 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDH-RAG: A Dynamic Historical Context-Powered Retrieval-Augmented Generation Method for Multi-Turn Dialogue
Feb 19, 2025Retrieval-Augmented Generation (RAG) systems have shown substantial benefits in applications such as question answering and multi-turn dialogue \citep{lewis2020retrieval}. However, traditional RAG methods, while leveraging static knowledge bases, often overlook the potential of dynamic historical information in ongoing conversations. To bridge this gap, we introduce DH-RAG, a Dynamic Historical Context-Powered Retrieval-Augmented Generation Method for Multi-Turn Dialogue. DH-RAG is inspired by human cognitive processes that utilize both long-term memory and immediate historical context in conversational responses \citep{stafford1987conversational}. DH-RAG is structured around two principal components: a History-Learning based Query Reconstruction Module, designed to generate effective queries by synthesizing current and prior interactions, and a Dynamic History Information Updating Module, which continually refreshes historical context throughout the dialogue. The center of DH-RAG is a Dynamic Historical Information database, which is further refined by three strategies within the Query Reconstruction Module: Historical Query Clustering, Hierarchical Matching, and Chain of Thought Tracking. Experimental evaluations show that DH-RAG significantly surpasses conventional models on several benchmarks, enhancing response relevance, coherence, and dialogue quality.
PackVFL: Efficient HE Packing for Vertical Federated Learning
May 01, 2024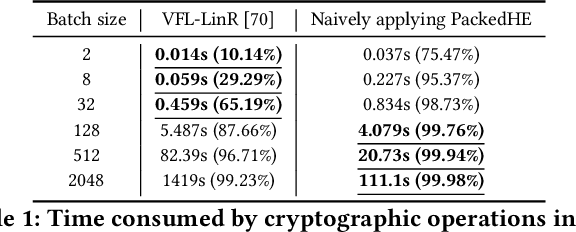
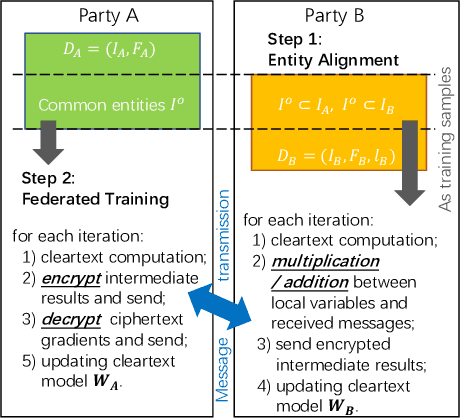
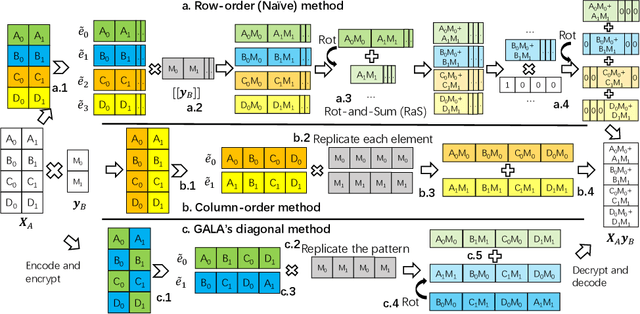

As an essential tool of secure distributed machine learning, vertical federated learning (VFL) based on homomorphic encryption (HE) suffers from severe efficiency problems due to data inflation and time-consuming operations. To this core, we propose PackVFL, an efficient VFL framework based on packed HE (PackedHE), to accelerate the existing HE-based VFL algorithms. PackVFL packs multiple cleartexts into one ciphertext and supports single-instruction-multiple-data (SIMD)-style parallelism. We focus on designing a high-performant matrix multiplication (MatMult) method since it takes up most of the ciphertext computation time in HE-based VFL. Besides, devising the MatMult method is also challenging for PackedHE because a slight difference in the packing way could predominantly affect its computation and communication costs. Without domain-specific design, directly applying SOTA MatMult methods is hard to achieve optimal. Therefore, we make a three-fold design: 1) we systematically explore the current design space of MatMult and quantify the complexity of existing approaches to provide guidance; 2) we propose a hybrid MatMult method according to the unique characteristics of VFL; 3) we adaptively apply our hybrid method in representative VFL algorithms, leveraging distinctive algorithmic properties to further improve efficiency. As the batch size, feature dimension and model size of VFL scale up to large sizes, PackVFL consistently delivers enhanced performance. Empirically, PackVFL propels existing VFL algorithms to new heights, achieving up to a 51.52X end-to-end speedup. This represents a substantial 34.51X greater speedup compared to the direct application of SOTA MatMult methods.
