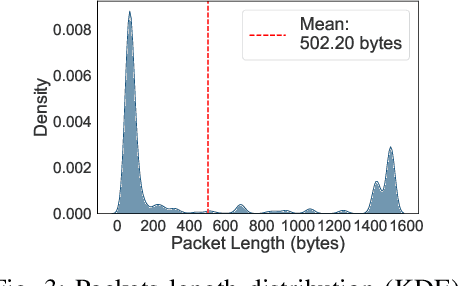
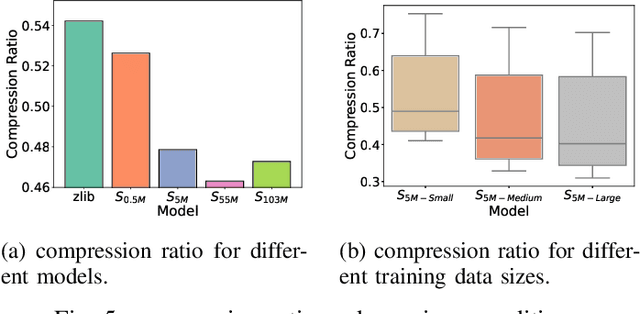
The rapid increase in networked systems and data transmission requires advanced data compression solutions to optimize bandwidth utilization and enhance network performance. This study introduces a novel byte-level predictive model using Transformer architecture, capable of handling the redundancy and diversity of data types in network traffic as byte sequences. Unlike traditional methods that require separate compressors for different data types, this unified approach sets new benchmarks and simplifies predictive modeling across various data modalities such as video, audio, images, and text, by processing them at the byte level. This is achieved by predicting subsequent byte probability distributions, encoding them into a sparse rank sequence using lossless entropy coding, and significantly reducing both data size and entropy. Experimental results show that our model achieves compression ratios below 50%, while offering models of various sizes tailored for different communication devices. Additionally, we successfully deploy these models on a range of edge devices and servers, demonstrating their practical applicability and effectiveness in real-world network scenarios. This approach significantly enhances data throughput and reduces bandwidth demands, making it particularly valuable in resource-constrained environments like the Internet of Things sensor networks.
RAG-ConfusionQA: A Benchmark for Evaluating LLMs on Confusing Questions
Oct 18, 2024


Conversational AI agents use Retrieval Augmented Generation (RAG) to provide verifiable document-grounded responses to user inquiries. However, many natural questions do not have good answers: about 25\% contain false assumptions~\cite{Yu2023:CREPE}, and over 50\% are ambiguous~\cite{Min2020:AmbigQA}. RAG agents need high-quality data to improve their responses to confusing questions. This paper presents a novel synthetic data generation method to efficiently create a diverse set of context-grounded confusing questions from a given document corpus. We conduct an empirical comparative evaluation of several large language models as RAG agents to measure the accuracy of confusion detection and appropriate response generation. We contribute a benchmark dataset to the public domain.
Language-Queried Target Sound Extraction Without Parallel Training Data
Sep 14, 2024



Language-queried target sound extraction (TSE) aims to extract specific sounds from mixtures based on language queries. Traditional fully-supervised training schemes require extensively annotated parallel audio-text data, which are labor-intensive. We introduce a language-free training scheme, requiring only unlabelled audio clips for TSE model training by utilizing the multi-modal representation alignment nature of the contrastive language-audio pre-trained model (CLAP). In a vanilla language-free training stage, target audio is encoded using the pre-trained CLAP audio encoder to form a condition embedding for the TSE model, while during inference, user language queries are encoded by CLAP text encoder. This straightforward approach faces challenges due to the modality gap between training and inference queries and information leakage from direct exposure to target audio during training. To address this, we propose a retrieval-augmented strategy. Specifically, we create an embedding cache using audio captions generated by a large language model (LLM). During training, target audio embeddings retrieve text embeddings from this cache to use as condition embeddings, ensuring consistent modalities between training and inference and eliminating information leakage. Extensive experiment results show that our retrieval-augmented approach achieves consistent and notable performance improvements over existing state-of-the-art with better generalizability.
W-RAG: Weakly Supervised Dense Retrieval in RAG for Open-domain Question Answering
Aug 15, 2024In knowledge-intensive tasks such as open-domain question answering (OpenQA), Large Language Models (LLMs) often struggle to generate factual answers relying solely on their internal (parametric) knowledge. To address this limitation, Retrieval-Augmented Generation (RAG) systems enhance LLMs by retrieving relevant information from external sources, thereby positioning the retriever as a pivotal component. Although dense retrieval demonstrates state-of-the-art performance, its training poses challenges due to the scarcity of ground-truth evidence, largely attributed to the high costs of human annotation. In this paper, we propose W-RAG by utilizing the ranking capabilities of LLMs to create weakly labeled data for training dense retrievers. Specifically, we rerank the top-$K$ passages retrieved via BM25 by assessing the probability that LLMs will generate the correct answer based on the question and each passage. The highest-ranking passages are then used as positive training examples for dense retrieval. Our comprehensive experiments across four publicly available OpenQA datasets demonstrate that our approach enhances both retrieval and OpenQA performance compared to baseline models.
Digital Twin-Assisted Data-Driven Optimization for Reliable Edge Caching in Wireless Networks
Jun 29, 2024



Optimizing edge caching is crucial for the advancement of next-generation (nextG) wireless networks, ensuring high-speed and low-latency services for mobile users. Existing data-driven optimization approaches often lack awareness of the distribution of random data variables and focus solely on optimizing cache hit rates, neglecting potential reliability concerns, such as base station overload and unbalanced cache issues. This oversight can result in system crashes and degraded user experience. To bridge this gap, we introduce a novel digital twin-assisted optimization framework, called D-REC, which integrates reinforcement learning (RL) with diverse intervention modules to ensure reliable caching in nextG wireless networks. We first develop a joint vertical and horizontal twinning approach to efficiently create network digital twins, which are then employed by D-REC as RL optimizers and safeguards, providing ample datasets for training and predictive evaluation of our cache replacement policy. By incorporating reliability modules into a constrained Markov decision process, D-REC can adaptively adjust actions, rewards, and states to comply with advantageous constraints, minimizing the risk of network failures. Theoretical analysis demonstrates comparable convergence rates between D-REC and vanilla data-driven methods without compromising caching performance. Extensive experiments validate that D-REC outperforms conventional approaches in cache hit rate and load balancing while effectively enforcing predetermined reliability intervention modules.