 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting CAN Masquerade Attacks with Signal Clustering Similarity
Jan 07, 2022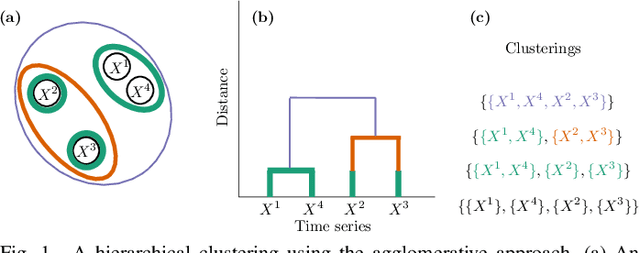
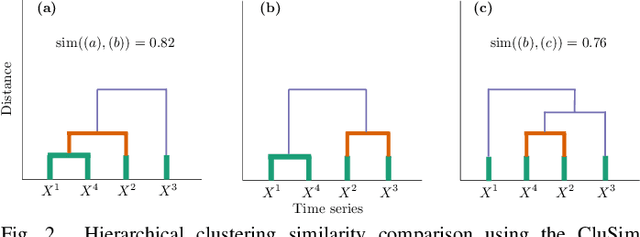
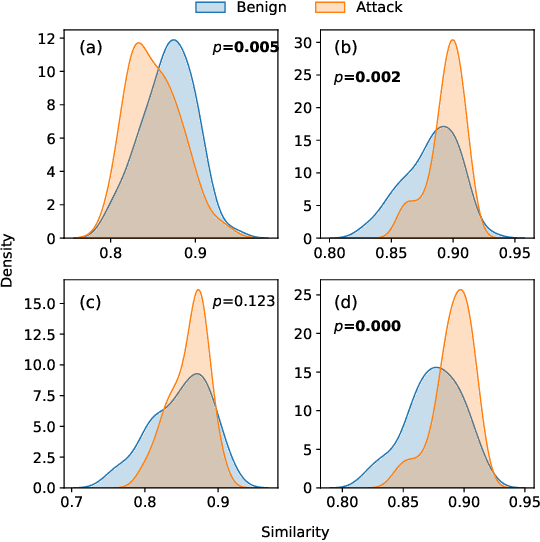
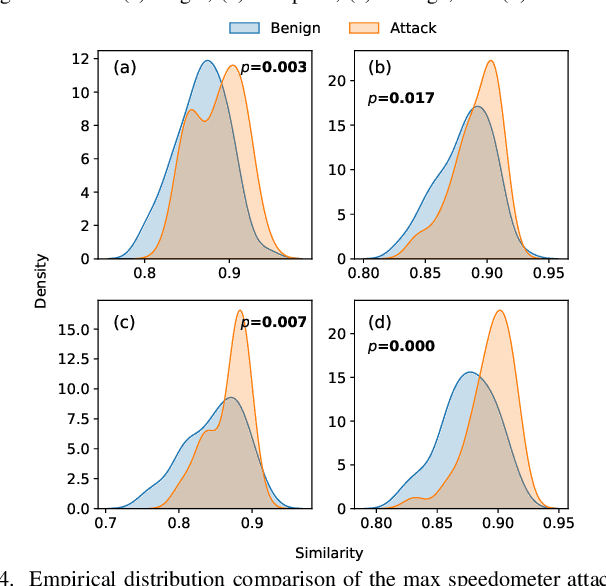
Vehicular Controller Area Networks (CANs) are susceptible to cyber attacks of different levels of sophistication. Fabrication attacks are the easiest to administer -- an adversary simply sends (extra) frames on a CAN -- but also the easiest to detect because they disrupt frame frequency. To overcome time-based detection methods, adversaries must administer masquerade attacks by sending frames in lieu of (and therefore at the expected time of) benign frames but with malicious payloads. Research efforts have proven that CAN attacks, and masquerade attacks in particular, can affect vehicle functionality. Examples include causing unintended acceleration, deactivation of vehicle's brakes, as well as steering the vehicle. We hypothesize that masquerade attacks modify the nuanced correlations of CAN signal time series and how they cluster together. Therefore, changes in cluster assignments should indicate anomalous behavior. We confirm this hypothesis by leveraging our previously developed capability for reverse engineering CAN signals (i.e., CAN-D [Controller Area Network Decoder]) and focus on advancing the state of the art for detecting masquerade attacks by analyzing time series extracted from raw CAN frames. Specifically, we demonstrate that masquerade attacks can be detected by computing time series clustering similarity using hierarchical clustering on the vehicle's CAN signals (time series) and comparing the clustering similarity across CAN captures with and without attacks. We test our approach in a previously collected CAN dataset with masquerade attacks (i.e., the ROAD dataset) and develop a forensic tool as a proof of concept to demonstrate the potential of the proposed approach for detecting CAN masquerade attacks.
