 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAG-ConfusionQA: A Benchmark for Evaluating LLMs on Confusing Questions
Paper and Code
Oct 18, 2024
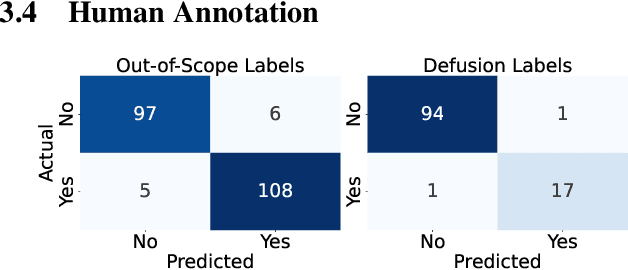


Conversational AI agents use Retrieval Augmented Generation (RAG) to provide verifiable document-grounded responses to user inquiries. However, many natural questions do not have good answers: about 25\% contain false assumptions~\cite{Yu2023:CREPE}, and over 50\% are ambiguous~\cite{Min2020:AmbigQA}. RAG agents need high-quality data to improve their responses to confusing questions. This paper presents a novel synthetic data generation method to efficiently create a diverse set of context-grounded confusing questions from a given document corpus. We conduct an empirical comparative evaluation of several large language models as RAG agents to measure the accuracy of confusion detection and appropriate response generation. We contribute a benchmark dataset to the public domain.