 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Multi-view Pixel Contrast for General and Robust Image Forgery Localization
Jun 19, 2024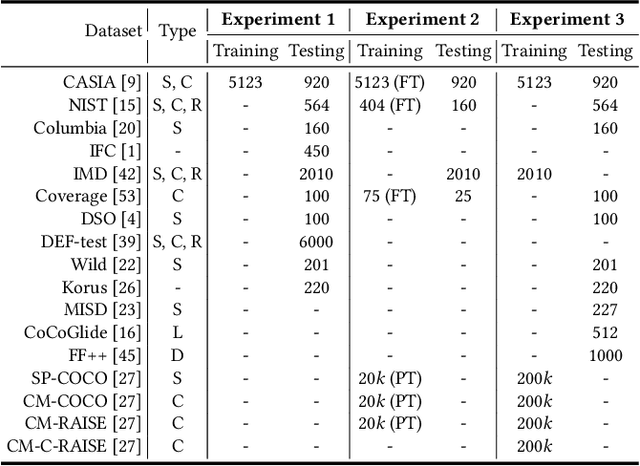
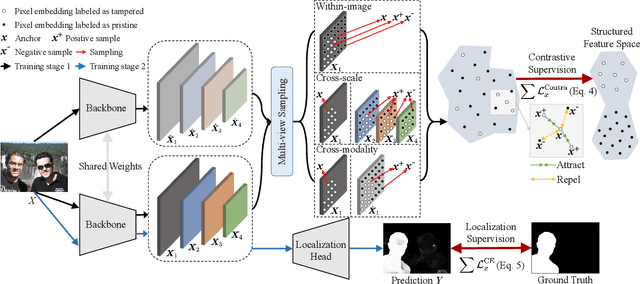
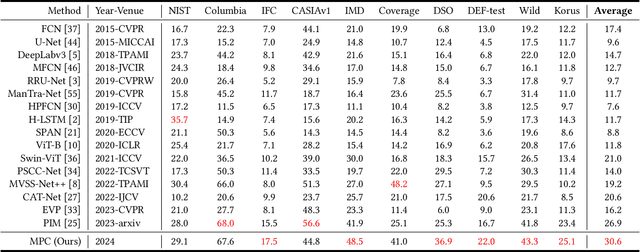
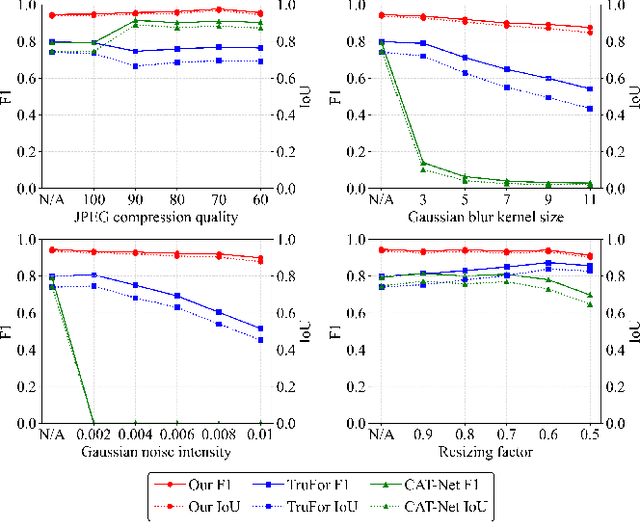
Image forgery localization, which aims to segment tampered regions in an image, is a fundamental yet challenging digital forensic task. While some deep learning-based forensic methods have achieved impressive results, they directly learn pixel-to-label mappings without fully exploiting the relationship between pixels in the feature space. To address such deficiency, we propose a Multi-view Pixel-wise Contrastive algorithm (MPC) for image forgery localization. Specifically, we first pre-train the backbone network with the supervised contrastive loss to model pixel relationships from the perspectives of within-image, cross-scale and cross-modality. That is aimed at increasing intra-class compactness and inter-class separability. Then the localization head is fine-tuned using the cross-entropy loss, resulting in a better pixel localizer. The MPC is trained on three different scale training datasets to make a comprehensive and fair comparison with existing image forgery localization algorithms. Extensive experiments on the small, medium and large scale training datasets show that the proposed MPC achieves higher generalization performance and robustness against post-processing than the state-of-the-arts. Code will be available at https://github.com/multimediaFor/MPC.
