 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgediffGHOST: Diffusion based Generative Hedged Oblivious Synthetic Trajectories
May 11, 2026Trajectories are nowadays valuable information for a wide range of applications. However they are also inherently sensitive, as they contain highly personal information about individuals. Facing this challenge, synthesizing mobility trajectories has emerged as a promising solution to leverage mobility information while preserving privacy. State-of-the-art models, often rely on the false assumptions of generative models implicit privacy and fails to provide privacy guarantees while preserving trajectories utility. Here, we introduce diffGHOST, a conditional diffusion model based on latent space segmentation, designed to answer this challenge. Thus, this paper propose a methodology that identify and mitigate memorization of critical samples using condition segments of a learn latent space.
A Dual Perspective on Synthetic Trajectory Generators: Utility Framework and Privacy Vulnerabilities
Apr 21, 2026Human mobility data are used in numerous applications, ranging from public health to urban planning. Human mobility is inherently sensitive, as it can contain information such as religious beliefs and political affiliations. Historically, it has been proposed to modify the information using techniques such as aggregation, obfuscation, or noise addition, to adequately protect privacy and eliminate concerns. As these methods come at a great cost in utility, new methods leveraging development in generative models, were introduced. The extent to which such methods answer the privacy-utility trade-off remains an open problem. In this paper, we introduced a first step towards solving it, by the introduction and application of a new framework for utility evaluation. Furthermore, we provide evidence that privacy evaluation remains a great challenge to consider and that it should be tackled through adversarial evaluation in accordance with the current EU regulation. We propose a new membership inference attack against a subcategory of generative models, even though this subcategory was deemed private due to its resistance over the trajectory user-linking problem.
A Zero Auxiliary Knowledge Membership Inference Attack on Aggregate Location Data
Jun 26, 2024
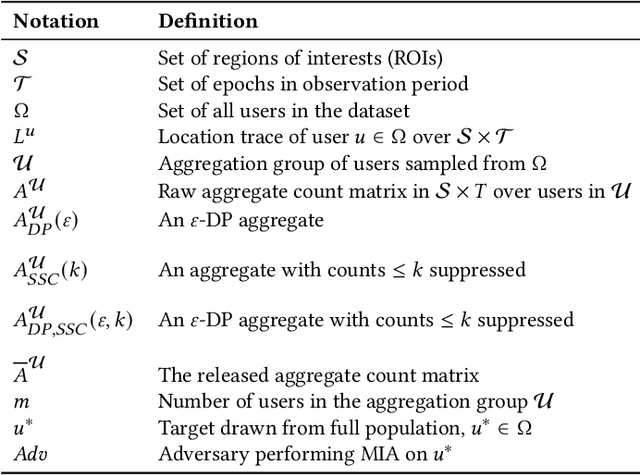

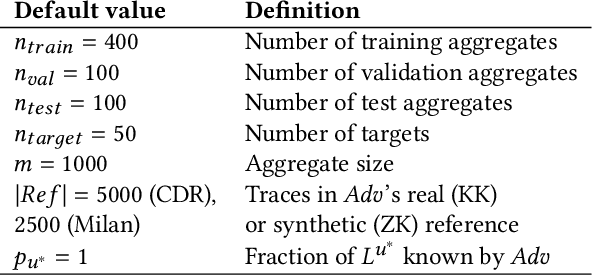
Location data is frequently collected from populations and shared in aggregate form to guide policy and decision making. However, the prevalence of aggregated data also raises the privacy concern of membership inference attacks (MIAs). MIAs infer whether an individual's data contributed to the aggregate release. Although effective MIAs have been developed for aggregate location data, these require access to an extensive auxiliary dataset of individual traces over the same locations, which are collected from a similar population. This assumption is often impractical given common privacy practices surrounding location data. To measure the risk of an MIA performed by a realistic adversary, we develop the first Zero Auxiliary Knowledge (ZK) MIA on aggregate location data, which eliminates the need for an auxiliary dataset of real individual traces. Instead, we develop a novel synthetic approach, such that suitable synthetic traces are generated from the released aggregate. We also develop methods to correct for bias and noise, to show that our synthetic-based attack is still applicable when privacy mechanisms are applied prior to release. Using two large-scale location datasets, we demonstrate that our ZK MIA matches the state-of-the-art Knock-Knock (KK) MIA across a wide range of settings, including popular implementations of differential privacy (DP) and suppression of small counts. Furthermore, we show that ZK MIA remains highly effective even when the adversary only knows a small fraction (10%) of their target's location history. This demonstrates that effective MIAs can be performed by realistic adversaries, highlighting the need for strong DP protection.
Lost in the Averages: A New Specific Setup to Evaluate Membership Inference Attacks Against Machine Learning Models
May 24, 2024


Membership Inference Attacks (MIAs) are widely used to evaluate the propensity of a machine learning (ML) model to memorize an individual record and the privacy risk releasing the model poses. MIAs are commonly evaluated similarly to ML models: the MIA is performed on a test set of models trained on datasets unseen during training, which are sampled from a larger pool, $D_{eval}$. The MIA is evaluated across all datasets in this test set, and is thus evaluated across the distribution of samples from $D_{eval}$. While this was a natural extension of ML evaluation to MIAs, recent work has shown that a record's risk heavily depends on its specific dataset. For example, outliers are particularly vulnerable, yet an outlier in one dataset may not be one in another. The sources of randomness currently used to evaluate MIAs may thus lead to inaccurate individual privacy risk estimates. We propose a new, specific evaluation setup for MIAs against ML models, using weight initialization as the sole source of randomness. This allows us to accurately evaluate the risk associated with the release of a model trained on a specific dataset. Using SOTA MIAs, we empirically show that the risk estimates given by the current setup lead to many records being misclassified as low risk. We derive theoretical results which, combined with empirical evidence, suggest that the risk calculated in the current setup is an average of the risks specific to each sampled dataset, validating our use of weight initialization as the only source of randomness. Finally, we consider an MIA with a stronger adversary leveraging information about the target dataset to infer membership. Taken together, our results show that current MIA evaluation is averaging the risk across datasets leading to inaccurate risk estimates, and the risk posed by attacks leveraging information about the target dataset to be potentially underestimated.