A Survey for Federated Learning Evaluations: Goals and Measures
Aug 23, 2023



Evaluation is a systematic approach to assessing how well a system achieves its intended purpose. Federated learning (FL) is a novel paradigm for privacy-preserving machine learning that allows multiple parties to collaboratively train models without sharing sensitive data. However, evaluating FL is challenging due to its interdisciplinary nature and diverse goals, such as utility, efficiency, and security. In this survey, we first review the major evaluation goals adopted in the existing studies and then explore the evaluation metrics used for each goal. We also introduce FedEval, an open-source platform that provides a standardized and comprehensive evaluation framework for FL algorithms in terms of their utility, efficiency, and security. Finally, we discuss several challenges and future research directions for FL evaluation.
UCTB: An Urban Computing Tool Box for Spatiotemporal Crowd Flow Prediction
Jun 07, 2023Spatiotemporal crowd flow prediction is one of the key technologies in smart cities. Currently, there are two major pain points that plague related research and practitioners. Firstly, crowd flow is related to multiple domain knowledge factors; however, due to the diversity of application scenarios, it is difficult for subsequent work to make reasonable and comprehensive use of domain knowledge. Secondly, with the development of deep learning technology, the implementation of relevant techniques has become increasingly complex; reproducing advanced models has become a time-consuming and increasingly cumbersome task. To address these issues, we design and implement a spatiotemporal crowd flow prediction toolbox called UCTB (Urban Computing Tool Box), which integrates multiple spatiotemporal domain knowledge and state-of-the-art models simultaneously. The relevant code and supporting documents have been open-sourced at https://github.com/uctb/UCTB.
A Survey on Vertical Federated Learning: From a Layered Perspective
Apr 04, 2023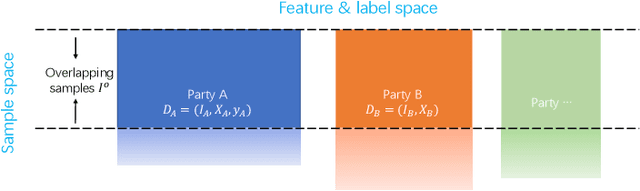

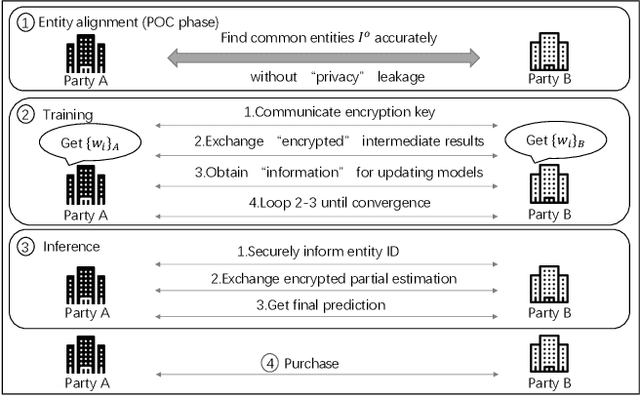
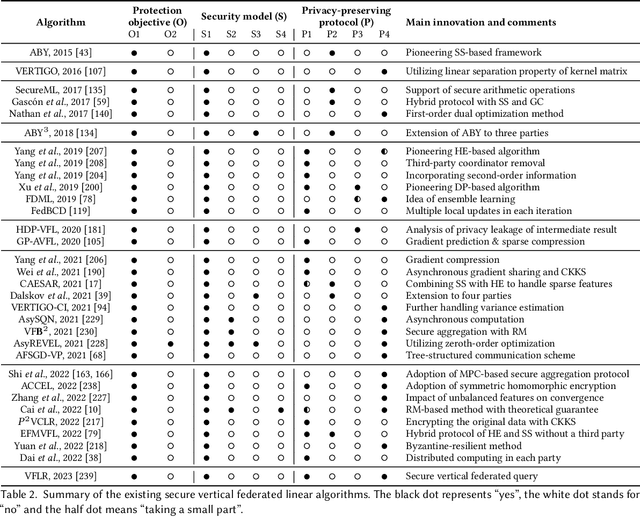
