 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Abuse and Detection of Polyglot Files
Jul 01, 2024



A polyglot is a file that is valid in two or more formats. Polyglot files pose a problem for malware detection systems that route files to format-specific detectors/signatures, as well as file upload and sanitization tools. In this work we found that existing file-format and embedded-file detection tools, even those developed specifically for polyglot files, fail to reliably detect polyglot files used in the wild, leaving organizations vulnerable to attack. To address this issue, we studied the use of polyglot files by malicious actors in the wild, finding $30$ polyglot samples and $15$ attack chains that leveraged polyglot files. In this report, we highlight two well-known APTs whose cyber attack chains relied on polyglot files to bypass detection mechanisms. Using knowledge from our survey of polyglot usage in the wild -- the first of its kind -- we created a novel data set based on adversary techniques. We then trained a machine learning detection solution, PolyConv, using this data set. PolyConv achieves a precision-recall area-under-curve score of $0.999$ with an F1 score of $99.20$% for polyglot detection and $99.47$% for file-format identification, significantly outperforming all other tools tested. We developed a content disarmament and reconstruction tool, ImSan, that successfully sanitized $100$% of the tested image-based polyglots, which were the most common type found via the survey. Our work provides concrete tools and suggestions to enable defenders to better defend themselves against polyglot files, as well as directions for future work to create more robust file specifications and methods of disarmament.
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
Apr 23, 2024



We introduce phi-3-mini, a 3.8 billion parameter language model trained on 3.3 trillion tokens, whose overall performance, as measured by both academic benchmarks and internal testing, rivals that of models such as Mixtral 8x7B and GPT-3.5 (e.g., phi-3-mini achieves 69% on MMLU and 8.38 on MT-bench), despite being small enough to be deployed on a phone. The innovation lies entirely in our dataset for training, a scaled-up version of the one used for phi-2, composed of heavily filtered web data and synthetic data. The model is also further aligned for robustness, safety, and chat format. We also provide some initial parameter-scaling results with a 7B and 14B models trained for 4.8T tokens, called phi-3-small and phi-3-medium, both significantly more capable than phi-3-mini (e.g., respectively 75% and 78% on MMLU, and 8.7 and 8.9 on MT-bench).
Beyond Surrogate Modeling: Learning the Local Volatility Via Shape Constraints
Dec 20, 2022We explore the abilities of two machine learning approaches for no-arbitrage interpolation of European vanilla option prices, which jointly yield the corresponding local volatility surface: a finite dimensional Gaussian process (GP) regression approach under no-arbitrage constraints based on prices, and a neural net (NN) approach with penalization of arbitrages based on implied volatilities. We demonstrate the performance of these approaches relative to the SSVI industry standard. The GP approach is proven arbitrage-free, whereas arbitrages are only penalized under the SSVI and NN approaches. The GP approach obtains the best out-of-sample calibration error and provides uncertainty quantification.The NN approach yields a smoother local volatility and a better backtesting performance, as its training criterion incorporates a local volatility regularization term.
A Unified Bayesian Framework for Pricing Catastrophe Bond Derivatives
May 09, 2022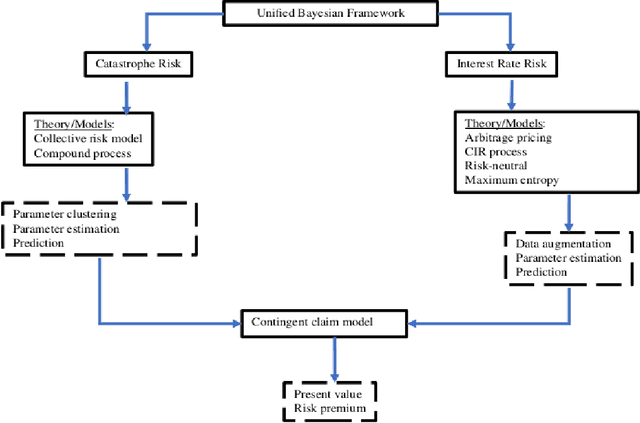
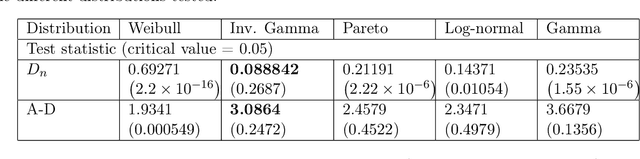

Catastrophe (CAT) bond markets are incomplete and hence carry uncertainty in instrument pricing. As such various pricing approaches have been proposed, but none treat the uncertainty in catastrophe occurrences and interest rates in a sufficiently flexible and statistically reliable way within a unifying asset pricing framework. Consequently, little is known empirically about the expected risk-premia of CAT bonds. The primary contribution of this paper is to present a unified Bayesian CAT bond pricing framework based on uncertainty quantification of catastrophes and interest rates. Our framework allows for complex beliefs about catastrophe risks to capture the distinct and common patterns in catastrophe occurrences, and when combined with stochastic interest rates, yields a unified asset pricing approach with informative expected risk premia. Specifically, using a modified collective risk model -- Dirichlet Prior-Hierarchical Bayesian Collective Risk Model (DP-HBCRM) framework -- we model catastrophe risk via a model-based clustering approach. Interest rate risk is modeled as a CIR process under the Bayesian approach. As a consequence of casting CAT pricing models into our framework, we evaluate the price and expected risk premia of various CAT bond contracts corresponding to clustering of catastrophe risk profiles. Numerical experiments show how these clusters reveal how CAT bond prices and expected risk premia relate to claim frequency and loss severity.
