 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePackVFL: Efficient HE Packing for Vertical Federated Learning
May 01, 2024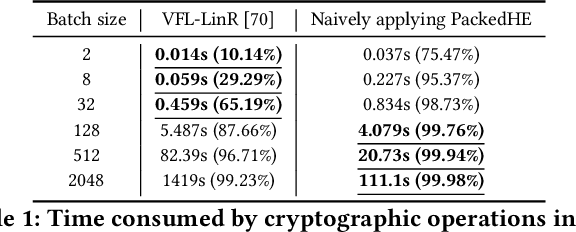
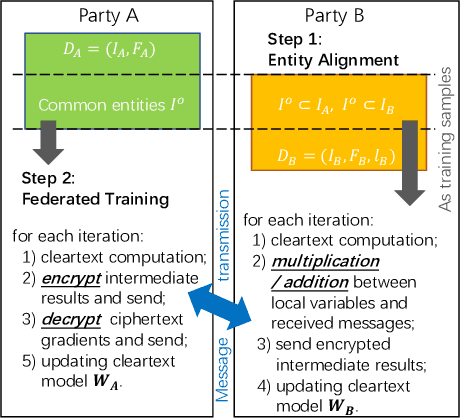
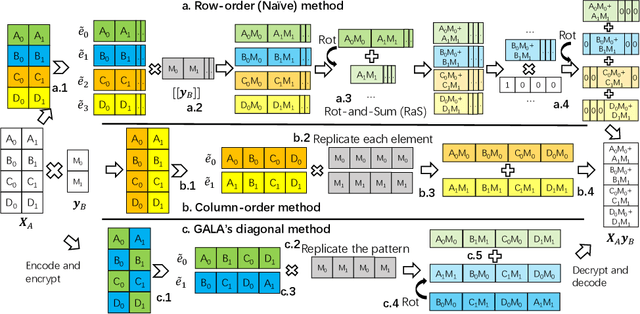

As an essential tool of secure distributed machine learning, vertical federated learning (VFL) based on homomorphic encryption (HE) suffers from severe efficiency problems due to data inflation and time-consuming operations. To this core, we propose PackVFL, an efficient VFL framework based on packed HE (PackedHE), to accelerate the existing HE-based VFL algorithms. PackVFL packs multiple cleartexts into one ciphertext and supports single-instruction-multiple-data (SIMD)-style parallelism. We focus on designing a high-performant matrix multiplication (MatMult) method since it takes up most of the ciphertext computation time in HE-based VFL. Besides, devising the MatMult method is also challenging for PackedHE because a slight difference in the packing way could predominantly affect its computation and communication costs. Without domain-specific design, directly applying SOTA MatMult methods is hard to achieve optimal. Therefore, we make a three-fold design: 1) we systematically explore the current design space of MatMult and quantify the complexity of existing approaches to provide guidance; 2) we propose a hybrid MatMult method according to the unique characteristics of VFL; 3) we adaptively apply our hybrid method in representative VFL algorithms, leveraging distinctive algorithmic properties to further improve efficiency. As the batch size, feature dimension and model size of VFL scale up to large sizes, PackVFL consistently delivers enhanced performance. Empirically, PackVFL propels existing VFL algorithms to new heights, achieving up to a 51.52X end-to-end speedup. This represents a substantial 34.51X greater speedup compared to the direct application of SOTA MatMult methods.
A Survey for Federated Learning Evaluations: Goals and Measures
Aug 23, 2023



Evaluation is a systematic approach to assessing how well a system achieves its intended purpose. Federated learning (FL) is a novel paradigm for privacy-preserving machine learning that allows multiple parties to collaboratively train models without sharing sensitive data. However, evaluating FL is challenging due to its interdisciplinary nature and diverse goals, such as utility, efficiency, and security. In this survey, we first review the major evaluation goals adopted in the existing studies and then explore the evaluation metrics used for each goal. We also introduce FedEval, an open-source platform that provides a standardized and comprehensive evaluation framework for FL algorithms in terms of their utility, efficiency, and security. Finally, we discuss several challenges and future research directions for FL evaluation.