Vertical federated learning (VFL) is a promising category of federated learning for the scenario where data is vertically partitioned and distributed among parties. VFL enriches the description of samples using features from different parties to improve model capacity. Compared with horizontal federated learning, in most cases, VFL is applied in the commercial cooperation scenario of companies. Therefore, VFL contains tremendous business values. In the past few years, VFL has attracted more and more attention in both academia and industry. In this paper, we systematically investigate the current work of VFL from a layered perspective. From the hardware layer to the vertical federated system layer, researchers contribute to various aspects of VFL. Moreover, the application of VFL has covered a wide range of areas, e.g., finance, healthcare, etc. At each layer, we categorize the existing work and explore the challenges for the convenience of further research and development of VFL. Especially, we design a novel MOSP tree taxonomy to analyze the core component of VFL, i.e., secure vertical federated machine learning algorithm. Our taxonomy considers four dimensions, i.e., machine learning model (M), protection object (O), security model (S), and privacy-preserving protocol (P), and provides a comprehensive investigation.
Secure Forward Aggregation for Vertical Federated Neural Networks
Jun 28, 2022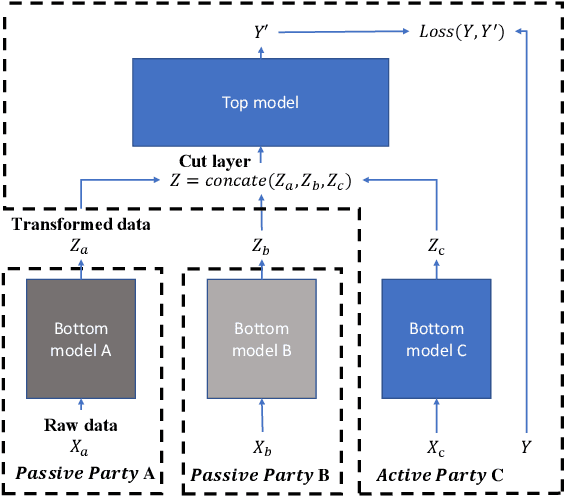


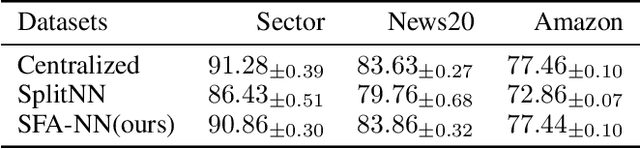
Vertical federated learning (VFL) is attracting much attention because it enables cross-silo data cooperation in a privacy-preserving manner. While most research works in VFL focus on linear and tree models, deep models (e.g., neural networks) are not well studied in VFL. In this paper, we focus on SplitNN, a well-known neural network framework in VFL, and identify a trade-off between data security and model performance in SplitNN. Briefly, SplitNN trains the model by exchanging gradients and transformed data. On the one hand, SplitNN suffers from the loss of model performance since multiply parties jointly train the model using transformed data instead of raw data, and a large amount of low-level feature information is discarded. On the other hand, a naive solution of increasing the model performance through aggregating at lower layers in SplitNN (i.e., the data is less transformed and more low-level feature is preserved) makes raw data vulnerable to inference attacks. To mitigate the above trade-off, we propose a new neural network protocol in VFL called Security Forward Aggregation (SFA). It changes the way of aggregating the transformed data and adopts removable masks to protect the raw data. Experiment results show that networks with SFA achieve both data security and high model performance.
