 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForming IDEAS Interactive Data Exploration & Analysis System
Jun 20, 2018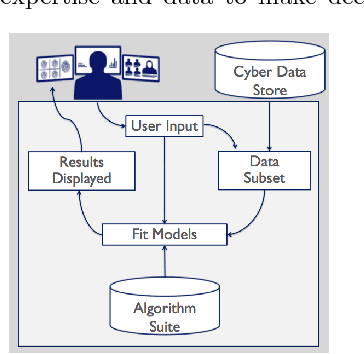

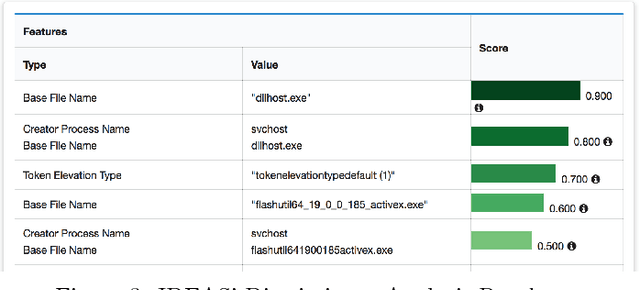

Modern cyber security operations collect an enormous amount of logging and alerting data. While analysts have the ability to query and compute simple statistics and plots from their data, current analytical tools are too simple to admit deep understanding. To detect advanced and novel attacks, analysts turn to manual investigations. While commonplace, current investigations are time-consuming, intuition-based, and proving insufficient. Our hypothesis is that arming the analyst with easy-to-use data science tools will increase their work efficiency, provide them with the ability to resolve hypotheses with scientific inquiry of their data, and support their decisions with evidence over intuition. To this end, we present our work to build IDEAS (Interactive Data Exploration and Analysis System). We present three real-world use-cases that drive the system design from the algorithmic capabilities to the user interface. Finally, a modular and scalable software architecture is discussed along with plans for our pilot deployment with a security operation command.
* 4 page short paper on IDEAS System, 4 figures
GraphPrints: Towards a Graph Analytic Method for Network Anomaly Detection
Feb 02, 2016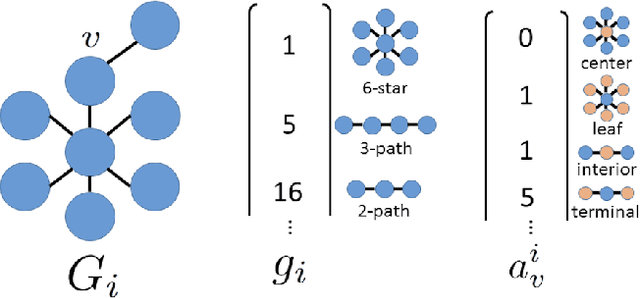


This paper introduces a novel graph-analytic approach for detecting anomalies in network flow data called GraphPrints. Building on foundational network-mining techniques, our method represents time slices of traffic as a graph, then counts graphlets -- small induced subgraphs that describe local topology. By performing outlier detection on the sequence of graphlet counts, anomalous intervals of traffic are identified, and furthermore, individual IPs experiencing abnormal behavior are singled-out. Initial testing of GraphPrints is performed on real network data with an implanted anomaly. Evaluation shows false positive rates bounded by 2.84% at the time-interval level, and 0.05% at the IP-level with 100% true positive rates at both.
Automatic Labeling for Entity Extraction in Cyber Security
Jun 09, 2014
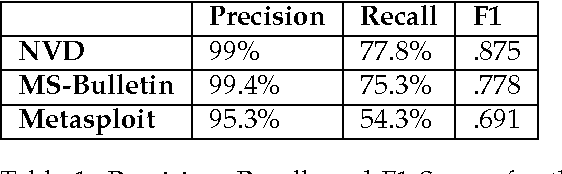

