 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttacks and Defenses Against LLM Fingerprinting
Aug 12, 2025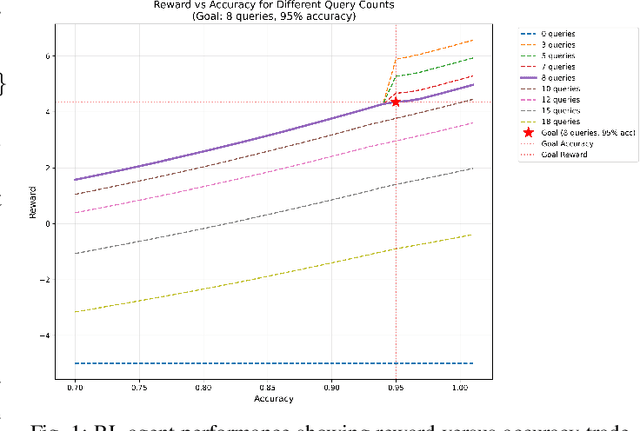
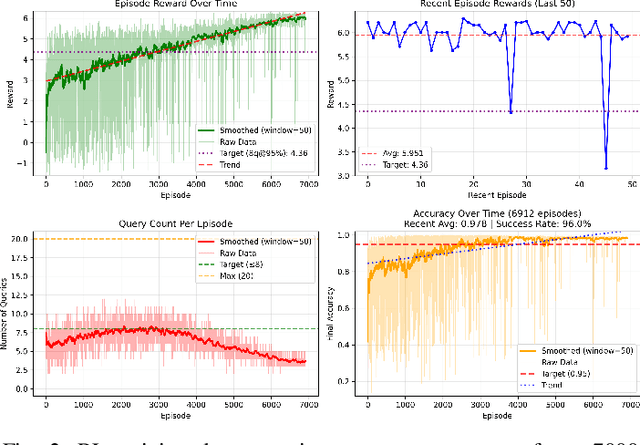
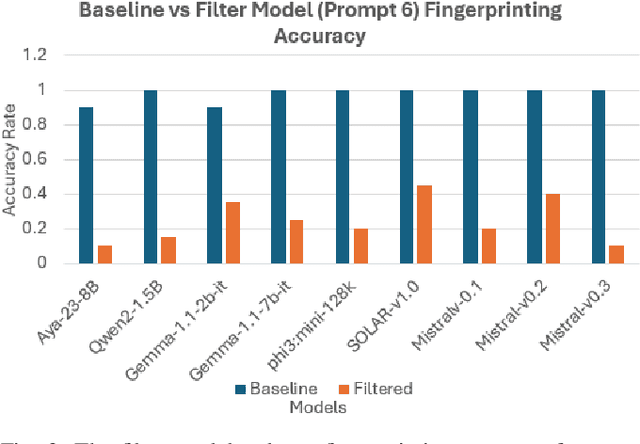

As large language models are increasingly deployed in sensitive environments, fingerprinting attacks pose significant privacy and security risks. We present a study of LLM fingerprinting from both offensive and defensive perspectives. Our attack methodology uses reinforcement learning to automatically optimize query selection, achieving better fingerprinting accuracy with only 3 queries compared to randomly selecting 3 queries from the same pool. Our defensive approach employs semantic-preserving output filtering through a secondary LLM to obfuscate model identity while maintaining semantic integrity. The defensive method reduces fingerprinting accuracy across tested models while preserving output quality. These contributions show the potential to improve fingerprinting tools capabilities while providing practical mitigation strategies against fingerprinting attacks.
On the Abuse and Detection of Polyglot Files
Jul 01, 2024



A polyglot is a file that is valid in two or more formats. Polyglot files pose a problem for malware detection systems that route files to format-specific detectors/signatures, as well as file upload and sanitization tools. In this work we found that existing file-format and embedded-file detection tools, even those developed specifically for polyglot files, fail to reliably detect polyglot files used in the wild, leaving organizations vulnerable to attack. To address this issue, we studied the use of polyglot files by malicious actors in the wild, finding $30$ polyglot samples and $15$ attack chains that leveraged polyglot files. In this report, we highlight two well-known APTs whose cyber attack chains relied on polyglot files to bypass detection mechanisms. Using knowledge from our survey of polyglot usage in the wild -- the first of its kind -- we created a novel data set based on adversary techniques. We then trained a machine learning detection solution, PolyConv, using this data set. PolyConv achieves a precision-recall area-under-curve score of $0.999$ with an F1 score of $99.20$% for polyglot detection and $99.47$% for file-format identification, significantly outperforming all other tools tested. We developed a content disarmament and reconstruction tool, ImSan, that successfully sanitized $100$% of the tested image-based polyglots, which were the most common type found via the survey. Our work provides concrete tools and suggestions to enable defenders to better defend themselves against polyglot files, as well as directions for future work to create more robust file specifications and methods of disarmament.
