 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom User Interface to Agent Interface: Efficiency Optimization of UI Representations for LLM Agents
Dec 15, 2025
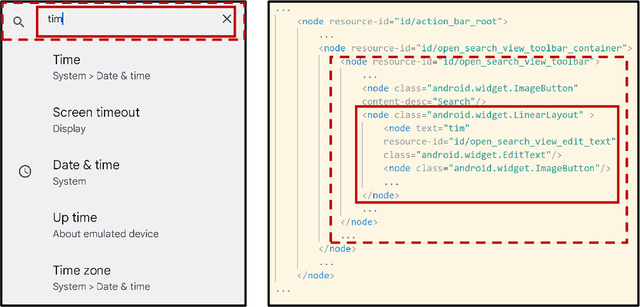
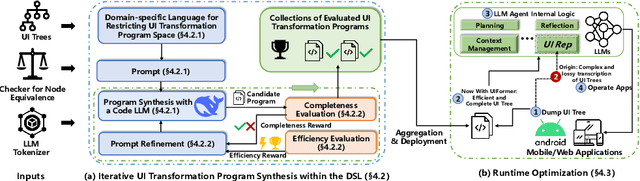
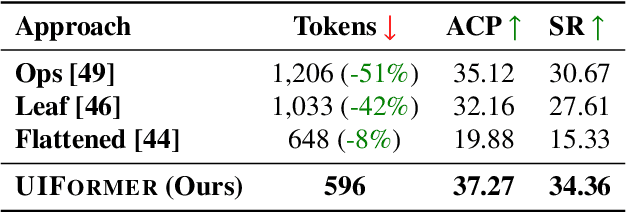
While Large Language Model (LLM) agents show great potential for automated UI navigation such as automated UI testing and AI assistants, their efficiency has been largely overlooked. Our motivating study reveals that inefficient UI representation creates a critical performance bottleneck. However, UI representation optimization, formulated as the task of automatically generating programs that transform UI representations, faces two unique challenges. First, the lack of Boolean oracles, which traditional program synthesis uses to decisively validate semantic correctness, poses a fundamental challenge to co-optimization of token efficiency and completeness. Second, the need to process large, complex UI trees as input while generating long, compositional transformation programs, making the search space vast and error-prone. Toward addressing the preceding limitations, we present UIFormer, the first automated optimization framework that synthesizes UI transformation programs by conducting constraint-based optimization with structured decomposition of the complex synthesis task. First, UIFormer restricts the program space using a domain-specific language (DSL) that captures UI-specific operations. Second, UIFormer conducts LLM-based iterative refinement with correctness and efficiency rewards, providing guidance for achieving the efficiency-completeness co-optimization. UIFormer operates as a lightweight plugin that applies transformation programs for seamless integration with existing LLM agents, requiring minimal modifications to their core logic. Evaluations across three UI navigation benchmarks spanning Android and Web platforms with five LLMs demonstrate that UIFormer achieves 48.7% to 55.8% token reduction with minimal runtime overhead while maintaining or improving agent performance. Real-world industry deployment at WeChat further validates the practical impact of UIFormer.
Transferable Dual-Domain Feature Importance Attack against AI-Generated Image Detector
Nov 19, 2025Recent AI-generated image (AIGI) detectors achieve impressive accuracy under clean condition. In view of antiforensics, it is significant to develop advanced adversarial attacks for evaluating the security of such detectors, which remains unexplored sufficiently. This letter proposes a Dual-domain Feature Importance Attack (DuFIA) scheme to invalidate AIGI detectors to some extent. Forensically important features are captured by the spatially interpolated gradient and frequency-aware perturbation. The adversarial transferability is enhanced by jointly modeling spatial and frequency-domain feature importances, which are fused to guide the optimization-based adversarial example generation. Extensive experiments across various AIGI detectors verify the cross-model transferability, transparency and robustness of DuFIA.
Image Forgery Localization with State Space Models
Dec 15, 2024



Pixel dependency modeling from tampered images is pivotal for image forgery localization. Current approaches predominantly rely on convolutional neural network (CNN) or Transformer-based models, which often either lack sufficient receptive fields or entail significant computational overheads. In this paper, we propose LoMa, a novel image forgery localization method that leverages the Selective State Space (S6) model for global pixel dependency modeling and inverted residual CNN for local pixel dependency modeling. Our method introduces the Mixed-SSM Block, which initially employs atrous selective scan to traverse the spatial domain and convert the tampered image into order patch sequences, and subsequently applies multidirectional S6 modeling. In addition, an auxiliary convolutional branch is introduced to enhance local feature extraction. This design facilitates the efficient extraction of global dependencies while upholding linear complexity. Upon modeling the pixel dependency with the SSM and CNN blocks, the pixel-wise forgery localization results are obtained by a simple MLP decoder. Extensive experimental results validate the superiority of LoMa over CNN-based and Transformer-based state-of-the-arts.