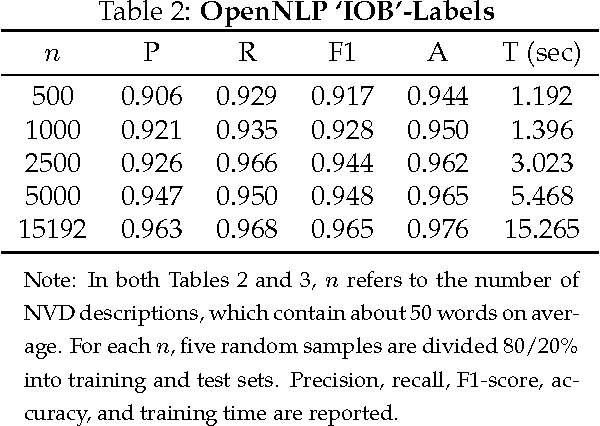
Timely analysis of cyber-security information necessitates automated information extraction from unstructured text. While state-of-the-art extraction methods produce extremely accurate results, they require ample training data, which is generally unavailable for specialized applications, such as detecting security related entities; moreover, manual annotation of corpora is very costly and often not a viable solution. In response, we develop a very precise method to automatically label text from several data sources by leveraging related, domain-specific, structured data and provide public access to a corpus annotated with cyber-security entities. Next, we implement a Maximum Entropy Model trained with the average perceptron on a portion of our corpus ($\sim$750,000 words) and achieve near perfect precision, recall, and accuracy, with training times under 17 seconds.
PACE: Pattern Accurate Computationally Efficient Bootstrapping for Timely Discovery of Cyber-Security Concepts
Oct 11, 2013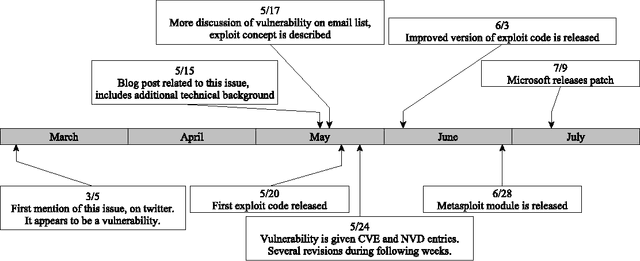
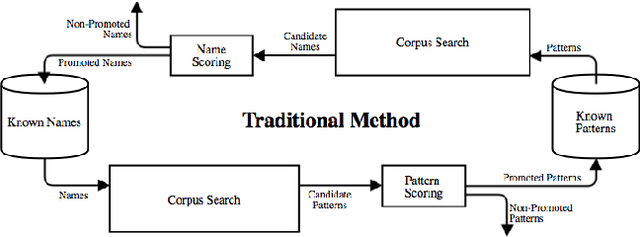
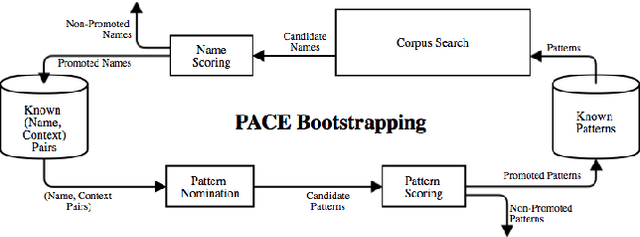

Public disclosure of important security information, such as knowledge of vulnerabilities or exploits, often occurs in blogs, tweets, mailing lists, and other online sources months before proper classification into structured databases. In order to facilitate timely discovery of such knowledge, we propose a novel semi-supervised learning algorithm, PACE, for identifying and classifying relevant entities in text sources. The main contribution of this paper is an enhancement of the traditional bootstrapping method for entity extraction by employing a time-memory trade-off that simultaneously circumvents a costly corpus search while strengthening pattern nomination, which should increase accuracy. An implementation in the cyber-security domain is discussed as well as challenges to Natural Language Processing imposed by the security domain.