Time-Based CAN Intrusion Detection Benchmark
Jan 14, 2021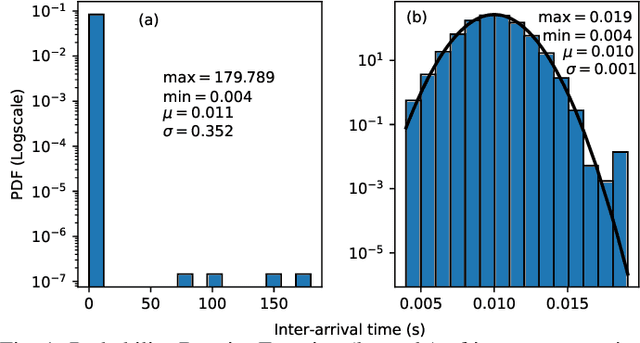
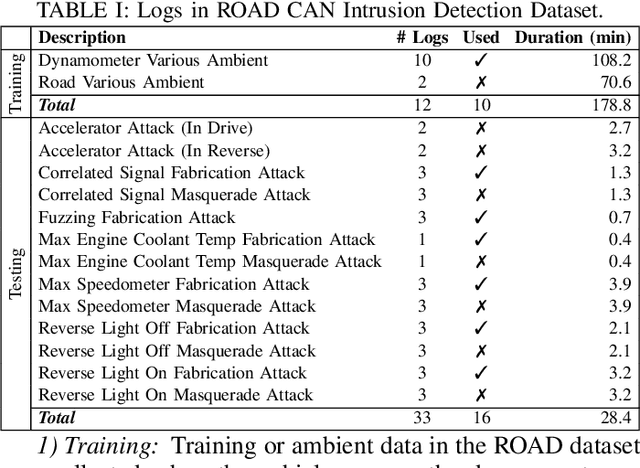
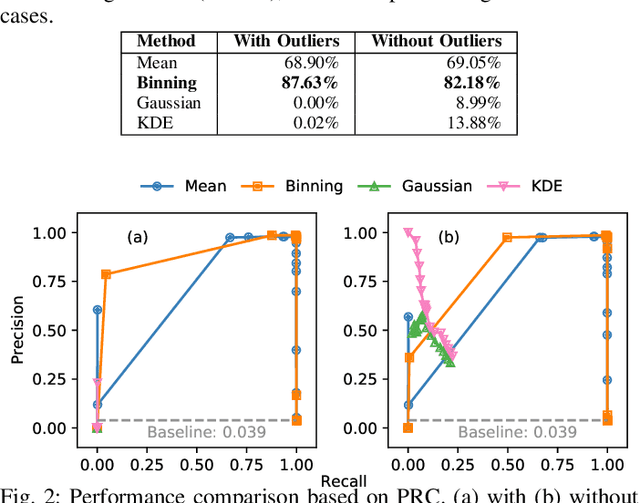
Modern vehicles are complex cyber-physical systems made of hundreds of electronic control units (ECUs) that communicate over controller area networks (CANs). This inherited complexity has expanded the CAN attack surface which is vulnerable to message injection attacks. These injections change the overall timing characteristics of messages on the bus, and thus, to detect these malicious messages, time-based intrusion detection systems (IDSs) have been proposed. However, time-based IDSs are usually trained and tested on low-fidelity datasets with unrealistic, labeled attacks. This makes difficult the task of evaluating, comparing, and validating IDSs. Here we detail and benchmark four time-based IDSs against the newly published ROAD dataset, the first open CAN IDS dataset with real (non-simulated) stealthy attacks with physically verified effects. We found that methods that perform hypothesis testing by explicitly estimating message timing distributions have lower performance than methods that seek anomalies in a distribution-related statistic. In particular, these "distribution-agnostic" based methods outperform "distribution-based" methods by at least 55% in area under the precision-recall curve (AUC-PR). Our results expand the body of knowledge of CAN time-based IDSs by providing details of these methods and reporting their results when tested on datasets with real advanced attacks. Finally, we develop an after-market plug-in detector using lightweight hardware, which can be used to deploy the best performing IDS method on nearly any vehicle.