The Path To Autonomous Cyber Defense
Apr 12, 2024


Defenders are overwhelmed by the number and scale of attacks against their networks.This problem will only be exacerbated as attackers leverage artificial intelligence to automate their workflows. We propose a path to autonomous cyber agents able to augment defenders by automating critical steps in the cyber defense life cycle.
Toward the Detection of Polyglot Files
Apr 13, 2022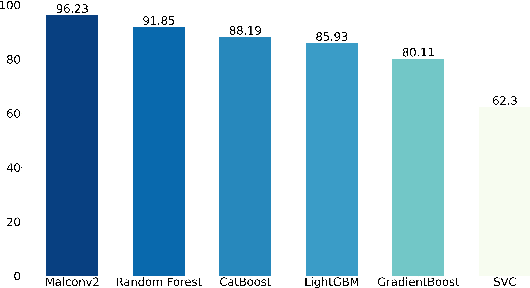
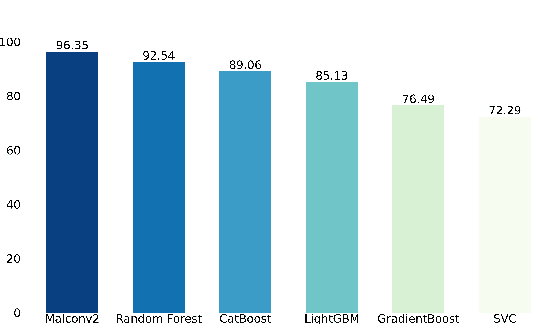
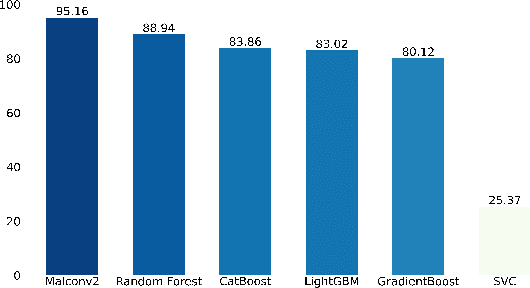
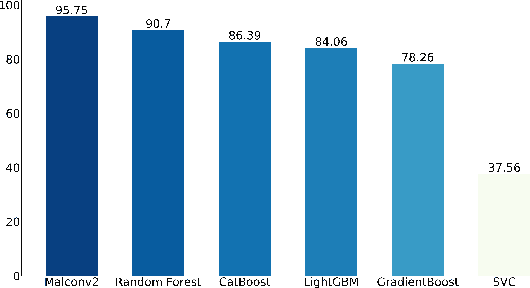
Standardized file formats play a key role in the development and use of computer software. However, it is possible to abuse standardized file formats by creating a file that is valid in multiple file formats. The resulting polyglot (many languages) file can confound file format identification, allowing elements of the file to evade analysis.This is especially problematic for malware detection systems that rely on file format identification for feature extraction. File format identification processes that depend on file signatures can be easily evaded thanks to flexibility in the format specifications of certain file formats. Although work has been done to identify file formats using more comprehensive methods than file signatures, accurate identification of polyglot files remains an open problem. Since malware detection systems routinely perform file format-specific feature extraction, polyglot files need to be filtered out prior to ingestion by these systems. Otherwise, malicious content could pass through undetected. To address the problem of polyglot detection we assembled a data set using the mitra tool. We then evaluated the performance of the most commonly used file identification tool, file. Finally, we demonstrated the accuracy, precision, recall and F1 score of a range of machine and deep learning models. Malconv2 and Catboost demonstrated the highest recall on our data set with 95.16% and 95.45%, respectively. These models can be incorporated into a malware detector's file processing pipeline to filter out potentially malicious polyglots before file format-dependent feature extraction takes place.
