 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnergy-Efficient Computation with DVFS using Deep Reinforcement Learning for Multi-Task Systems in Edge Computing
Sep 28, 2024Periodic soft real-time systems have broad applications in many areas, such as IoT. Finding an optimal energy-efficient policy that is adaptable to underlying edge devices while meeting deadlines for tasks has always been challenging. This research studies generalized systems with multi-task, multi-deadline scenarios with reinforcement learning-based DVFS for energy saving. This work addresses the limitation of previous work that models a periodic system as a single task and single-deadline scenario, which is too simplified to cope with complex situations. The method encodes time series information in the Linux kernel into information that is easy to use for reinforcement learning, allowing the system to generate DVFS policies to adapt system patterns based on the general workload. For encoding, we present two different methods for comparison. Both methods use only one performance counter: system utilization and the kernel only needs minimal information from the userspace. Our method is implemented on Jetson Nano Board (2GB) and is tested with three fixed multitask workloads, which are three, five, and eight tasks in the workload, respectively. For randomness and generalization, we also designed a random workload generator to build different multitask workloads to test. Based on the test results, our method could save 3%-10% power compared to Linux built-in governors.
Video Inpainting Localization with Contrastive Learning
Jun 25, 2024



Deep video inpainting is typically used as malicious manipulation to remove important objects for creating fake videos. It is significant to identify the inpainted regions blindly. This letter proposes a simple yet effective forensic scheme for Video Inpainting LOcalization with ContrAstive Learning (ViLocal). Specifically, a 3D Uniformer encoder is applied to the video noise residual for learning effective spatiotemporal forensic features. To enhance the discriminative power, supervised contrastive learning is adopted to capture the local inconsistency of inpainted videos through attracting/repelling the positive/negative pristine and forged pixel pairs. A pixel-wise inpainting localization map is yielded by a lightweight convolution decoder with a specialized two-stage training strategy. To prepare enough training samples, we build a video object segmentation dataset of 2500 videos with pixel-level annotations per frame. Extensive experimental results validate the superiority of ViLocal over state-of-the-arts. Code and dataset will be available at https://github.com/multimediaFor/ViLocal.
Trusted Video Inpainting Localization via Deep Attentive Noise Learning
Jun 19, 2024