ROAD: The Real ORNL Automotive Dynamometer Controller Area Network Intrusion Detection Dataset (with a comprehensive CAN IDS dataset survey & guide)
Dec 29, 2020

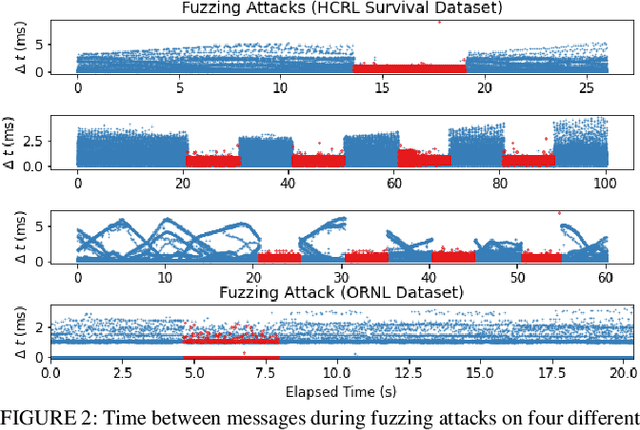

The Controller Area Network (CAN) protocol is ubiquitous in modern vehicles, but the protocol lacks many important security properties, such as message authentication. To address these insecurities, a rapidly growing field of research has emerged that seeks to detect tampering, anomalies, or attacks on these networks; this field has developed a wide variety of novel approaches and algorithms to address these problems. One major impediment to the progression of this CAN anomaly detection and intrusion detection system (IDS) research area is the lack of high-fidelity datasets with realistic labeled attacks, without which it is difficult to evaluate, compare, and validate these proposed approaches. In this work we present the first comprehensive survey of publicly available CAN intrusion datasets. Based on a thorough analysis of the data and documentation, for each dataset we provide a detailed description and enumerate the drawbacks, benefits, and suggested use cases. Our analysis is aimed at guiding researchers in finding appropriate datasets for testing a CAN IDS. We present the Real ORNL Automotive Dynamometer (ROAD) CAN Intrusion Dataset, providing the first dataset with real, advanced attacks to the existing collection of open datasets.