Video Inpainting Localization with Contrastive Learning
Jun 25, 2024



Deep video inpainting is typically used as malicious manipulation to remove important objects for creating fake videos. It is significant to identify the inpainted regions blindly. This letter proposes a simple yet effective forensic scheme for Video Inpainting LOcalization with ContrAstive Learning (ViLocal). Specifically, a 3D Uniformer encoder is applied to the video noise residual for learning effective spatiotemporal forensic features. To enhance the discriminative power, supervised contrastive learning is adopted to capture the local inconsistency of inpainted videos through attracting/repelling the positive/negative pristine and forged pixel pairs. A pixel-wise inpainting localization map is yielded by a lightweight convolution decoder with a specialized two-stage training strategy. To prepare enough training samples, we build a video object segmentation dataset of 2500 videos with pixel-level annotations per frame. Extensive experimental results validate the superiority of ViLocal over state-of-the-arts. Code and dataset will be available at https://github.com/multimediaFor/ViLocal.
Trusted Video Inpainting Localization via Deep Attentive Noise Learning
Jun 19, 2024



Digital video inpainting techniques have been substantially improved with deep learning in recent years. Although inpainting is originally designed to repair damaged areas, it can also be used as malicious manipulation to remove important objects for creating false scenes and facts. As such it is significant to identify inpainted regions blindly. In this paper, we present a Trusted Video Inpainting Localization network (TruVIL) with excellent robustness and generalization ability. Observing that high-frequency noise can effectively unveil the inpainted regions, we design deep attentive noise learning in multiple stages to capture the inpainting traces. Firstly, a multi-scale noise extraction module based on 3D High Pass (HP3D) layers is used to create the noise modality from input RGB frames. Then the correlation between such two complementary modalities are explored by a cross-modality attentive fusion module to facilitate mutual feature learning. Lastly, spatial details are selectively enhanced by an attentive noise decoding module to boost the localization performance of the network. To prepare enough training samples, we also build a frame-level video object segmentation dataset of 2500 videos with pixel-level annotation for all frames. Extensive experimental results validate the superiority of TruVIL compared with the state-of-the-arts. In particular, both quantitative and qualitative evaluations on various inpainted videos verify the remarkable robustness and generalization ability of our proposed TruVIL. Code and dataset will be available at https://github.com/multimediaFor/TruVIL.
Exploring Multi-view Pixel Contrast for General and Robust Image Forgery Localization
Jun 19, 2024
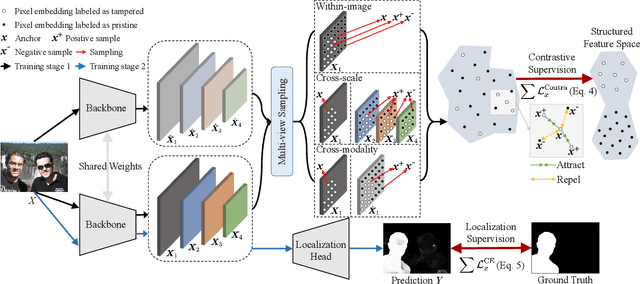
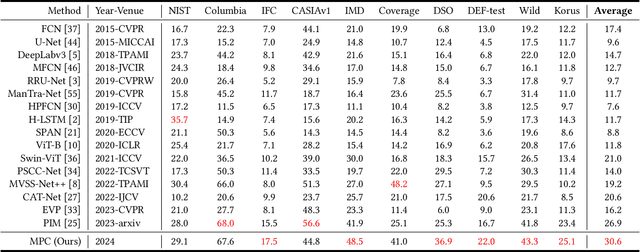
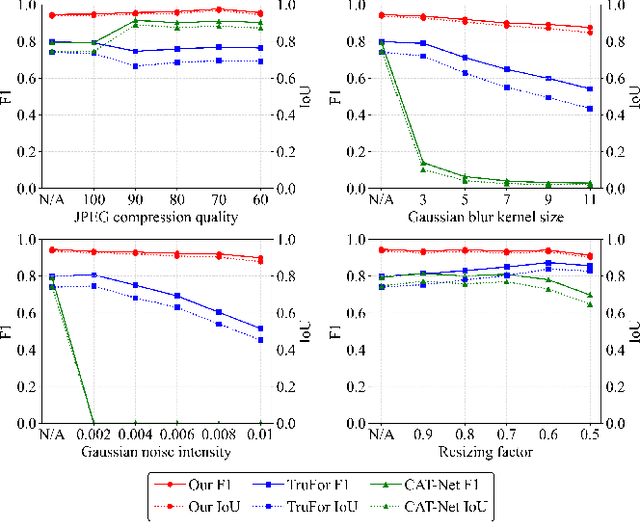
Image forgery localization, which aims to segment tampered regions in an image, is a fundamental yet challenging digital forensic task. While some deep learning-based forensic methods have achieved impressive results, they directly learn pixel-to-label mappings without fully exploiting the relationship between pixels in the feature space. To address such deficiency, we propose a Multi-view Pixel-wise Contrastive algorithm (MPC) for image forgery localization. Specifically, we first pre-train the backbone network with the supervised contrastive loss to model pixel relationships from the perspectives of within-image, cross-scale and cross-modality. That is aimed at increasing intra-class compactness and inter-class separability. Then the localization head is fine-tuned using the cross-entropy loss, resulting in a better pixel localizer. The MPC is trained on three different scale training datasets to make a comprehensive and fair comparison with existing image forgery localization algorithms. Extensive experiments on the small, medium and large scale training datasets show that the proposed MPC achieves higher generalization performance and robustness against post-processing than the state-of-the-arts. Code will be available at https://github.com/multimediaFor/MPC.
