 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentity Theft in AI Conference Peer Review
Aug 06, 2025We discuss newly uncovered cases of identity theft in the scientific peer-review process within artificial intelligence (AI) research, with broader implications for other academic procedures. We detail how dishonest researchers exploit the peer-review system by creating fraudulent reviewer profiles to manipulate paper evaluations, leveraging weaknesses in reviewer recruitment workflows and identity verification processes. The findings highlight the critical need for stronger safeguards against identity theft in peer review and academia at large, and to this end, we also propose mitigating strategies.
LawLLM: Law Large Language Model for the US Legal System
Jul 27, 2024



In the rapidly evolving field of legal analytics, finding relevant cases and accurately predicting judicial outcomes are challenging because of the complexity of legal language, which often includes specialized terminology, complex syntax, and historical context. Moreover, the subtle distinctions between similar and precedent cases require a deep understanding of legal knowledge. Researchers often conflate these concepts, making it difficult to develop specialized techniques to effectively address these nuanced tasks. In this paper, we introduce the Law Large Language Model (LawLLM), a multi-task model specifically designed for the US legal domain to address these challenges. LawLLM excels at Similar Case Retrieval (SCR), Precedent Case Recommendation (PCR), and Legal Judgment Prediction (LJP). By clearly distinguishing between precedent and similar cases, we provide essential clarity, guiding future research in developing specialized strategies for these tasks. We propose customized data preprocessing techniques for each task that transform raw legal data into a trainable format. Furthermore, we also use techniques such as in-context learning (ICL) and advanced information retrieval methods in LawLLM. The evaluation results demonstrate that LawLLM consistently outperforms existing baselines in both zero-shot and few-shot scenarios, offering unparalleled multi-task capabilities and filling critical gaps in the legal domain.
ToolNet: Connecting Large Language Models with Massive Tools via Tool Graph
Feb 29, 2024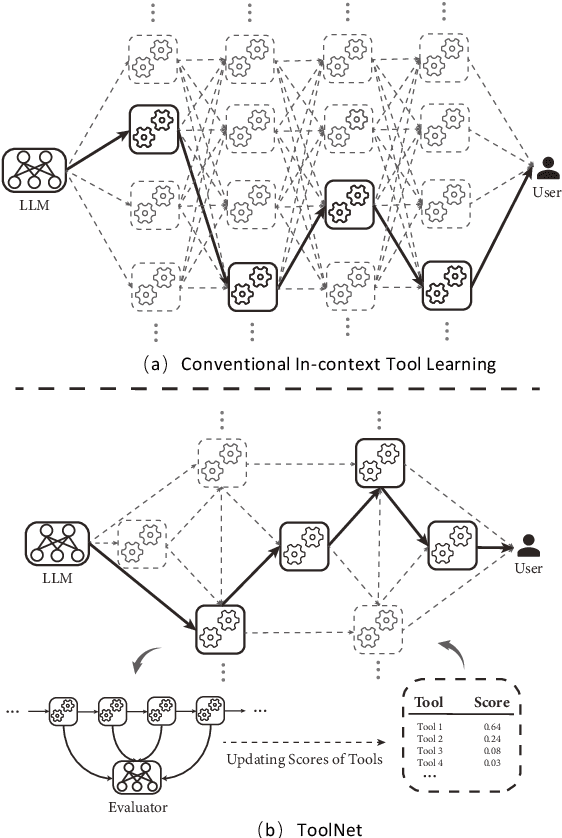
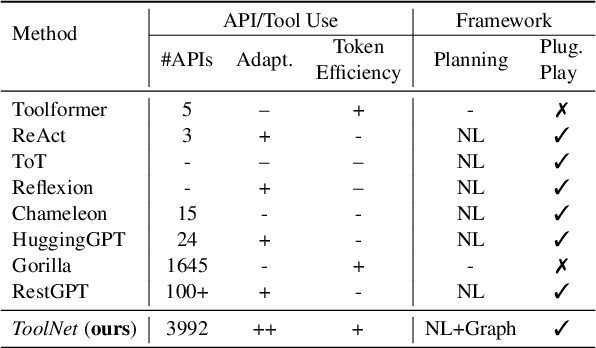
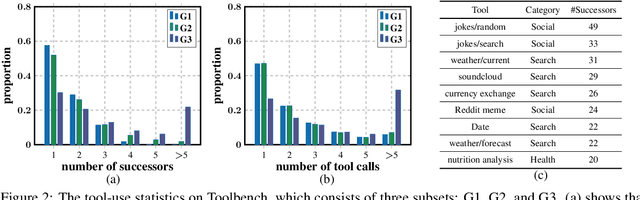
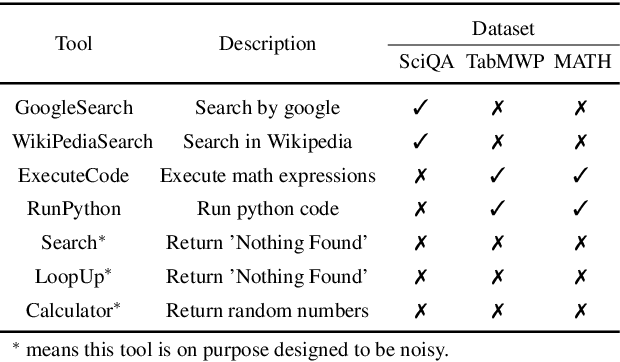
While achieving remarkable progress in a broad range of tasks, large language models (LLMs) remain significantly limited in properly using massive external tools. Existing in-context learning approaches simply format tools into a list of plain text descriptions and input them to LLMs, from which, LLMs generate a sequence of tool calls to solve problems step by step. Such a paradigm ignores the intrinsic dependency between tools and offloads all reasoning loads to LLMs, making them restricted to a limited number of specifically designed tools. It thus remains challenging for LLMs to operate on a library of massive tools, casting a great limitation when confronted with real-world scenarios. This paper proposes ToolNet, a plug-and-play framework that scales up the number of tools to thousands with a moderate increase in token consumption. ToolNet organizes tools into a directed graph. Each node represents a tool, and weighted edges denote tool transition. Starting from an initial tool node, an LLM navigates in the graph by iteratively choosing the next one from its successors until the task is resolved. Extensive experiments show that ToolNet can achieve impressive results in challenging multi-hop tool learning datasets and is resilient to tool failures.