Beyond the Hype: A Real-World Evaluation of the Impact and Cost of Machine Learning--Based Malware Detection
Dec 16, 2020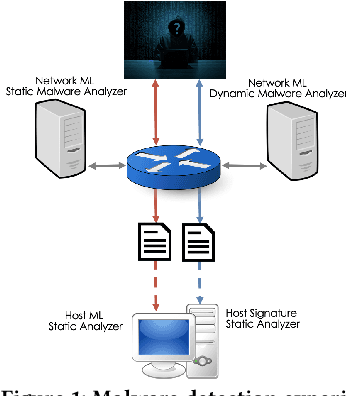
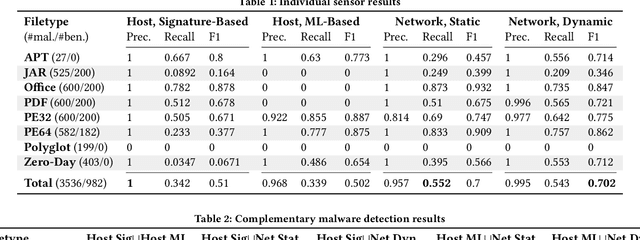
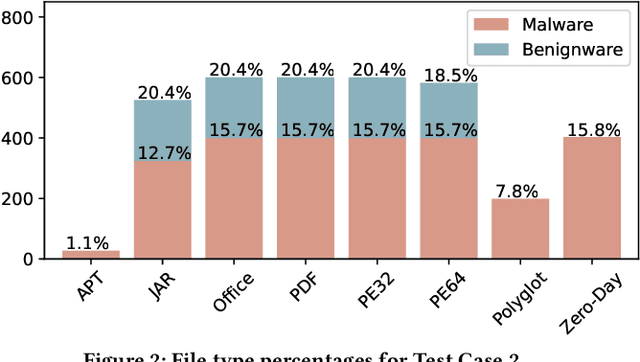
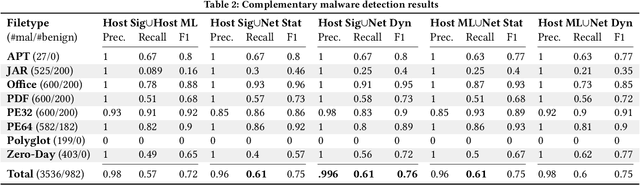
There is a lack of scientific testing of commercially available malware detectors, especially those that boast accurate classification of never-before-seen (zero-day) files using machine learning (ML). The result is that the efficacy and trade-offs among the different available approaches are opaque. In this paper, we address this gap in the scientific literature with an evaluation of commercially available malware detection tools. We tested each tool against 3,536 total files (2,554 72% malicious, 982 28% benign) including over 400 zero-day malware, and tested with a variety of file types and protocols for delivery. Specifically, we investigate three questions: Do ML-based malware detectors provide better detection than signature-based detectors? Is it worth purchasing a network-level malware detector to complement host-based detection? What is the trade-off in detection time and detection accuracy among commercially available tools using static and dynamic analysis? We present statistical results on detection time and accuracy, consider complementary analysis (using multiple tools together), and provide a novel application of a recent cost-benefit evaluation procedure by Iannaconne \& Bridges that incorporates all the above metrics into a single quantifiable cost to help security operation centers select the right tools for their use case. Our results show that while ML-based tools are more effective at detecting zero-days and malicious executables, they work best when used in combination with a signature-based solution. In addition, network-based tools had poor detection rates on protocols other than the HTTP or SMTP, making them a poor choice if used on their own. Surprisingly, we also found that all the tools tested had lower than expected detection rates, completely missing 37% of malicious files tested and failing to detect any polyglot files.
GraphPrints: Towards a Graph Analytic Method for Network Anomaly Detection
Feb 02, 2016


This paper introduces a novel graph-analytic approach for detecting anomalies in network flow data called GraphPrints. Building on foundational network-mining techniques, our method represents time slices of traffic as a graph, then counts graphlets -- small induced subgraphs that describe local topology. By performing outlier detection on the sequence of graphlet counts, anomalous intervals of traffic are identified, and furthermore, individual IPs experiencing abnormal behavior are singled-out. Initial testing of GraphPrints is performed on real network data with an implanted anomaly. Evaluation shows false positive rates bounded by 2.84% at the time-interval level, and 0.05% at the IP-level with 100% true positive rates at both.
