 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Abuse and Detection of Polyglot Files
Jul 01, 2024



A polyglot is a file that is valid in two or more formats. Polyglot files pose a problem for malware detection systems that route files to format-specific detectors/signatures, as well as file upload and sanitization tools. In this work we found that existing file-format and embedded-file detection tools, even those developed specifically for polyglot files, fail to reliably detect polyglot files used in the wild, leaving organizations vulnerable to attack. To address this issue, we studied the use of polyglot files by malicious actors in the wild, finding $30$ polyglot samples and $15$ attack chains that leveraged polyglot files. In this report, we highlight two well-known APTs whose cyber attack chains relied on polyglot files to bypass detection mechanisms. Using knowledge from our survey of polyglot usage in the wild -- the first of its kind -- we created a novel data set based on adversary techniques. We then trained a machine learning detection solution, PolyConv, using this data set. PolyConv achieves a precision-recall area-under-curve score of $0.999$ with an F1 score of $99.20$% for polyglot detection and $99.47$% for file-format identification, significantly outperforming all other tools tested. We developed a content disarmament and reconstruction tool, ImSan, that successfully sanitized $100$% of the tested image-based polyglots, which were the most common type found via the survey. Our work provides concrete tools and suggestions to enable defenders to better defend themselves against polyglot files, as well as directions for future work to create more robust file specifications and methods of disarmament.
Toward the Detection of Polyglot Files
Apr 13, 2022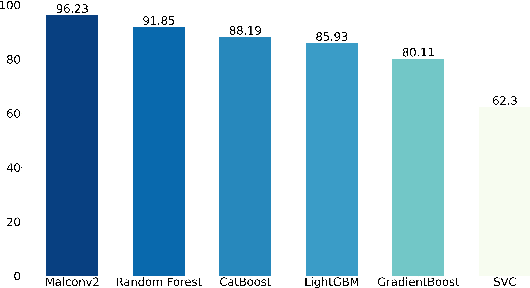
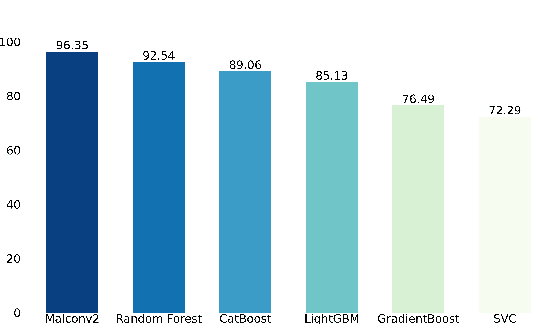
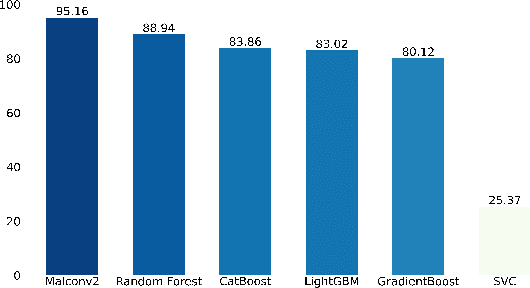
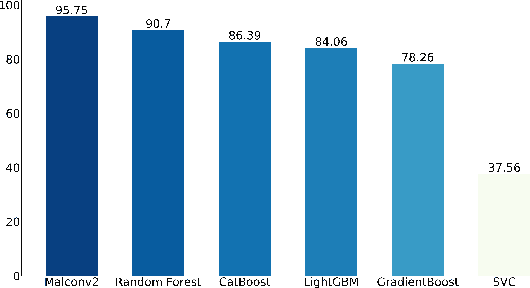
Standardized file formats play a key role in the development and use of computer software. However, it is possible to abuse standardized file formats by creating a file that is valid in multiple file formats. The resulting polyglot (many languages) file can confound file format identification, allowing elements of the file to evade analysis.This is especially problematic for malware detection systems that rely on file format identification for feature extraction. File format identification processes that depend on file signatures can be easily evaded thanks to flexibility in the format specifications of certain file formats. Although work has been done to identify file formats using more comprehensive methods than file signatures, accurate identification of polyglot files remains an open problem. Since malware detection systems routinely perform file format-specific feature extraction, polyglot files need to be filtered out prior to ingestion by these systems. Otherwise, malicious content could pass through undetected. To address the problem of polyglot detection we assembled a data set using the mitra tool. We then evaluated the performance of the most commonly used file identification tool, file. Finally, we demonstrated the accuracy, precision, recall and F1 score of a range of machine and deep learning models. Malconv2 and Catboost demonstrated the highest recall on our data set with 95.16% and 95.45%, respectively. These models can be incorporated into a malware detector's file processing pipeline to filter out potentially malicious polyglots before file format-dependent feature extraction takes place.