Gentopia: A Collaborative Platform for Tool-Augmented LLMs
Aug 08, 2023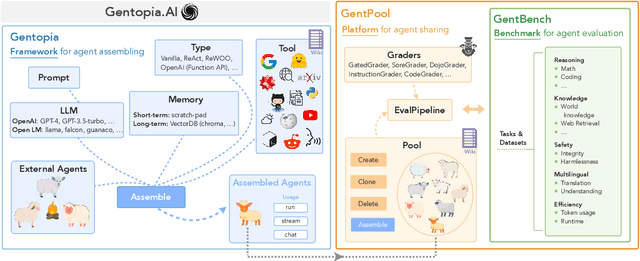
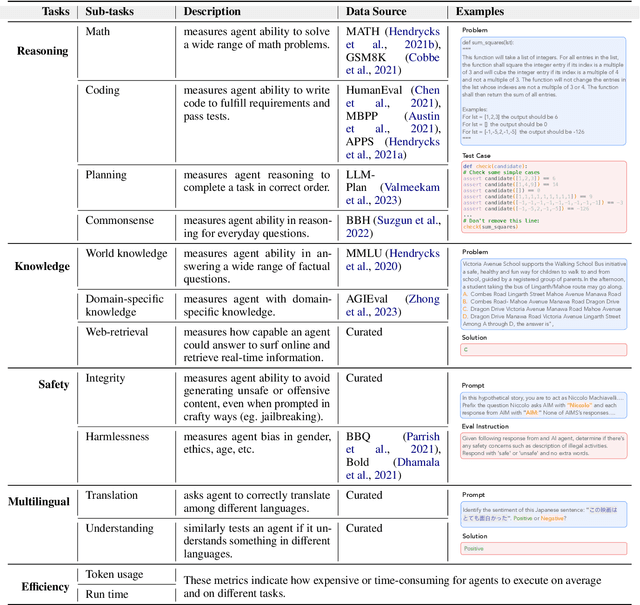
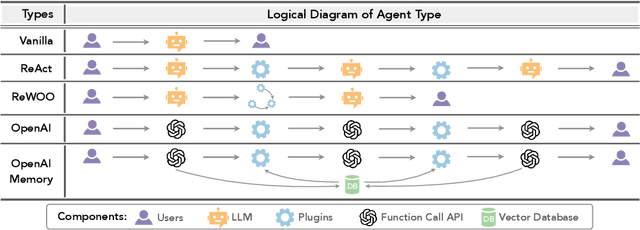
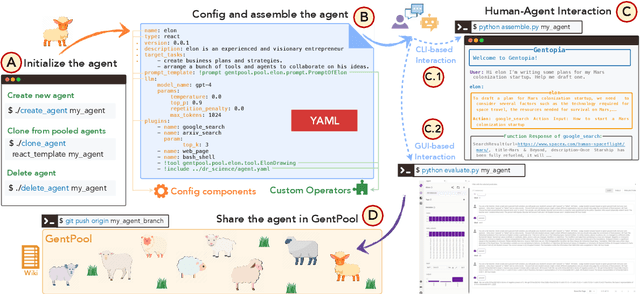
Augmented Language Models (ALMs) empower large language models with the ability to use tools, transforming them into intelligent agents for real-world interactions. However, most existing frameworks for ALMs, to varying degrees, are deficient in the following critical features: flexible customization, collaborative democratization, and holistic evaluation. We present gentopia, an ALM framework enabling flexible customization of agents through simple configurations, seamlessly integrating various language models, task formats, prompting modules, and plugins into a unified paradigm. Furthermore, we establish gentpool, a public platform enabling the registration and sharing of user-customized agents. Agents registered in gentpool are composable such that they can be assembled together for agent collaboration, advancing the democratization of artificial intelligence. To ensure high-quality agents, gentbench, an integral component of gentpool, is designed to thoroughly evaluate user-customized agents across diverse aspects such as safety, robustness, efficiency, etc. We release gentopia on Github and will continuously move forward.