Synthetic is all you need: removing the auxiliary data assumption for membership inference attacks against synthetic data
Jul 04, 2023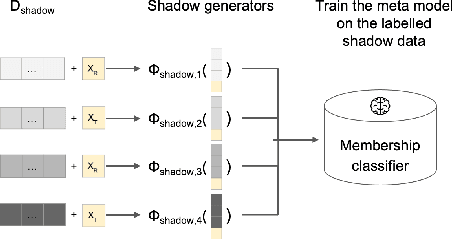
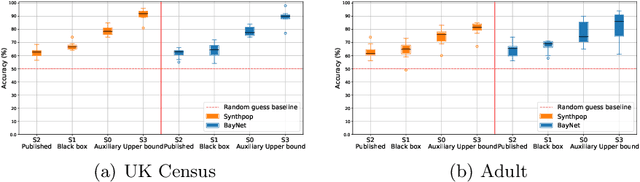
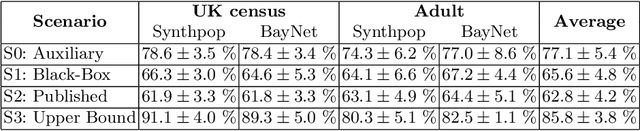
Synthetic data is emerging as the most promising solution to share individual-level data while safeguarding privacy. Membership inference attacks (MIAs), based on shadow modeling, have become the standard to evaluate the privacy of synthetic data. These attacks, however, currently assume the attacker to have access to an auxiliary dataset sampled from a similar distribution as the training dataset. This often is a very strong assumption that would make an attack unlikely to happen in practice. We here show how this assumption can be removed and how MIAs can be performed using only the synthetic data. More specifically, in three different attack scenarios using only synthetic data, our results demonstrate that MIAs are still successful, across two real-world datasets and two synthetic data generators. These results show how the strong hypothesis made when auditing synthetic data releases - access to an auxiliary dataset - can be relaxed to perform an actual attack.
Dataset correlation inference attacks against machine learning models
Dec 16, 2021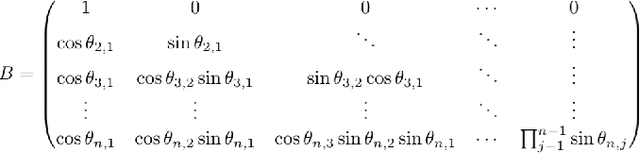
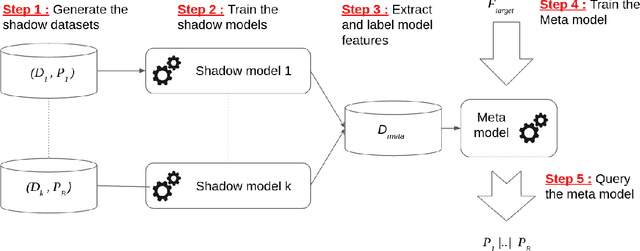
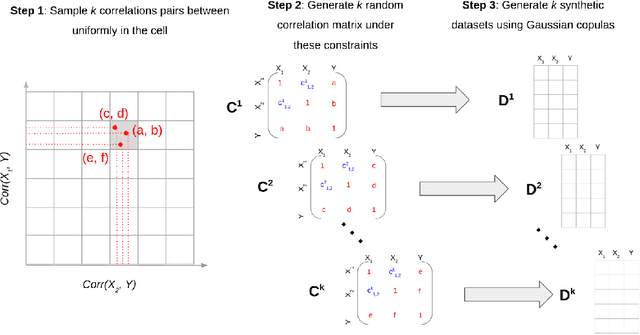
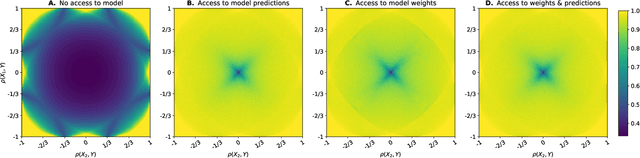
Machine learning models are increasingly used by businesses and organizations around the world to automate tasks and decision-making. Trained on potentially sensitive datasets, machine learning models have been shown to leak information about individuals in the dataset as well as global dataset information. We here take research in dataset property inference attacks one step further by proposing a new attack against ML models: a dataset correlation inference attack, where an attacker's goal is to infer the correlation between input variables of a model. We first show that an attacker can exploit the spherical parametrization of correlation matrices, to make an informed guess. This means that using only the correlation between the input variables and the target variable, an attacker can infer the correlation between two input variables much better than a random guess baseline. We propose a second attack which exploits the access to a machine learning model using shadow modeling to refine the guess. Our attack uses Gaussian copula-based generative modeling to generate synthetic datasets with a wide variety of correlations in order to train a meta-model for the correlation inference task. We evaluate our attack against Logistic Regression and Multi-layer perceptron models and show it to outperform the model-less attack. Our results show that the accuracy of the second, machine learning-based attack decreases with the number of variables and converges towards the accuracy of the model-less attack. However, correlations between input variables which are highly correlated with the target variable are more vulnerable regardless of the number of variables. Our work bridges the gap between what can be considered a global leakage about the training dataset and individual-level leakages. When coupled with marginal leakage attacks,it might also constitute a first step towards dataset reconstruction.