 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeColdNAS: Search to Modulate for User Cold-Start Recommendation
Jun 06, 2023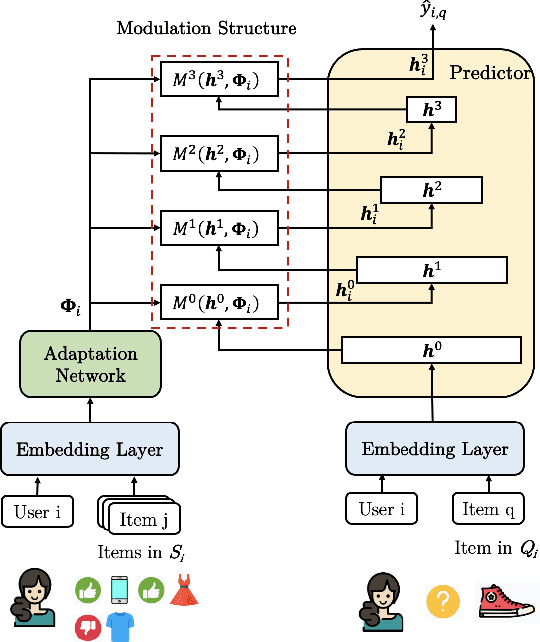

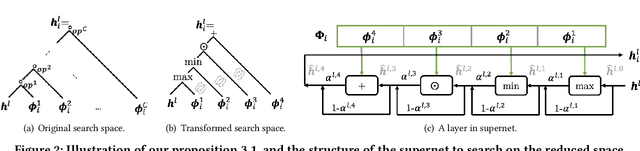
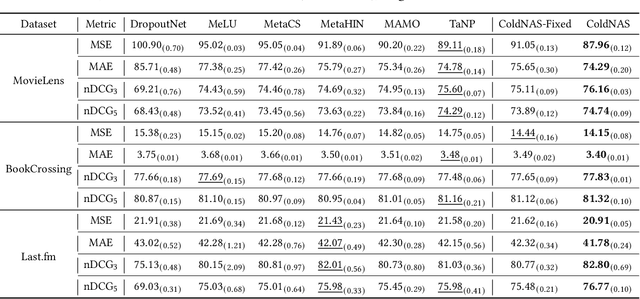
Making personalized recommendation for cold-start users, who only have a few interaction histories, is a challenging problem in recommendation systems. Recent works leverage hypernetworks to directly map user interaction histories to user-specific parameters, which are then used to modulate predictor by feature-wise linear modulation function. These works obtain the state-of-the-art performance. However, the physical meaning of scaling and shifting in recommendation data is unclear. Instead of using a fixed modulation function and deciding modulation position by expertise, we propose a modulation framework called ColdNAS for user cold-start problem, where we look for proper modulation structure, including function and position, via neural architecture search. We design a search space which covers broad models and theoretically prove that this search space can be transformed to a much smaller space, enabling an efficient and robust one-shot search algorithm. Extensive experimental results on benchmark datasets show that ColdNAS consistently performs the best. We observe that different modulation functions lead to the best performance on different datasets, which validates the necessity of designing a searching-based method.
Quantifying the Performance of Federated Transfer Learning
Dec 30, 2019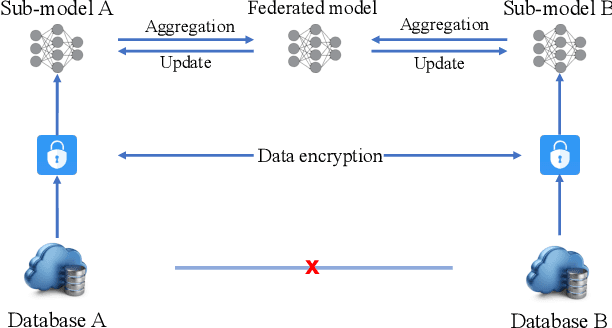
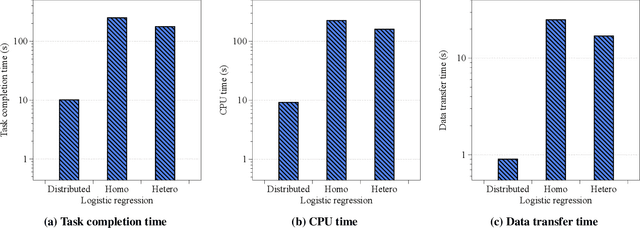
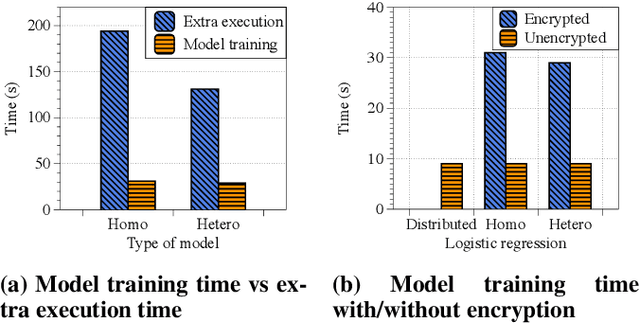
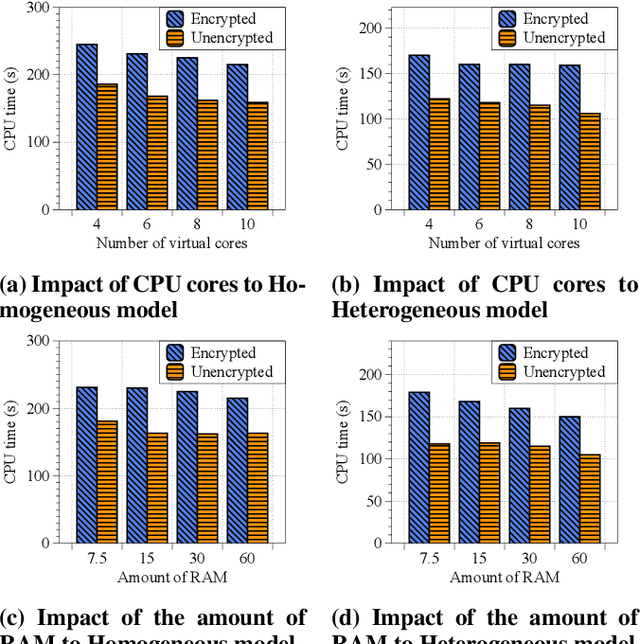
The scarcity of data and isolated data islands encourage different organizations to share data with each other to train machine learning models. However, there are increasing concerns on the problems of data privacy and security, which urges people to seek a solution like Federated Transfer Learning (FTL) to share training data without violating data privacy. FTL leverages transfer learning techniques to utilize data from different sources for training, while achieving data privacy protection without significant accuracy loss. However, the benefits come with a cost of extra computation and communication consumption, resulting in efficiency problems. In order to efficiently deploy and scale up FTL solutions in practice, we need a deep understanding on how the infrastructure affects the efficiency of FTL. Our paper tries to answer this question by quantitatively measuring a real-world FTL implementation FATE on Google Cloud. According to the results of carefully designed experiments, we verified that the following bottlenecks can be further optimized: 1) Inter-process communication is the major bottleneck; 2) Data encryption adds considerable computation overhead; 3) The Internet networking condition affects the performance a lot when the model is large.