Beyond the Hype: A Real-World Evaluation of the Impact and Cost of Machine Learning--Based Malware Detection
Dec 16, 2020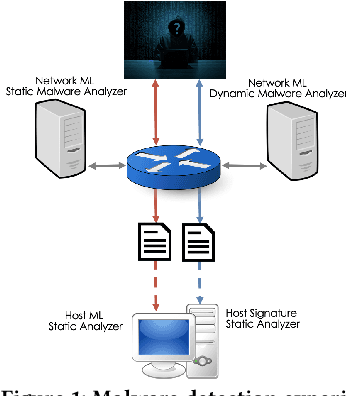
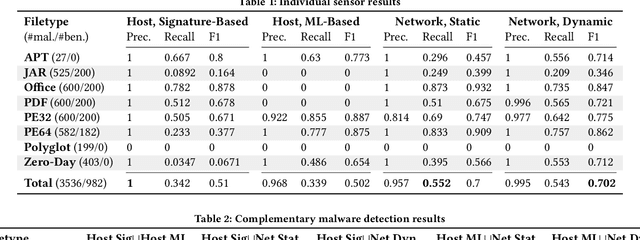
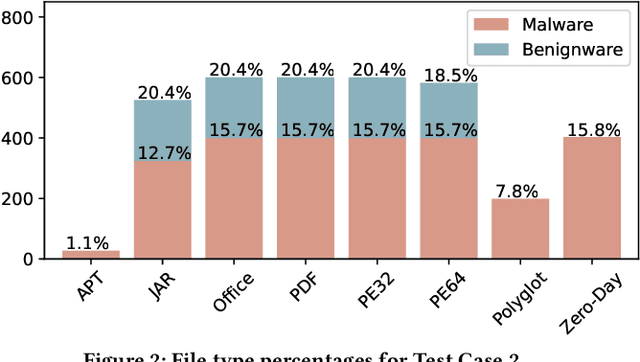
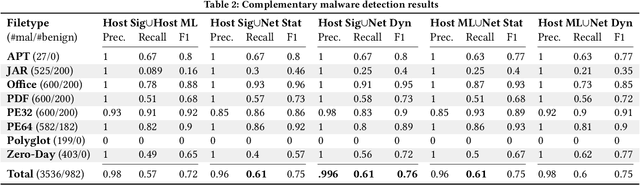
There is a lack of scientific testing of commercially available malware detectors, especially those that boast accurate classification of never-before-seen (zero-day) files using machine learning (ML). The result is that the efficacy and trade-offs among the different available approaches are opaque. In this paper, we address this gap in the scientific literature with an evaluation of commercially available malware detection tools. We tested each tool against 3,536 total files (2,554 72% malicious, 982 28% benign) including over 400 zero-day malware, and tested with a variety of file types and protocols for delivery. Specifically, we investigate three questions: Do ML-based malware detectors provide better detection than signature-based detectors? Is it worth purchasing a network-level malware detector to complement host-based detection? What is the trade-off in detection time and detection accuracy among commercially available tools using static and dynamic analysis? We present statistical results on detection time and accuracy, consider complementary analysis (using multiple tools together), and provide a novel application of a recent cost-benefit evaluation procedure by Iannaconne \& Bridges that incorporates all the above metrics into a single quantifiable cost to help security operation centers select the right tools for their use case. Our results show that while ML-based tools are more effective at detecting zero-days and malicious executables, they work best when used in combination with a signature-based solution. In addition, network-based tools had poor detection rates on protocols other than the HTTP or SMTP, making them a poor choice if used on their own. Surprisingly, we also found that all the tools tested had lower than expected detection rates, completely missing 37% of malicious files tested and failing to detect any polyglot files.
An Assessment of the Usability of Machine Learning Based Tools for the Security Operations Center
Dec 16, 2020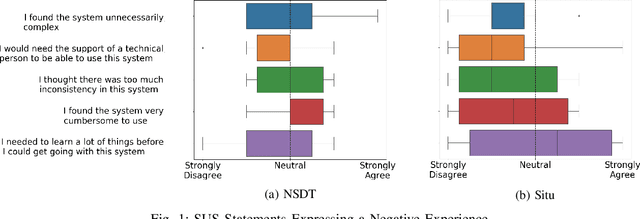



Gartner, a large research and advisory company, anticipates that by 2024 80% of security operation centers (SOCs) will use machine learning (ML) based solutions to enhance their operations. In light of such widespread adoption, it is vital for the research community to identify and address usability concerns. This work presents the results of the first in situ usability assessment of ML-based tools. With the support of the US Navy, we leveraged the national cyber range, a large, air-gapped cyber testbed equipped with state-of-the-art network and user emulation capabilities, to study six US Naval SOC analysts' usage of two tools. Our analysis identified several serious usability issues, including multiple violations of established usability heuristics form user interface design. We also discovered that analysts lacked a clear mental model of how these tools generate scores, resulting in mistrust and/or misuse of the tools themselves. Surprisingly, we found no correlation between analysts' level of education or years of experience and their performance with either tool, suggesting that other factors such as prior background knowledge or personality play a significant role in ML-based tool usage. Our findings demonstrate that ML-based security tool vendors must put a renewed focus on working with analysts, both experienced and inexperienced, to ensure that their systems are usable and useful in real-world security operations settings.