MS-nowcasting: Operational Precipitation Nowcasting with Convolutional LSTMs at Microsoft Weather
Nov 18, 2021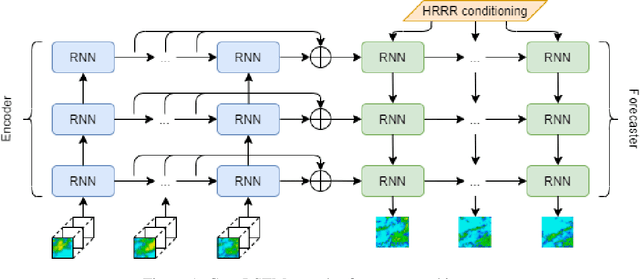
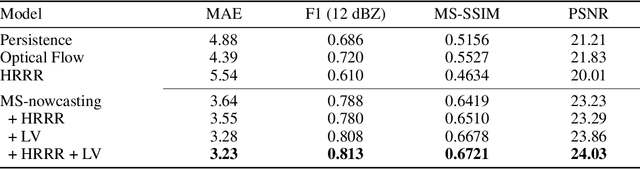
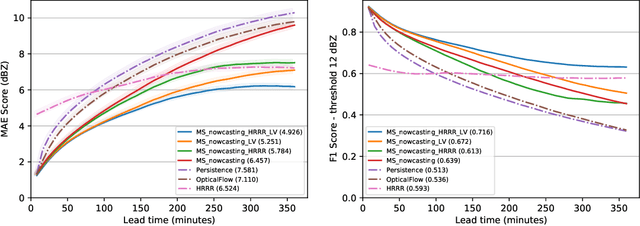
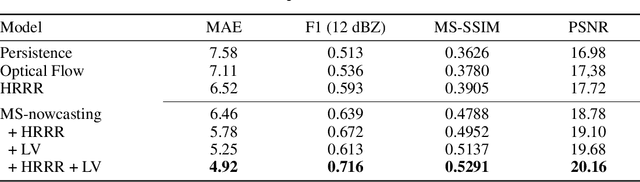
We present the encoder-forecaster convolutional long short-term memory (LSTM) deep-learning model that powers Microsoft Weather's operational precipitation nowcasting product. This model takes as input a sequence of weather radar mosaics and deterministically predicts future radar reflectivity at lead times up to 6 hours. By stacking a large input receptive field along the feature dimension and conditioning the model's forecaster with predictions from the physics-based High Resolution Rapid Refresh (HRRR) model, we are able to outperform optical flow and HRRR baselines by 20-25% on multiple metrics averaged over all lead times.