AI-Generated Video Detection via Spatio-Temporal Anomaly Learning
Mar 25, 2024The advancement of generation models has led to the emergence of highly realistic artificial intelligence (AI)-generated videos. Malicious users can easily create non-existent videos to spread false information. This letter proposes an effective AI-generated video detection (AIGVDet) scheme by capturing the forensic traces with a two-branch spatio-temporal convolutional neural network (CNN). Specifically, two ResNet sub-detectors are learned separately for identifying the anomalies in spatical and optical flow domains, respectively. Results of such sub-detectors are fused to further enhance the discrimination ability. A large-scale generated video dataset (GVD) is constructed as a benchmark for model training and evaluation. Extensive experimental results verify the high generalization and robustness of our AIGVDet scheme. Code and dataset will be available at https://github.com/multimediaFor/AIGVDet.
Progressive Feedback-Enhanced Transformer for Image Forgery Localization
Nov 15, 2023Blind detection of the forged regions in digital images is an effective authentication means to counter the malicious use of local image editing techniques. Existing encoder-decoder forensic networks overlook the fact that detecting complex and subtle tampered regions typically requires more feedback information. In this paper, we propose a Progressive FeedbACk-enhanced Transformer (ProFact) network to achieve coarse-to-fine image forgery localization. Specifically, the coarse localization map generated by an initial branch network is adaptively fed back to the early transformer encoder layers for enhancing the representation of positive features while suppressing interference factors. The cascaded transformer network, combined with a contextual spatial pyramid module, is designed to refine discriminative forensic features for improving the forgery localization accuracy and reliability. Furthermore, we present an effective strategy to automatically generate large-scale forged image samples close to real-world forensic scenarios, especially in realistic and coherent processing. Leveraging on such samples, a progressive and cost-effective two-stage training protocol is applied to the ProFact network. The extensive experimental results on nine public forensic datasets show that our proposed localizer greatly outperforms the state-of-the-art on the generalization ability and robustness of image forgery localization. Code will be publicly available at https://github.com/multimediaFor/ProFact.
Transferable Adversarial Attack on Image Tampering Localization
Sep 19, 2023It is significant to evaluate the security of existing digital image tampering localization algorithms in real-world applications. In this paper, we propose an adversarial attack scheme to reveal the reliability of such tampering localizers, which would be fooled and fail to predict altered regions correctly. Specifically, the adversarial examples based on optimization and gradient are implemented for white/black-box attacks. Correspondingly, the adversarial example is optimized via reverse gradient propagation, and the perturbation is added adaptively in the direction of gradient rising. The black-box attack is achieved by relying on the transferability of such adversarial examples to different localizers. Extensive evaluations verify that the proposed attack sharply reduces the localization accuracy while preserving high visual quality of the attacked images.
Spatio-temporal Co-attention Fusion Network for Video Splicing Localization
Sep 18, 2023Digital video splicing has become easy and ubiquitous. Malicious users copy some regions of a video and paste them to another video for creating realistic forgeries. It is significant to blindly detect such forgery regions in videos. In this paper, a spatio-temporal co-attention fusion network (SCFNet) is proposed for video splicing localization. Specifically, a three-stream network is used as an encoder to capture manipulation traces across multiple frames. The deep interaction and fusion of spatio-temporal forensic features are achieved by the novel parallel and cross co-attention fusion modules. A lightweight multilayer perceptron (MLP) decoder is adopted to yield a pixel-level tampering localization map. A new large-scale video splicing dataset is created for training the SCFNet. Extensive tests on benchmark datasets show that the localization and generalization performances of our SCFNet outperform the state-of-the-art. Code and datasets will be available at https://github.com/multimediaFor/SCFNet.