 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCanonical Correlation Analysis for Analyzing Sequences of Medical Billing Codes
Jan 06, 2017
We propose using canonical correlation analysis (CCA) to generate features from sequences of medical billing codes. Applying this novel use of CCA to a database of medical billing codes for patients with diverticulitis, we first demonstrate that the CCA embeddings capture meaningful relationships among the codes. We then generate features from these embeddings and establish their usefulness in predicting future elective surgery for diverticulitis, an important marker in efforts for reducing costs in healthcare.
Towards a relation extraction framework for cyber-security concepts
Apr 16, 2015
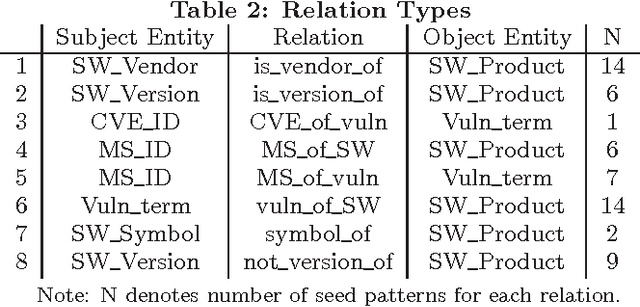
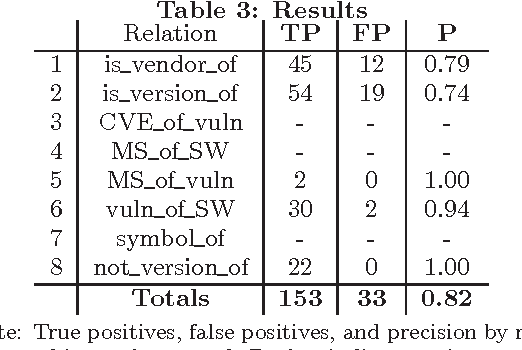
In order to assist security analysts in obtaining information pertaining to their network, such as novel vulnerabilities, exploits, or patches, information retrieval methods tailored to the security domain are needed. As labeled text data is scarce and expensive, we follow developments in semi-supervised Natural Language Processing and implement a bootstrapping algorithm for extracting security entities and their relationships from text. The algorithm requires little input data, specifically, a few relations or patterns (heuristics for identifying relations), and incorporates an active learning component which queries the user on the most important decisions to prevent drifting from the desired relations. Preliminary testing on a small corpus shows promising results, obtaining precision of .82.
Automatic Labeling for Entity Extraction in Cyber Security
Jun 09, 2014
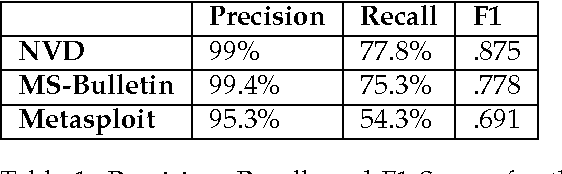

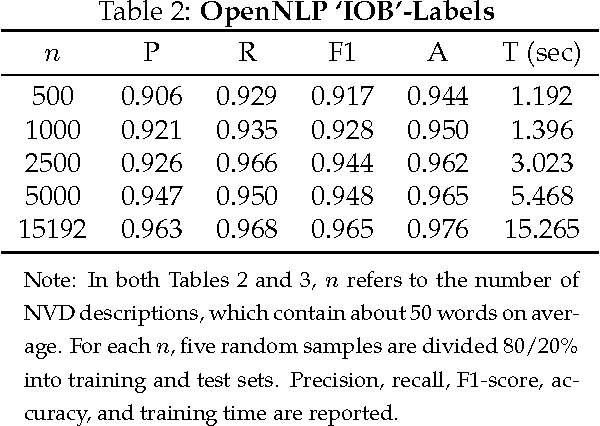
Timely analysis of cyber-security information necessitates automated information extraction from unstructured text. While state-of-the-art extraction methods produce extremely accurate results, they require ample training data, which is generally unavailable for specialized applications, such as detecting security related entities; moreover, manual annotation of corpora is very costly and often not a viable solution. In response, we develop a very precise method to automatically label text from several data sources by leveraging related, domain-specific, structured data and provide public access to a corpus annotated with cyber-security entities. Next, we implement a Maximum Entropy Model trained with the average perceptron on a portion of our corpus ($\sim$750,000 words) and achieve near perfect precision, recall, and accuracy, with training times under 17 seconds.