 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFIRE: A Failure-Adaptive Reinforcement Learning Framework for Edge Computing Migrations
Paper and Code
Sep 28, 2022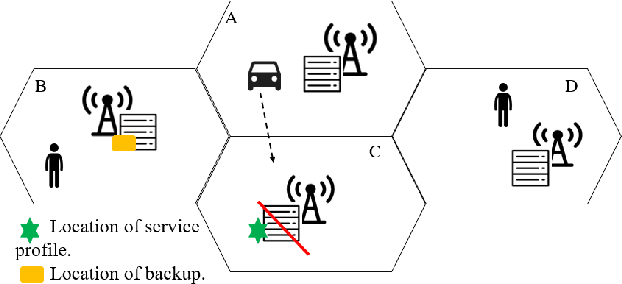
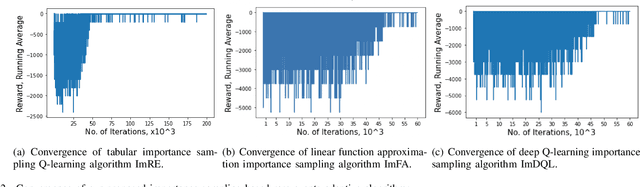
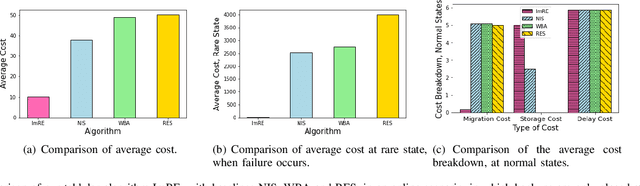
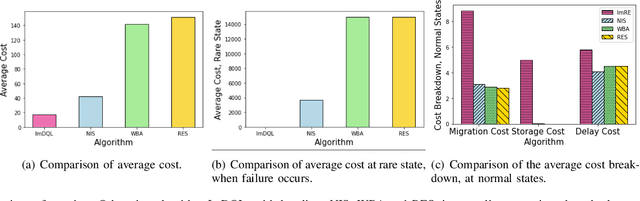
In edge computing, users' service profiles must be migrated in response to user mobility. Reinforcement learning (RL) frameworks have been proposed to do so. Nevertheless, these frameworks do not consider occasional server failures, which although rare, can prevent the smooth and safe functioning of edge computing users' latency sensitive applications such as autonomous driving and real-time obstacle detection, because users' computing jobs can no longer be completed. As these failures occur at a low probability, it is difficult for RL algorithms, which are inherently data-driven, to learn an optimal service migration solution for both the typical and rare event scenarios. Therefore, we introduce a rare events adaptive resilience framework FIRE, which integrates importance sampling into reinforcement learning to place backup services. We sample rare events at a rate proportional to their contribution to the value function, to learn an optimal policy. Our framework balances service migration trade-offs between delay and migration costs, with the costs of failure and the costs of backup placement and migration. We propose an importance sampling based Q-learning algorithm, and prove its boundedness and convergence to optimality. Following which we propose novel eligibility traces, linear function approximation and deep Q-learning versions of our algorithm to ensure it scales to real-world scenarios. We extend our framework to cater to users with different risk tolerances towards failure. Finally, we use trace driven experiments to show that our algorithm gives cost reductions in the event of failures.