Aegis: A Trusted, Automatic and Accurate Verification Framework for Vertical Federated Learning
Aug 23, 2021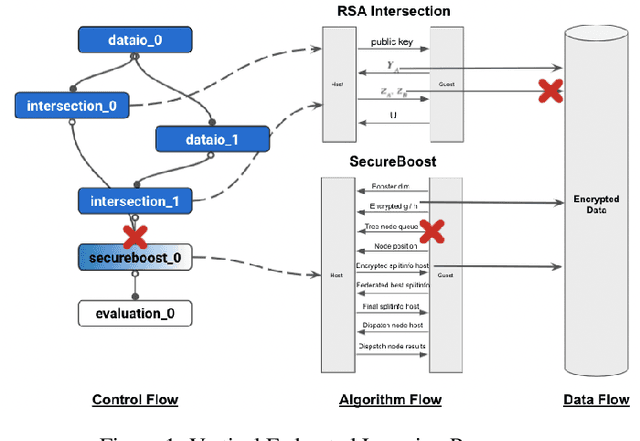
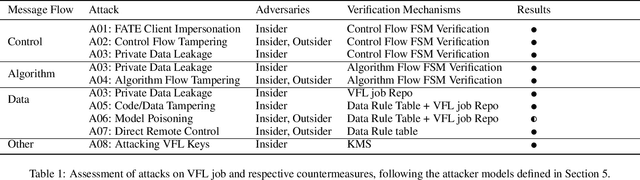
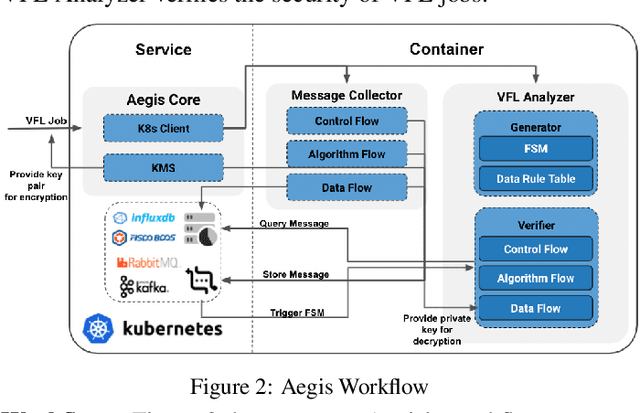
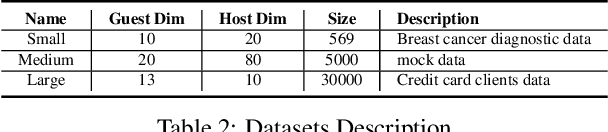
Vertical federated learning (VFL) leverages various privacy-preserving algorithms, e.g., homomorphic encryption or secret sharing based SecureBoost, to ensure data privacy. However, these algorithms all require a semi-honest secure definition, which raises concerns in real-world applications. In this paper, we present Aegis, a trusted, automatic, and accurate verification framework to verify the security of VFL jobs. Aegis is separated from local parties to ensure the security of the framework. Furthermore, it automatically adapts to evolving VFL algorithms by defining the VFL job as a finite state machine to uniformly verify different algorithms and reproduce the entire job to provide more accurate verification. We implement and evaluate Aegis with different threat models on financial and medical datasets. Evaluation results show that: 1) Aegis can detect 95% threat models, and 2) it provides fine-grained verification results within 84% of the total VFL job time.
