 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePortraitCraft: A Benchmark for Portrait Composition Understanding and Generation
Apr 04, 2026Portrait composition plays a central role in portrait aesthetics and visual communication, yet existing datasets and benchmarks mainly focus on coarse aesthetic scoring, generic image aesthetics, or unconstrained portrait generation. This limits systematic research on structured portrait composition analysis and controllable portrait generation under explicit composition requirements. In this paper, we introduce PortraitCraft, a unified benchmark for portrait composition understanding and generation. PortraitCraft is built on a dataset of approximately 50,000 curated real portrait images with structured multi-level supervision, including global composition scores, annotations over 13 composition attributes, attribute-level explanation texts, visual question answering pairs, and composition-oriented textual descriptions for generation. Based on this dataset, we establish two complementary benchmark tasks for composition understanding and composition-aware generation within a unified framework. The first evaluates portrait composition understanding through score prediction, fine-grained attribute reasoning, and image-grounded visual question answering, while the second evaluates portrait generation from structured composition descriptions under explicit composition constraints. We further define standardized evaluation protocols and provide reference baseline results with representative multimodal models. PortraitCraft provides a comprehensive benchmark for future research on fine-grained portrait understanding, interpretable aesthetic assessment, and controllable portrait generation.
Learning Stochastic Bridges for Video Object Removal via Video-to-Video Translation
Jan 17, 2026Existing video object removal methods predominantly rely on diffusion models following a noise-to-data paradigm, where generation starts from uninformative Gaussian noise. This approach discards the rich structural and contextual priors present in the original input video. Consequently, such methods often lack sufficient guidance, leading to incomplete object erasure or the synthesis of implausible content that conflicts with the scene's physical logic. In this paper, we reformulate video object removal as a video-to-video translation task via a stochastic bridge model. Unlike noise-initialized methods, our framework establishes a direct stochastic path from the source video (with objects) to the target video (objects removed). This bridge formulation effectively leverages the input video as a strong structural prior, guiding the model to perform precise removal while ensuring that the filled regions are logically consistent with the surrounding environment. To address the trade-off where strong bridge priors hinder the removal of large objects, we propose a novel adaptive mask modulation strategy. This mechanism dynamically modulates input embeddings based on mask characteristics, balancing background fidelity with generative flexibility. Extensive experiments demonstrate that our approach significantly outperforms existing methods in both visual quality and temporal consistency.
Image Forgery Localization with State Space Models
Dec 15, 2024



Pixel dependency modeling from tampered images is pivotal for image forgery localization. Current approaches predominantly rely on convolutional neural network (CNN) or Transformer-based models, which often either lack sufficient receptive fields or entail significant computational overheads. In this paper, we propose LoMa, a novel image forgery localization method that leverages the Selective State Space (S6) model for global pixel dependency modeling and inverted residual CNN for local pixel dependency modeling. Our method introduces the Mixed-SSM Block, which initially employs atrous selective scan to traverse the spatial domain and convert the tampered image into order patch sequences, and subsequently applies multidirectional S6 modeling. In addition, an auxiliary convolutional branch is introduced to enhance local feature extraction. This design facilitates the efficient extraction of global dependencies while upholding linear complexity. Upon modeling the pixel dependency with the SSM and CNN blocks, the pixel-wise forgery localization results are obtained by a simple MLP decoder. Extensive experimental results validate the superiority of LoMa over CNN-based and Transformer-based state-of-the-arts.
Video Inpainting Localization with Contrastive Learning
Jun 25, 2024



Deep video inpainting is typically used as malicious manipulation to remove important objects for creating fake videos. It is significant to identify the inpainted regions blindly. This letter proposes a simple yet effective forensic scheme for Video Inpainting LOcalization with ContrAstive Learning (ViLocal). Specifically, a 3D Uniformer encoder is applied to the video noise residual for learning effective spatiotemporal forensic features. To enhance the discriminative power, supervised contrastive learning is adopted to capture the local inconsistency of inpainted videos through attracting/repelling the positive/negative pristine and forged pixel pairs. A pixel-wise inpainting localization map is yielded by a lightweight convolution decoder with a specialized two-stage training strategy. To prepare enough training samples, we build a video object segmentation dataset of 2500 videos with pixel-level annotations per frame. Extensive experimental results validate the superiority of ViLocal over state-of-the-arts. Code and dataset will be available at https://github.com/multimediaFor/ViLocal.
