 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhotorealistic Robotic Simulation using Unreal Engine 5 for Agricultural Applications
May 28, 2024This work presents a new robotics simulation environment built upon Unreal Engine 5 (UE5) for agricultural image data generation. The simulation utilizes the state-of-the-art real-time rendering engine to provide realistic plant images which are often used in agricultural applications. This study showcases the rendering accuracy of UE5 in comparison to existing tools and assesses its positional accuracy when integrated with Robot Operating Systems (ROS). The results indicate that UE5 achieves an impressive average distance error of 0.021mm when compared to predetermined setpoints in a multi-robot setup involving two UR10 arms.
ToolNet: Connecting Large Language Models with Massive Tools via Tool Graph
Feb 29, 2024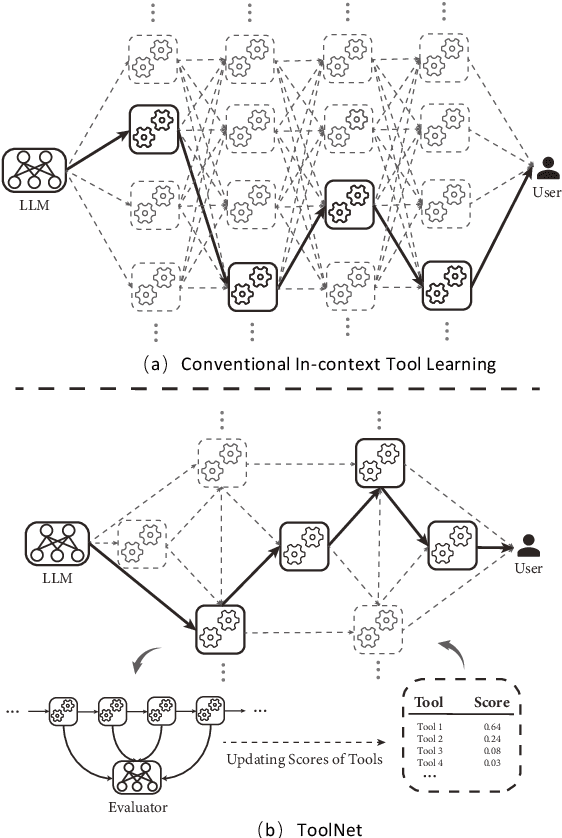
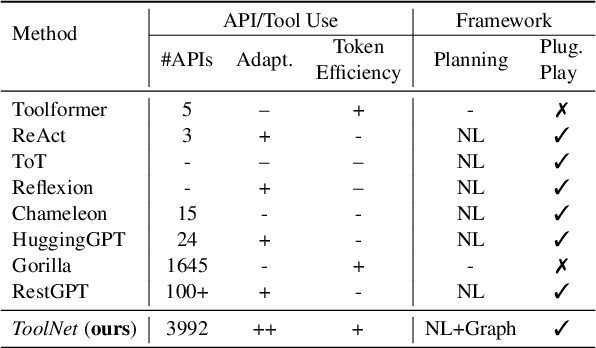
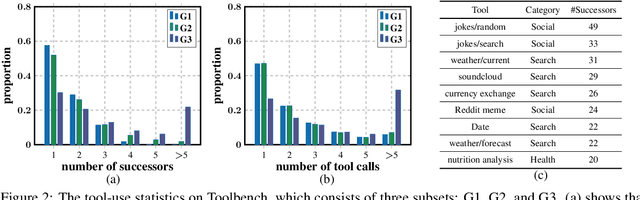
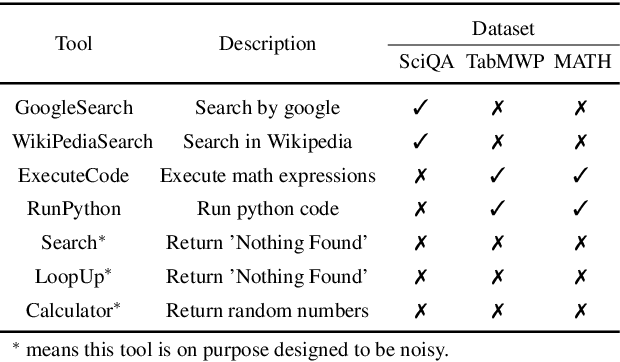
While achieving remarkable progress in a broad range of tasks, large language models (LLMs) remain significantly limited in properly using massive external tools. Existing in-context learning approaches simply format tools into a list of plain text descriptions and input them to LLMs, from which, LLMs generate a sequence of tool calls to solve problems step by step. Such a paradigm ignores the intrinsic dependency between tools and offloads all reasoning loads to LLMs, making them restricted to a limited number of specifically designed tools. It thus remains challenging for LLMs to operate on a library of massive tools, casting a great limitation when confronted with real-world scenarios. This paper proposes ToolNet, a plug-and-play framework that scales up the number of tools to thousands with a moderate increase in token consumption. ToolNet organizes tools into a directed graph. Each node represents a tool, and weighted edges denote tool transition. Starting from an initial tool node, an LLM navigates in the graph by iteratively choosing the next one from its successors until the task is resolved. Extensive experiments show that ToolNet can achieve impressive results in challenging multi-hop tool learning datasets and is resilient to tool failures.