Automatic Labeling for Entity Extraction in Cyber Security
Jun 09, 2014
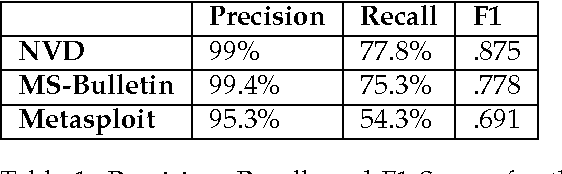

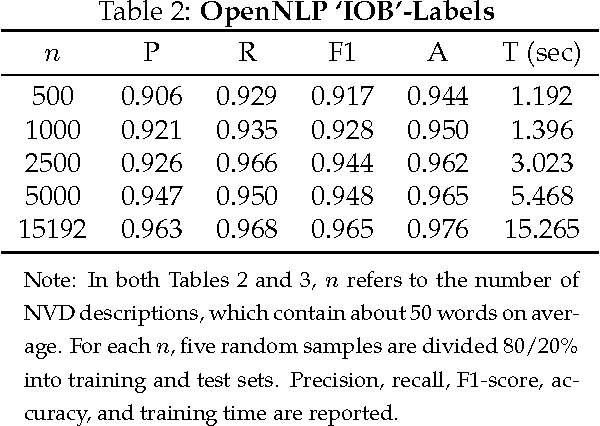
Timely analysis of cyber-security information necessitates automated information extraction from unstructured text. While state-of-the-art extraction methods produce extremely accurate results, they require ample training data, which is generally unavailable for specialized applications, such as detecting security related entities; moreover, manual annotation of corpora is very costly and often not a viable solution. In response, we develop a very precise method to automatically label text from several data sources by leveraging related, domain-specific, structured data and provide public access to a corpus annotated with cyber-security entities. Next, we implement a Maximum Entropy Model trained with the average perceptron on a portion of our corpus ($\sim$750,000 words) and achieve near perfect precision, recall, and accuracy, with training times under 17 seconds.
PACE: Pattern Accurate Computationally Efficient Bootstrapping for Timely Discovery of Cyber-Security Concepts
Oct 11, 2013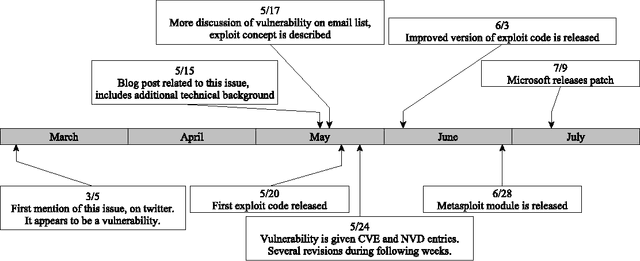
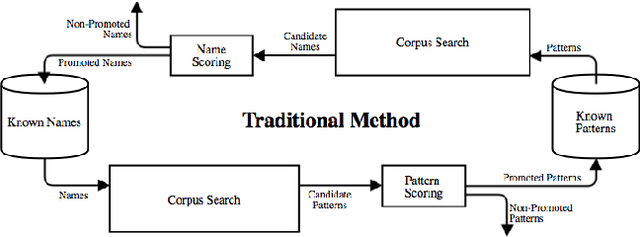
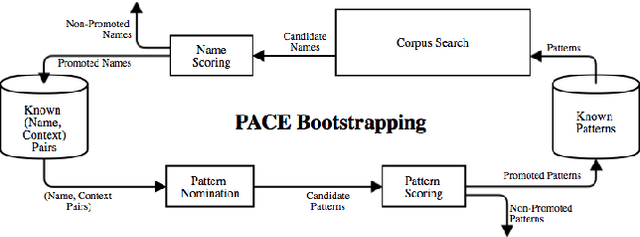

Public disclosure of important security information, such as knowledge of vulnerabilities or exploits, often occurs in blogs, tweets, mailing lists, and other online sources months before proper classification into structured databases. In order to facilitate timely discovery of such knowledge, we propose a novel semi-supervised learning algorithm, PACE, for identifying and classifying relevant entities in text sources. The main contribution of this paper is an enhancement of the traditional bootstrapping method for entity extraction by employing a time-memory trade-off that simultaneously circumvents a costly corpus search while strengthening pattern nomination, which should increase accuracy. An implementation in the cyber-security domain is discussed as well as challenges to Natural Language Processing imposed by the security domain.