Exploring Multi-view Pixel Contrast for General and Robust Image Forgery Localization
Jun 19, 2024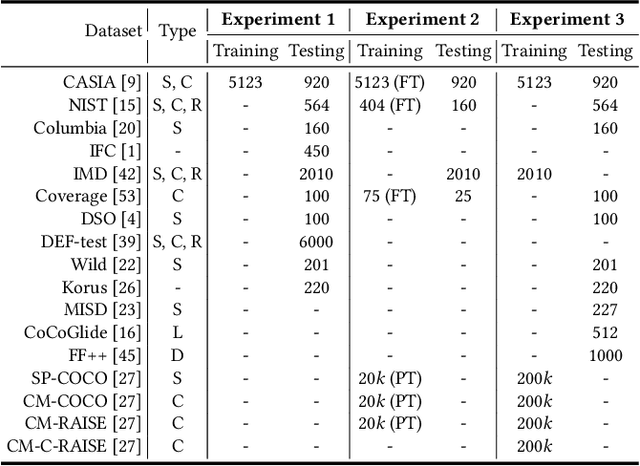
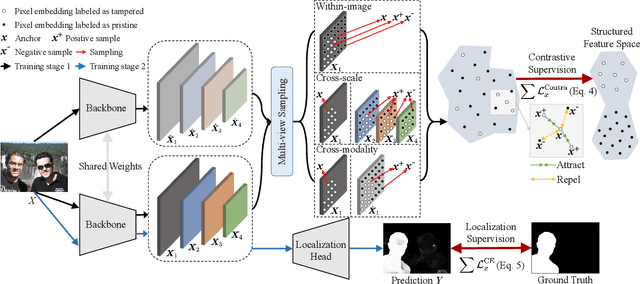
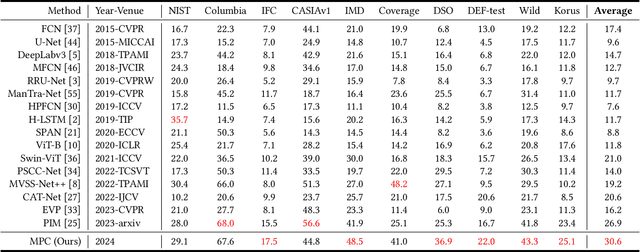
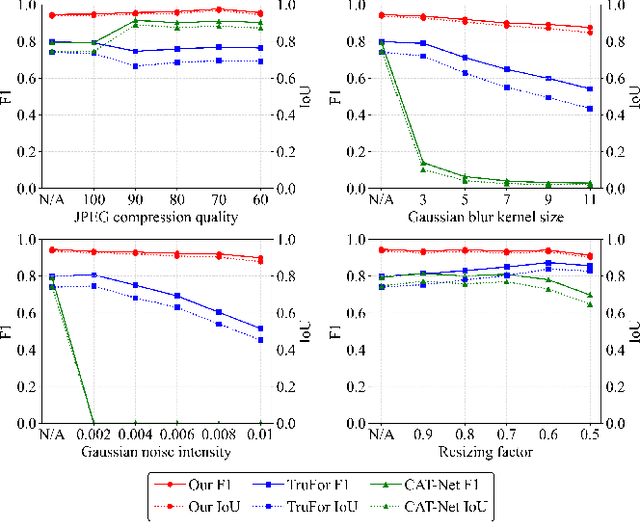
Image forgery localization, which aims to segment tampered regions in an image, is a fundamental yet challenging digital forensic task. While some deep learning-based forensic methods have achieved impressive results, they directly learn pixel-to-label mappings without fully exploiting the relationship between pixels in the feature space. To address such deficiency, we propose a Multi-view Pixel-wise Contrastive algorithm (MPC) for image forgery localization. Specifically, we first pre-train the backbone network with the supervised contrastive loss to model pixel relationships from the perspectives of within-image, cross-scale and cross-modality. That is aimed at increasing intra-class compactness and inter-class separability. Then the localization head is fine-tuned using the cross-entropy loss, resulting in a better pixel localizer. The MPC is trained on three different scale training datasets to make a comprehensive and fair comparison with existing image forgery localization algorithms. Extensive experiments on the small, medium and large scale training datasets show that the proposed MPC achieves higher generalization performance and robustness against post-processing than the state-of-the-arts. Code will be available at https://github.com/multimediaFor/MPC.