Progressive Feedback-Enhanced Transformer for Image Forgery Localization
Nov 15, 2023Blind detection of the forged regions in digital images is an effective authentication means to counter the malicious use of local image editing techniques. Existing encoder-decoder forensic networks overlook the fact that detecting complex and subtle tampered regions typically requires more feedback information. In this paper, we propose a Progressive FeedbACk-enhanced Transformer (ProFact) network to achieve coarse-to-fine image forgery localization. Specifically, the coarse localization map generated by an initial branch network is adaptively fed back to the early transformer encoder layers for enhancing the representation of positive features while suppressing interference factors. The cascaded transformer network, combined with a contextual spatial pyramid module, is designed to refine discriminative forensic features for improving the forgery localization accuracy and reliability. Furthermore, we present an effective strategy to automatically generate large-scale forged image samples close to real-world forensic scenarios, especially in realistic and coherent processing. Leveraging on such samples, a progressive and cost-effective two-stage training protocol is applied to the ProFact network. The extensive experimental results on nine public forensic datasets show that our proposed localizer greatly outperforms the state-of-the-art on the generalization ability and robustness of image forgery localization. Code will be publicly available at https://github.com/multimediaFor/ProFact.
Transferable Adversarial Attack on Image Tampering Localization
Sep 19, 2023It is significant to evaluate the security of existing digital image tampering localization algorithms in real-world applications. In this paper, we propose an adversarial attack scheme to reveal the reliability of such tampering localizers, which would be fooled and fail to predict altered regions correctly. Specifically, the adversarial examples based on optimization and gradient are implemented for white/black-box attacks. Correspondingly, the adversarial example is optimized via reverse gradient propagation, and the perturbation is added adaptively in the direction of gradient rising. The black-box attack is achieved by relying on the transferability of such adversarial examples to different localizers. Extensive evaluations verify that the proposed attack sharply reduces the localization accuracy while preserving high visual quality of the attacked images.
Effective Image Tampering Localization via Enhanced Transformer and Co-attention Fusion
Sep 17, 2023Powerful manipulation techniques have made digital image forgeries be easily created and widespread without leaving visual anomalies. The blind localization of tampered regions becomes quite significant for image forensics. In this paper, we propose an effective image tampering localization network (EITLNet) based on a two-branch enhanced transformer encoder with attention-based feature fusion. Specifically, a feature enhancement module is designed to enhance the feature representation ability of the transformer encoder. The features extracted from RGB and noise streams are fused effectively by the coordinate attention-based fusion module at multiple scales. Extensive experimental results verify that the proposed scheme achieves the state-of-the-art generalization ability and robustness in various benchmark datasets. Code will be public at https://github.com/multimediaFor/EITLNet.
Effective Image Tampering Localization via Semantic Segmentation Network
Aug 30, 2022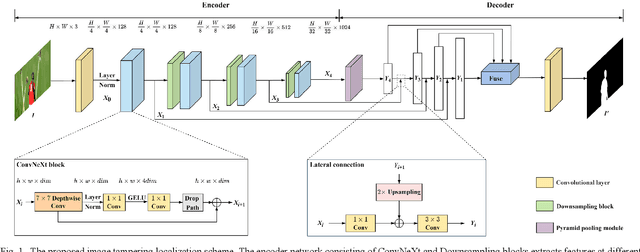



With the widespread use of powerful image editing tools, image tampering becomes easy and realistic. Existing image forensic methods still face challenges of low accuracy and robustness. Note that the tampered regions are typically semantic objects, in this letter we propose an effective image tampering localization scheme based on deep semantic segmentation network. ConvNeXt network is used as an encoder to learn better feature representation. The multi-scale features are then fused by Upernet decoder for achieving better locating capability. Combined loss and effective data augmentation are adopted to ensure effective model training. Extensive experimental results confirm that localization performance of our proposed scheme outperforms other state-of-the-art ones.