A Survey on Vertical Federated Learning: From a Layered Perspective
Apr 04, 2023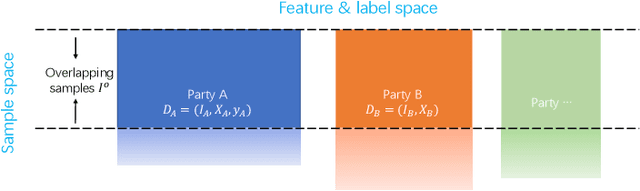

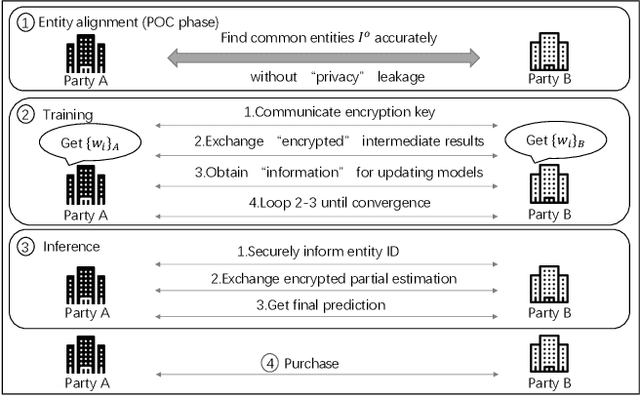
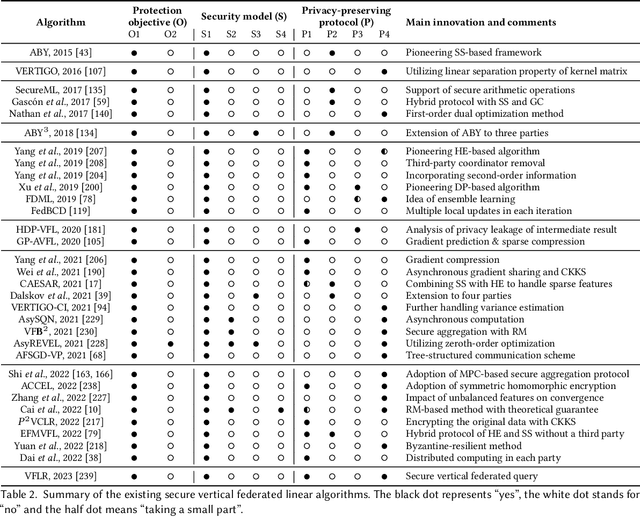
Vertical federated learning (VFL) is a promising category of federated learning for the scenario where data is vertically partitioned and distributed among parties. VFL enriches the description of samples using features from different parties to improve model capacity. Compared with horizontal federated learning, in most cases, VFL is applied in the commercial cooperation scenario of companies. Therefore, VFL contains tremendous business values. In the past few years, VFL has attracted more and more attention in both academia and industry. In this paper, we systematically investigate the current work of VFL from a layered perspective. From the hardware layer to the vertical federated system layer, researchers contribute to various aspects of VFL. Moreover, the application of VFL has covered a wide range of areas, e.g., finance, healthcare, etc. At each layer, we categorize the existing work and explore the challenges for the convenience of further research and development of VFL. Especially, we design a novel MOSP tree taxonomy to analyze the core component of VFL, i.e., secure vertical federated machine learning algorithm. Our taxonomy considers four dimensions, i.e., machine learning model (M), protection object (O), security model (S), and privacy-preserving protocol (P), and provides a comprehensive investigation.
