 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePACE: Pattern Accurate Computationally Efficient Bootstrapping for Timely Discovery of Cyber-Security Concepts
Oct 11, 2013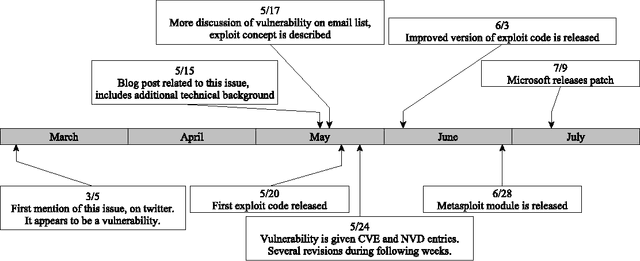
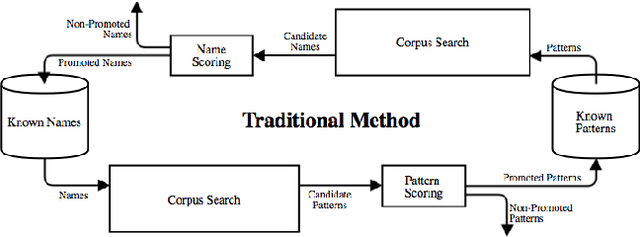
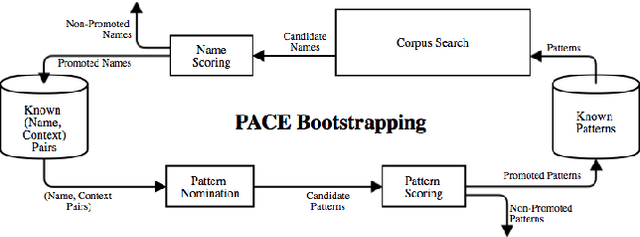

Public disclosure of important security information, such as knowledge of vulnerabilities or exploits, often occurs in blogs, tweets, mailing lists, and other online sources months before proper classification into structured databases. In order to facilitate timely discovery of such knowledge, we propose a novel semi-supervised learning algorithm, PACE, for identifying and classifying relevant entities in text sources. The main contribution of this paper is an enhancement of the traditional bootstrapping method for entity extraction by employing a time-memory trade-off that simultaneously circumvents a costly corpus search while strengthening pattern nomination, which should increase accuracy. An implementation in the cyber-security domain is discussed as well as challenges to Natural Language Processing imposed by the security domain.