 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoybeanNet: Transformer-Based Convolutional Neural Network for Soybean Pod Counting from Unmanned Aerial Vehicle (UAV) Images
Oct 16, 2023
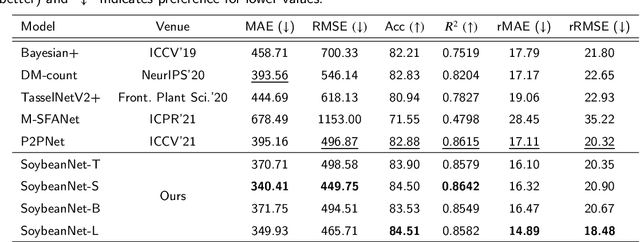
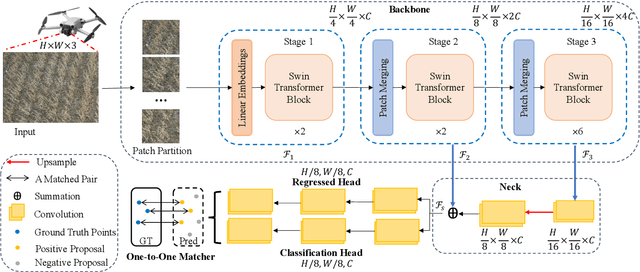
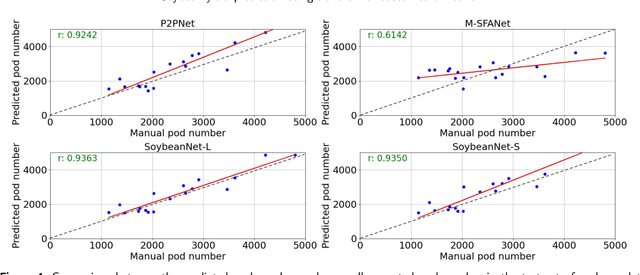
Soybeans are a critical source of food, protein and oil, and thus have received extensive research aimed at enhancing their yield, refining cultivation practices, and advancing soybean breeding techniques. Within this context, soybean pod counting plays an essential role in understanding and optimizing production. Despite recent advancements, the development of a robust pod-counting algorithm capable of performing effectively in real-field conditions remains a significant challenge This paper presents a pioneering work of accurate soybean pod counting utilizing unmanned aerial vehicle (UAV) images captured from actual soybean fields in Michigan, USA. Specifically, this paper presents SoybeanNet, a novel point-based counting network that harnesses powerful transformer backbones for simultaneous soybean pod counting and localization with high accuracy. In addition, a new dataset of UAV-acquired images for soybean pod counting was created and open-sourced, consisting of 113 drone images with more than 260k manually annotated soybean pods captured under natural lighting conditions. Through comprehensive evaluations, SoybeanNet demonstrated superior performance over five state-of-the-art approaches when tested on the collected images. Remarkably, SoybeanNet achieved a counting accuracy of $84.51\%$ when tested on the testing dataset, attesting to its efficacy in real-world scenarios. The publication also provides both the source code (\url{https://github.com/JiajiaLi04/Soybean-Pod-Counting-from-UAV-Images}) and the labeled soybean dataset (\url{https://www.kaggle.com/datasets/jiajiali/uav-based-soybean-pod-images}), offering a valuable resource for future research endeavors in soybean pod counting and related fields.
Foundation Models in Smart Agriculture: Basics, Opportunities, and Challenges
Aug 18, 2023



The past decade has witnessed the rapid development of ML and DL methodologies in agricultural systems, showcased by great successes in variety of agricultural applications. However, these conventional ML/DL models have certain limitations: They heavily rely on large, costly-to-acquire labeled datasets for training, require specialized expertise for development and maintenance, and are mostly tailored for specific tasks, thus lacking generalizability. Recently, foundation models have demonstrated remarkable successes in language and vision tasks across various domains. These models are trained on a vast amount of data from multiple domains and modalities. Once trained, they can accomplish versatile tasks with just minor fine-tuning and minimal task-specific labeled data. Despite their proven effectiveness and huge potential, there has been little exploration of applying FMs to agriculture fields. Therefore, this study aims to explore the potential of FMs in the field of smart agriculture. In particular, we present conceptual tools and technical background to facilitate the understanding of the problem space and uncover new research directions in this field. To this end, we first review recent FMs in the general computer science domain and categorize them into four categories: language FMs, vision FMs, multimodal FMs, and reinforcement learning FMs. Subsequently, we outline the process of developing agriculture FMs and discuss their potential applications in smart agriculture. We also discuss the unique challenges associated with developing AFMs, including model training, validation, and deployment. Through this study, we contribute to the advancement of AI in agriculture by introducing AFMs as a promising paradigm that can significantly mitigate the reliance on extensive labeled datasets and enhance the efficiency, effectiveness, and generalization of agricultural AI systems.