Secure Forward Aggregation for Vertical Federated Neural Networks
Jun 28, 2022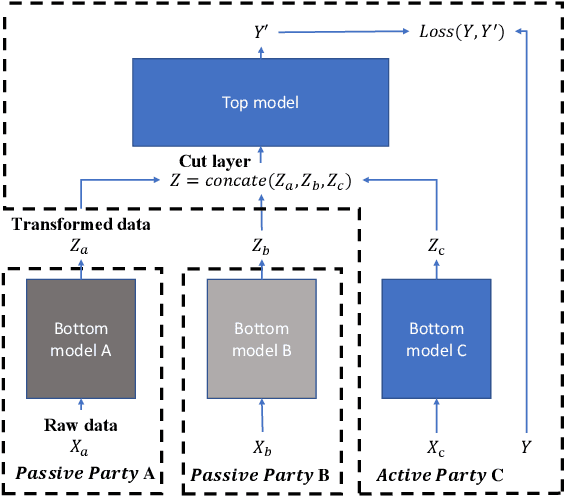


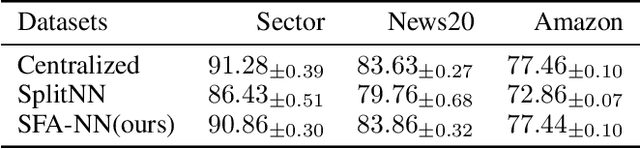
Vertical federated learning (VFL) is attracting much attention because it enables cross-silo data cooperation in a privacy-preserving manner. While most research works in VFL focus on linear and tree models, deep models (e.g., neural networks) are not well studied in VFL. In this paper, we focus on SplitNN, a well-known neural network framework in VFL, and identify a trade-off between data security and model performance in SplitNN. Briefly, SplitNN trains the model by exchanging gradients and transformed data. On the one hand, SplitNN suffers from the loss of model performance since multiply parties jointly train the model using transformed data instead of raw data, and a large amount of low-level feature information is discarded. On the other hand, a naive solution of increasing the model performance through aggregating at lower layers in SplitNN (i.e., the data is less transformed and more low-level feature is preserved) makes raw data vulnerable to inference attacks. To mitigate the above trade-off, we propose a new neural network protocol in VFL called Security Forward Aggregation (SFA). It changes the way of aggregating the transformed data and adopts removable masks to protect the raw data. Experiment results show that networks with SFA achieve both data security and high model performance.
Aegis: A Trusted, Automatic and Accurate Verification Framework for Vertical Federated Learning
Aug 23, 2021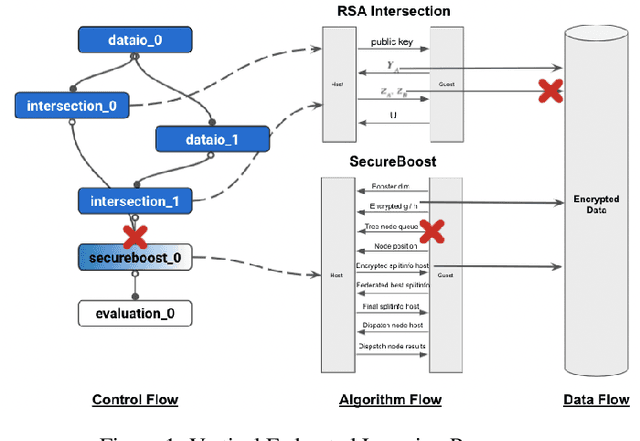
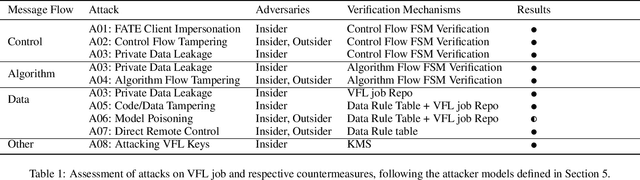
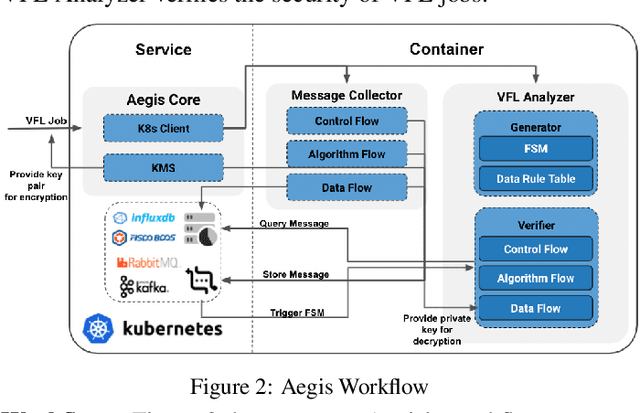
Vertical federated learning (VFL) leverages various privacy-preserving algorithms, e.g., homomorphic encryption or secret sharing based SecureBoost, to ensure data privacy. However, these algorithms all require a semi-honest secure definition, which raises concerns in real-world applications. In this paper, we present Aegis, a trusted, automatic, and accurate verification framework to verify the security of VFL jobs. Aegis is separated from local parties to ensure the security of the framework. Furthermore, it automatically adapts to evolving VFL algorithms by defining the VFL job as a finite state machine to uniformly verify different algorithms and reproduce the entire job to provide more accurate verification. We implement and evaluate Aegis with different threat models on financial and medical datasets. Evaluation results show that: 1) Aegis can detect 95% threat models, and 2) it provides fine-grained verification results within 84% of the total VFL job time.