G-Learner and GIRL: Goal Based Wealth Management with Reinforcement Learning
Feb 25, 2020
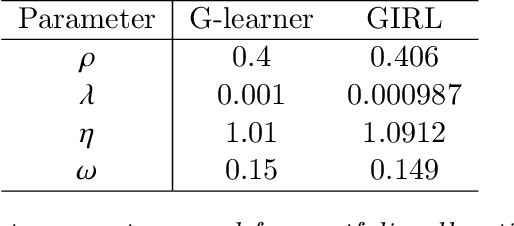
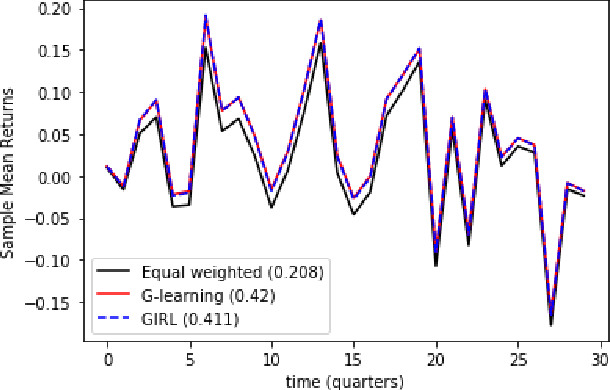

We present a reinforcement learning approach to goal based wealth management problems such as optimization of retirement plans or target dated funds. In such problems, an investor seeks to achieve a financial goal by making periodic investments in the portfolio while being employed, and periodically draws from the account when in retirement, in addition to the ability to re-balance the portfolio by selling and buying different assets (e.g. stocks). Instead of relying on a utility of consumption, we present G-Learner: a reinforcement learning algorithm that operates with explicitly defined one-step rewards, does not assume a data generation process, and is suitable for noisy data. Our approach is based on G-learning - a probabilistic extension of the Q-learning method of reinforcement learning. In this paper, we demonstrate how G-learning, when applied to a quadratic reward and Gaussian reference policy, gives an entropy-regulated Linear Quadratic Regulator (LQR). This critical insight provides a novel and computationally tractable tool for wealth management tasks which scales to high dimensional portfolios. In addition to the solution of the direct problem of G-learning, we also present a new algorithm, GIRL, that extends our goal-based G-learning approach to the setting of Inverse Reinforcement Learning (IRL) where rewards collected by the agent are not observed, and should instead be inferred. We demonstrate that GIRL can successfully learn the reward parameters of a G-Learner agent and thus imitate its behavior. Finally, we discuss potential applications of the G-Learner and GIRL algorithms for wealth management and robo-advising.
OSTSC: Over Sampling for Time Series Classification in R
Nov 27, 2017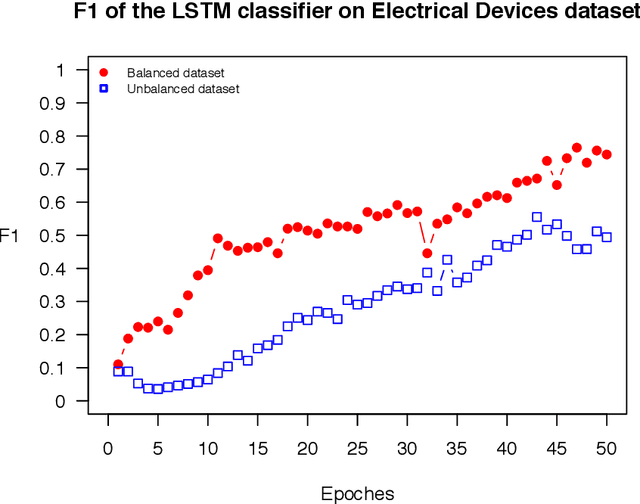
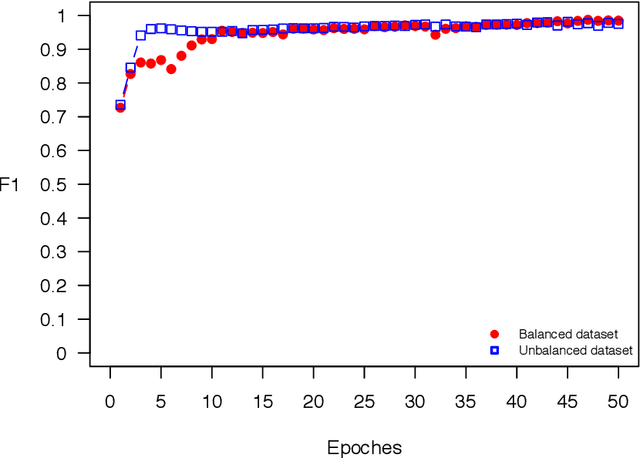
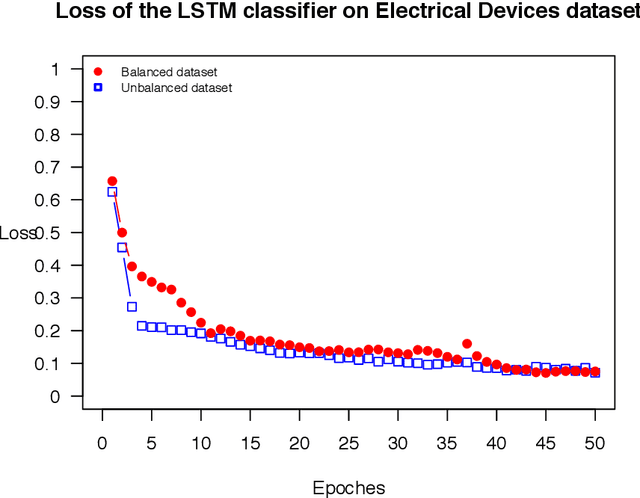