Digital video inpainting techniques have been substantially improved with deep learning in recent years. Although inpainting is originally designed to repair damaged areas, it can also be used as malicious manipulation to remove important objects for creating false scenes and facts. As such it is significant to identify inpainted regions blindly. In this paper, we present a Trusted Video Inpainting Localization network (TruVIL) with excellent robustness and generalization ability. Observing that high-frequency noise can effectively unveil the inpainted regions, we design deep attentive noise learning in multiple stages to capture the inpainting traces. Firstly, a multi-scale noise extraction module based on 3D High Pass (HP3D) layers is used to create the noise modality from input RGB frames. Then the correlation between such two complementary modalities are explored by a cross-modality attentive fusion module to facilitate mutual feature learning. Lastly, spatial details are selectively enhanced by an attentive noise decoding module to boost the localization performance of the network. To prepare enough training samples, we also build a frame-level video object segmentation dataset of 2500 videos with pixel-level annotation for all frames. Extensive experimental results validate the superiority of TruVIL compared with the state-of-the-arts. In particular, both quantitative and qualitative evaluations on various inpainted videos verify the remarkable robustness and generalization ability of our proposed TruVIL. Code and dataset will be available at https://github.com/multimediaFor/TruVIL.
AI-Generated Video Detection via Spatio-Temporal Anomaly Learning
Mar 25, 2024The advancement of generation models has led to the emergence of highly realistic artificial intelligence (AI)-generated videos. Malicious users can easily create non-existent videos to spread false information. This letter proposes an effective AI-generated video detection (AIGVDet) scheme by capturing the forensic traces with a two-branch spatio-temporal convolutional neural network (CNN). Specifically, two ResNet sub-detectors are learned separately for identifying the anomalies in spatical and optical flow domains, respectively. Results of such sub-detectors are fused to further enhance the discrimination ability. A large-scale generated video dataset (GVD) is constructed as a benchmark for model training and evaluation. Extensive experimental results verify the high generalization and robustness of our AIGVDet scheme. Code and dataset will be available at https://github.com/multimediaFor/AIGVDet.
Spatio-temporal Co-attention Fusion Network for Video Splicing Localization
Sep 18, 2023Digital video splicing has become easy and ubiquitous. Malicious users copy some regions of a video and paste them to another video for creating realistic forgeries. It is significant to blindly detect such forgery regions in videos. In this paper, a spatio-temporal co-attention fusion network (SCFNet) is proposed for video splicing localization. Specifically, a three-stream network is used as an encoder to capture manipulation traces across multiple frames. The deep interaction and fusion of spatio-temporal forensic features are achieved by the novel parallel and cross co-attention fusion modules. A lightweight multilayer perceptron (MLP) decoder is adopted to yield a pixel-level tampering localization map. A new large-scale video splicing dataset is created for training the SCFNet. Extensive tests on benchmark datasets show that the localization and generalization performances of our SCFNet outperform the state-of-the-art. Code and datasets will be available at https://github.com/multimediaFor/SCFNet.
CPU frequency scheduling of real-time applications on embedded devices with temporal encoding-based deep reinforcement learning
Sep 07, 2023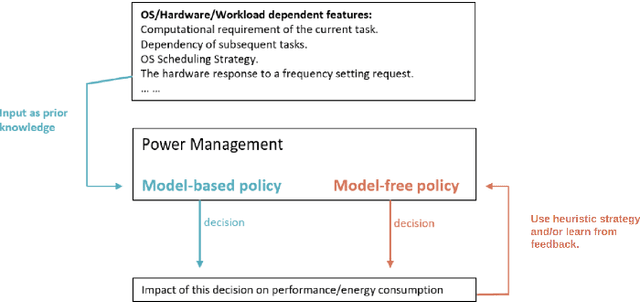
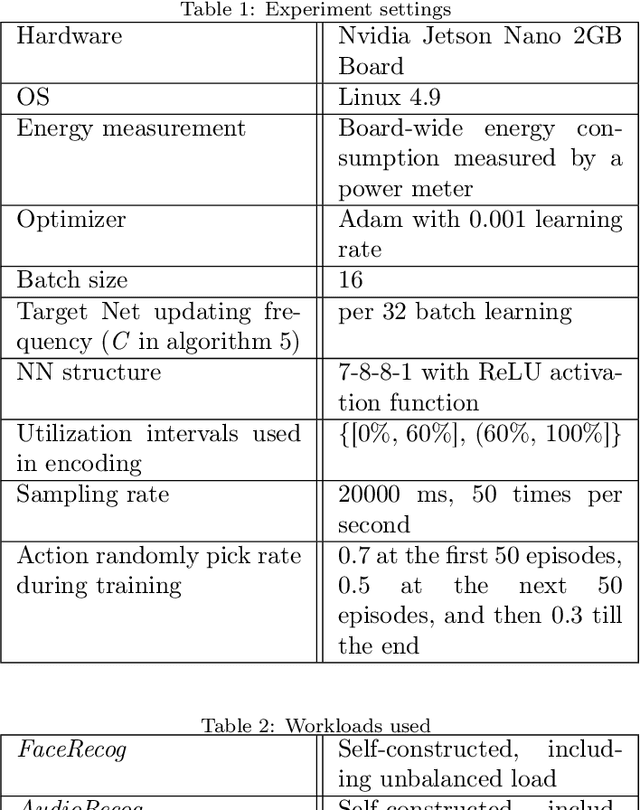
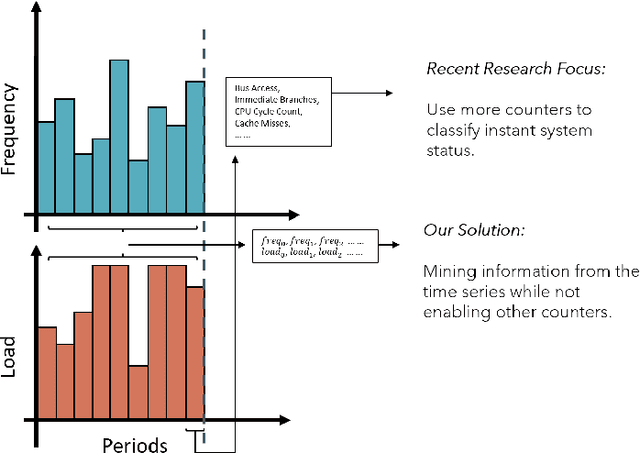
Small devices are frequently used in IoT and smart-city applications to perform periodic dedicated tasks with soft deadlines. This work focuses on developing methods to derive efficient power-management methods for periodic tasks on small devices. We first study the limitations of the existing Linux built-in methods used in small devices. We illustrate three typical workload/system patterns that are challenging to manage with Linux's built-in solutions. We develop a reinforcement-learning-based technique with temporal encoding to derive an effective DVFS governor even with the presence of the three system patterns. The derived governor uses only one performance counter, the same as the built-in Linux mechanism, and does not require an explicit task model for the workload. We implemented a prototype system on the Nvidia Jetson Nano Board and experimented with it with six applications, including two self-designed and four benchmark applications. Under different deadline constraints, our approach can quickly derive a DVFS governor that can adapt to performance requirements and outperform the built-in Linux approach in energy saving. On Mibench workloads, with performance slack ranging from 0.04 s to 0.4 s, the proposed method can save 3% - 11% more energy compared to Ondemand. AudioReg and FaceReg applications tested have 5%- 14% energy-saving improvement. We have open-sourced the implementation of our in-kernel quantized neural network engine. The codebase can be found at: https://github.com/coladog/tinyagent.
* Accepted to Journal of Systems Architecture
Black-Box Attack against GAN-Generated Image Detector with Contrastive Perturbation
Nov 07, 2022



Visually realistic GAN-generated facial images raise obvious concerns on potential misuse. Many effective forensic algorithms have been developed to detect such synthetic images in recent years. It is significant to assess the vulnerability of such forensic detectors against adversarial attacks. In this paper, we propose a new black-box attack method against GAN-generated image detectors. A novel contrastive learning strategy is adopted to train the encoder-decoder network based anti-forensic model under a contrastive loss function. GAN images and their simulated real counterparts are constructed as positive and negative samples, respectively. Leveraging on the trained attack model, imperceptible contrastive perturbation could be applied to input synthetic images for removing GAN fingerprint to some extent. As such, existing GAN-generated image detectors are expected to be deceived. Extensive experimental results verify that the proposed attack effectively reduces the accuracy of three state-of-the-art detectors on six popular GANs. High visual quality of the attacked images is also achieved. The source code will be available at https://github.com/ZXMMD/BAttGAND.