Quantifying the Performance of Federated Transfer Learning
Dec 30, 2019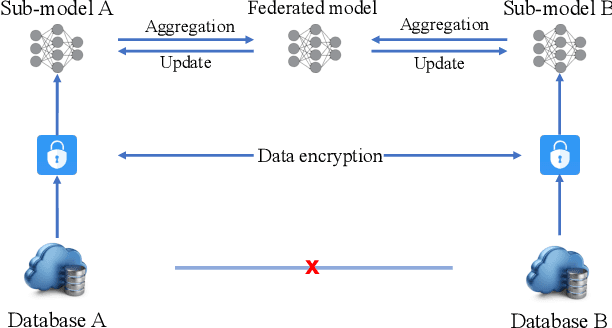
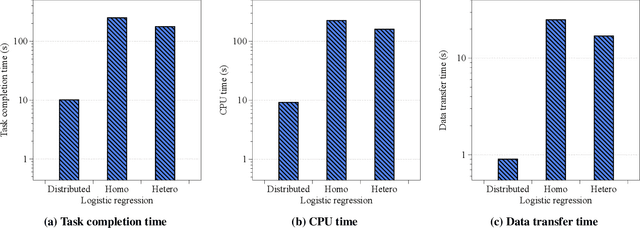
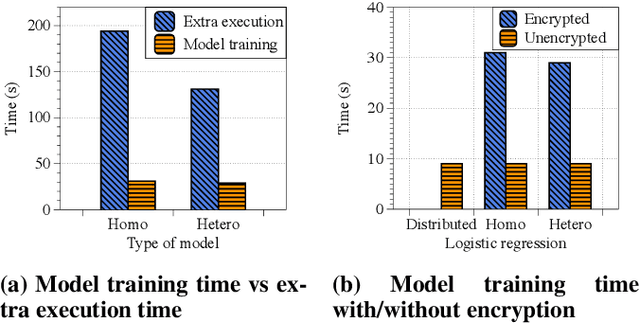
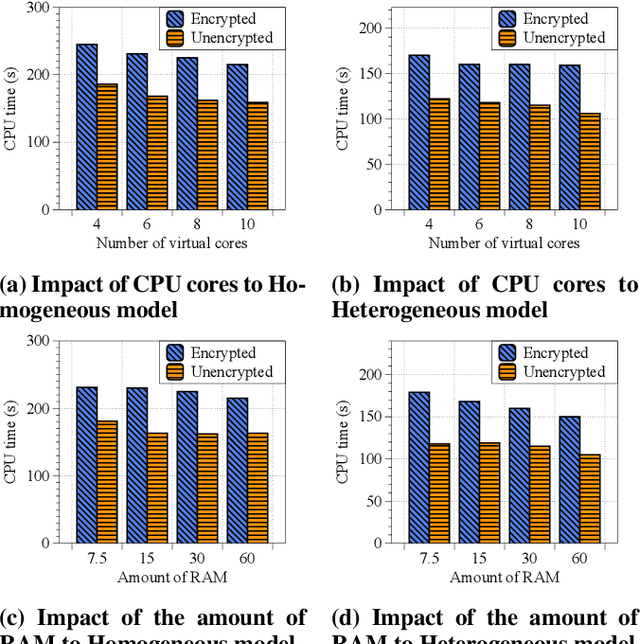
The scarcity of data and isolated data islands encourage different organizations to share data with each other to train machine learning models. However, there are increasing concerns on the problems of data privacy and security, which urges people to seek a solution like Federated Transfer Learning (FTL) to share training data without violating data privacy. FTL leverages transfer learning techniques to utilize data from different sources for training, while achieving data privacy protection without significant accuracy loss. However, the benefits come with a cost of extra computation and communication consumption, resulting in efficiency problems. In order to efficiently deploy and scale up FTL solutions in practice, we need a deep understanding on how the infrastructure affects the efficiency of FTL. Our paper tries to answer this question by quantitatively measuring a real-world FTL implementation FATE on Google Cloud. According to the results of carefully designed experiments, we verified that the following bottlenecks can be further optimized: 1) Inter-process communication is the major bottleneck; 2) Data encryption adds considerable computation overhead; 3) The Internet networking condition affects the performance a lot when the model is large.