The OSTSC package is a powerful oversampling approach for classifying univariant, but multinomial time series data in R. This article provides a brief overview of the oversampling methodology implemented by the package. A tutorial of the OSTSC package is provided. We begin by providing three test cases for the user to quickly validate the functionality in the package. To demonstrate the performance impact of OSTSC, we then provide two medium size imbalanced time series datasets. Each example applies a TensorFlow implementation of a Long Short-Term Memory (LSTM) classifier - a type of a Recurrent Neural Network (RNN) classifier - to imbalanced time series. The classifier performance is compared with and without oversampling. Finally, larger versions of these two datasets are evaluated to demonstrate the scalability of the package. The examples demonstrate that the OSTSC package improves the performance of RNN classifiers applied to highly imbalanced time series data. In particular, OSTSC is observed to increase the AUC of LSTM from 0.543 to 0.784 on a high frequency trading dataset consisting of 30,000 time series observations.
Classification-based Financial Markets Prediction using Deep Neural Networks
Jun 13, 2017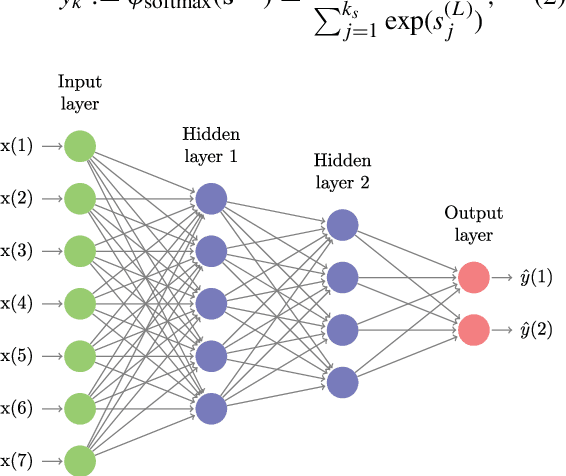

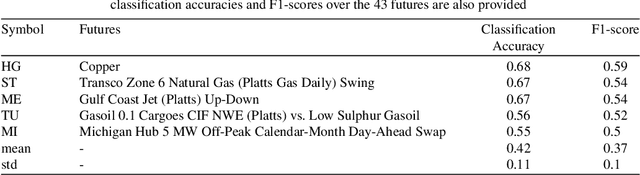
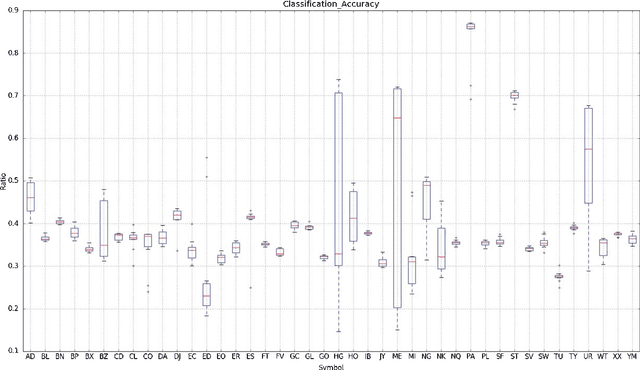
Deep neural networks (DNNs) are powerful types of artificial neural networks (ANNs) that use several hidden layers. They have recently gained considerable attention in the speech transcription and image recognition community (Krizhevsky et al., 2012) for their superior predictive properties including robustness to overfitting. However their application to algorithmic trading has not been previously researched, partly because of their computational complexity. This paper describes the application of DNNs to predicting financial market movement directions. In particular we describe the configuration and training approach and then demonstrate their application to backtesting a simple trading strategy over 43 different Commodity and FX future mid-prices at 5-minute intervals. All results in this paper are generated using a C++ implementation on the Intel Xeon Phi co-processor which is 11.4x faster than the serial version and a Python strategy backtesting environment both of which are available as open source code written by the authors.