FedEval: A Benchmark System with a Comprehensive Evaluation Model for Federated Learning
Nov 25, 2020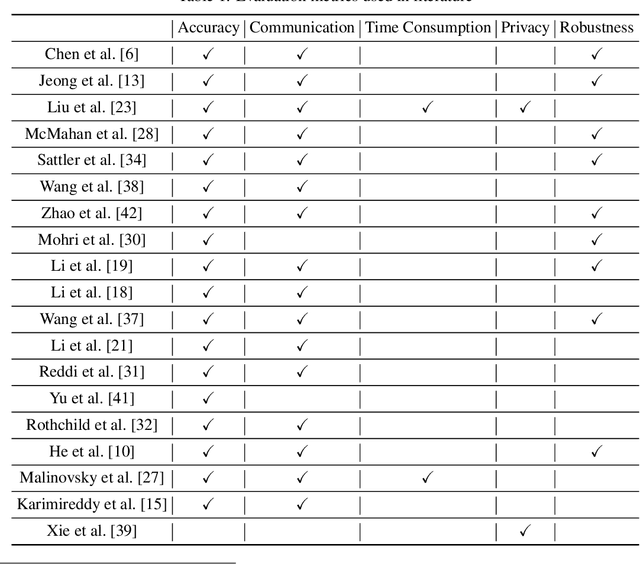

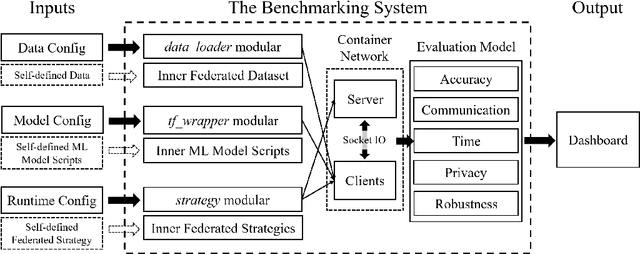
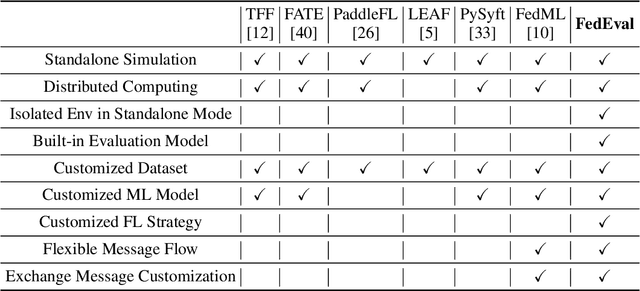
As an innovative solution for privacy-preserving machine learning (ML), federated learning (FL) is attracting much attention from research and industry areas. While new technologies proposed in the past few years do evolve the FL area, unfortunately, the evaluation results presented in these works fall short in integrity and are hardly comparable because of the inconsistent evaluation metrics and the lack of a common platform. In this paper, we propose a comprehensive evaluation framework for FL systems. Specifically, we first introduce the ACTPR model, which defines five metrics that cannot be excluded in FL evaluation, including Accuracy, Communication, Time efficiency, Privacy, and Robustness. Then we design and implement a benchmarking system called FedEval, which enables the systematic evaluation and comparison of existing works under consistent experimental conditions. We then provide an in-depth benchmarking study between the two most widely-used FL mechanisms, FedSGD and FedAvg. The benchmarking results show that FedSGD and FedAvg both have advantages and disadvantages under the ACTPR model. For example, FedSGD is barely influenced by the none independent and identically distributed (non-IID) data problem, but FedAvg suffers from a decline in accuracy of up to 9% in our experiments. On the other hand, FedAvg is more efficient than FedSGD regarding time consumption and communication. Lastly, we excavate a set of take-away conclusions, which are very helpful for researchers in the FL area.
Exploring the Generalizability of Spatio-Temporal Crowd Flow Prediction: Meta-Modeling and an Analytic Framework
Sep 20, 2020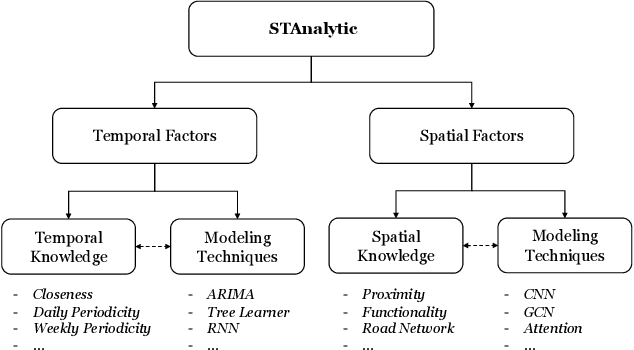

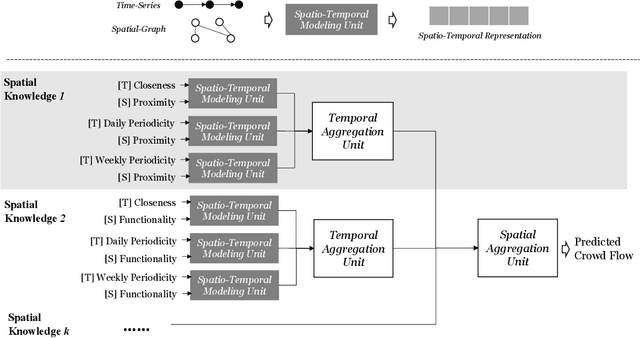

The Spatio-Temporal Crowd Flow Prediction (STCFP) problem is a classical problem with plenty of prior research efforts that benefit from traditional statistical learning and recent deep learning approaches. While STCFP can refer to many real-world problems, most existing studies focus on quite specific applications, such as the prediction of taxi demand, ridesharing order, and so on. This hinders the STCFP