Trusted Video Inpainting Localization via Deep Attentive Noise Learning
Jun 19, 2024



Digital video inpainting techniques have been substantially improved with deep learning in recent years. Although inpainting is originally designed to repair damaged areas, it can also be used as malicious manipulation to remove important objects for creating false scenes and facts. As such it is significant to identify inpainted regions blindly. In this paper, we present a Trusted Video Inpainting Localization network (TruVIL) with excellent robustness and generalization ability. Observing that high-frequency noise can effectively unveil the inpainted regions, we design deep attentive noise learning in multiple stages to capture the inpainting traces. Firstly, a multi-scale noise extraction module based on 3D High Pass (HP3D) layers is used to create the noise modality from input RGB frames. Then the correlation between such two complementary modalities are explored by a cross-modality attentive fusion module to facilitate mutual feature learning. Lastly, spatial details are selectively enhanced by an attentive noise decoding module to boost the localization performance of the network. To prepare enough training samples, we also build a frame-level video object segmentation dataset of 2500 videos with pixel-level annotation for all frames. Extensive experimental results validate the superiority of TruVIL compared with the state-of-the-arts. In particular, both quantitative and qualitative evaluations on various inpainted videos verify the remarkable robustness and generalization ability of our proposed TruVIL. Code and dataset will be available at https://github.com/multimediaFor/TruVIL.
Transferable Adversarial Attack on Image Tampering Localization
Sep 19, 2023It is significant to evaluate the security of existing digital image tampering localization algorithms in real-world applications. In this paper, we propose an adversarial attack scheme to reveal the reliability of such tampering localizers, which would be fooled and fail to predict altered regions correctly. Specifically, the adversarial examples based on optimization and gradient are implemented for white/black-box attacks. Correspondingly, the adversarial example is optimized via reverse gradient propagation, and the perturbation is added adaptively in the direction of gradient rising. The black-box attack is achieved by relying on the transferability of such adversarial examples to different localizers. Extensive evaluations verify that the proposed attack sharply reduces the localization accuracy while preserving high visual quality of the attacked images.
Spatio-temporal Co-attention Fusion Network for Video Splicing Localization
Sep 18, 2023Digital video splicing has become easy and ubiquitous. Malicious users copy some regions of a video and paste them to another video for creating realistic forgeries. It is significant to blindly detect such forgery regions in videos. In this paper, a spatio-temporal co-attention fusion network (SCFNet) is proposed for video splicing localization. Specifically, a three-stream network is used as an encoder to capture manipulation traces across multiple frames. The deep interaction and fusion of spatio-temporal forensic features are achieved by the novel parallel and cross co-attention fusion modules. A lightweight multilayer perceptron (MLP) decoder is adopted to yield a pixel-level tampering localization map. A new large-scale video splicing dataset is created for training the SCFNet. Extensive tests on benchmark datasets show that the localization and generalization performances of our SCFNet outperform the state-of-the-art. Code and datasets will be available at https://github.com/multimediaFor/SCFNet.
Black-Box Attack against GAN-Generated Image Detector with Contrastive Perturbation
Nov 07, 2022



Visually realistic GAN-generated facial images raise obvious concerns on potential misuse. Many effective forensic algorithms have been developed to detect such synthetic images in recent years. It is significant to assess the vulnerability of such forensic detectors against adversarial attacks. In this paper, we propose a new black-box attack method against GAN-generated image detectors. A novel contrastive learning strategy is adopted to train the encoder-decoder network based anti-forensic model under a contrastive loss function. GAN images and their simulated real counterparts are constructed as positive and negative samples, respectively. Leveraging on the trained attack model, imperceptible contrastive perturbation could be applied to input synthetic images for removing GAN fingerprint to some extent. As such, existing GAN-generated image detectors are expected to be deceived. Extensive experimental results verify that the proposed attack effectively reduces the accuracy of three state-of-the-art detectors on six popular GANs. High visual quality of the attacked images is also achieved. The source code will be available at https://github.com/ZXMMD/BAttGAND.