Foundation Models in Smart Agriculture: Basics, Opportunities, and Challenges
Aug 18, 2023



The past decade has witnessed the rapid development of ML and DL methodologies in agricultural systems, showcased by great successes in variety of agricultural applications. However, these conventional ML/DL models have certain limitations: They heavily rely on large, costly-to-acquire labeled datasets for training, require specialized expertise for development and maintenance, and are mostly tailored for specific tasks, thus lacking generalizability. Recently, foundation models have demonstrated remarkable successes in language and vision tasks across various domains. These models are trained on a vast amount of data from multiple domains and modalities. Once trained, they can accomplish versatile tasks with just minor fine-tuning and minimal task-specific labeled data. Despite their proven effectiveness and huge potential, there has been little exploration of applying FMs to agriculture fields. Therefore, this study aims to explore the potential of FMs in the field of smart agriculture. In particular, we present conceptual tools and technical background to facilitate the understanding of the problem space and uncover new research directions in this field. To this end, we first review recent FMs in the general computer science domain and categorize them into four categories: language FMs, vision FMs, multimodal FMs, and reinforcement learning FMs. Subsequently, we outline the process of developing agriculture FMs and discuss their potential applications in smart agriculture. We also discuss the unique challenges associated with developing AFMs, including model training, validation, and deployment. Through this study, we contribute to the advancement of AI in agriculture by introducing AFMs as a promising paradigm that can significantly mitigate the reliance on extensive labeled datasets and enhance the efficiency, effectiveness, and generalization of agricultural AI systems.
Technical note: ShinyAnimalCV: open-source cloud-based web application for object detection, segmentation, and three-dimensional visualization of animals using computer vision
Jul 26, 2023



Computer vision (CV), a non-intrusive and cost-effective technology, has furthered the development of precision livestock farming by enabling optimized decision-making through timely and individualized animal care. The availability of affordable two- and three-dimensional camera sensors, combined with various machine learning and deep learning algorithms, has provided a valuable opportunity to improve livestock production systems. However, despite the availability of various CV tools in the public domain, applying these tools to animal data can be challenging, often requiring users to have programming and data analysis skills, as well as access to computing resources. Moreover, the rapid expansion of precision livestock farming is creating a growing need to educate and train animal science students in CV. This presents educators with the challenge of efficiently demonstrating the complex algorithms involved in CV. Thus, the objective of this study was to develop ShinyAnimalCV, an open-source cloud-based web application. This application provides a user-friendly interface for performing CV tasks, including object segmentation, detection, three-dimensional surface visualization, and extraction of two- and three-dimensional morphological features. Nine pre-trained CV models using top-view animal data are included in the application. ShinyAnimalCV has been deployed online using cloud computing platforms. The source code of ShinyAnimalCV is available on GitHub, along with detailed documentation on training CV models using custom data and deploying ShinyAnimalCV locally to allow users to fully leverage the capabilities of the application. ShinyAnimalCV can contribute to CV research and teaching in the animal science community.