research as the approaches designed for different applications are hardly comparable, and thus how an applicationdriven approach can be generalized to other scenarios is unclear. To fill in this gap, this paper makes two efforts: (i) we propose an analytic framework, called STAnalytic, to qualitatively investigate STCFP approaches regarding their design considerations on various spatial and temporal factors, aiming to make different application-driven approaches comparable; (ii) we construct an extensively large-scale STCFP benchmark datasets with four different scenarios (including ridesharing, bikesharing, metro, and electrical vehicle charging) with up to hundreds of millions of flow records, to quantitatively measure the generalizability of STCFP approaches. Furthermore, to elaborate the effectiveness of STAnalytic in helping design generalizable STCFP approaches, we propose a spatio-temporal meta-model, called STMeta, by integrating generalizable temporal and spatial knowledge identified by STAnalytic. We implement three variants of STMeta with different deep learning techniques. With the datasets, we demonstrate that STMeta variants can outperform state-of-the-art STCFP approaches by 5%.
Secure Federated Matrix Factorization
Jun 12, 2019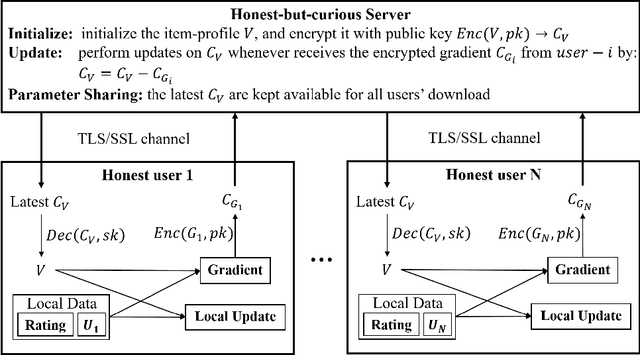
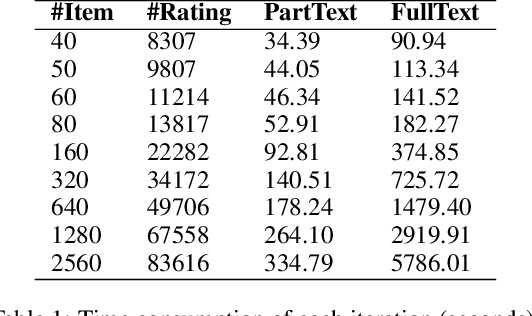
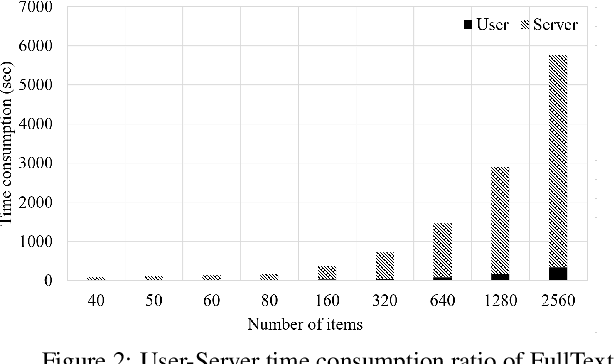
To protect user privacy and meet law regulations, federated (machine) learning is obtaining vast interests in recent years. The key principle of federated learning is training a machine learning model without needing to know each user's personal raw private data. In this paper, we propose a secure matrix factorization framework under the federated learning setting, called FedMF. First, we design a user-level distributed matrix factorization framework where the model can be learned when each user only uploads the gradient information (instead of the raw preference data) to the server. While gradient information seems secure, we prove that it could still leak users' raw data. To this end, we enhance the distributed matrix factorization framework with homomorphic encryption. We implement the prototype of FedMF and test it with a real movie rating dataset. Results verify the feasibility of FedMF. We also discuss the challenges for applying FedMF in practice for future research.