 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAT-Bench: A Comprehensive Benchmark for Text Anonymization
Feb 13, 2026Data containing personal information is increasingly used to train, fine-tune, or query Large Language Models (LLMs). Text is typically scrubbed of identifying information prior to use, often with tools such as Microsoft's Presidio or Anthropic's PII purifier. These tools have traditionally been evaluated on their ability to remove specific identifiers (e.g., names), yet their effectiveness at preventing re-identification remains unclear. We introduce RAT-Bench, a comprehensive benchmark for text anonymization tools based on re-identification risk. Using U.S. demographic statistics, we generate synthetic text containing various direct and indirect identifiers across domains, languages, and difficulty levels. We evaluate a range of NER- and LLM-based text anonymization tools and, based on the attributes an LLM-based attacker is able to correctly infer from the anonymized text, we report the risk of re-identification in the U.S. population, while properly accounting for the disparate impact of identifiers. We find that, while capabilities vary widely, even the best tools are far from perfect in particular when direct identifiers are not written in standard ways and when indirect identifiers enable re-identification. Overall we find LLM-based anonymizers, including new iterative anonymizers, to provide a better privacy-utility trade-off albeit at a higher computational cost. Importantly, we also find them to work well across languages. We conclude with recommendations for future anonymization tools and will release the benchmark and encourage community efforts to expand it, in particular to other geographies.
The DCR Delusion: Measuring the Privacy Risk of Synthetic Data
May 02, 2025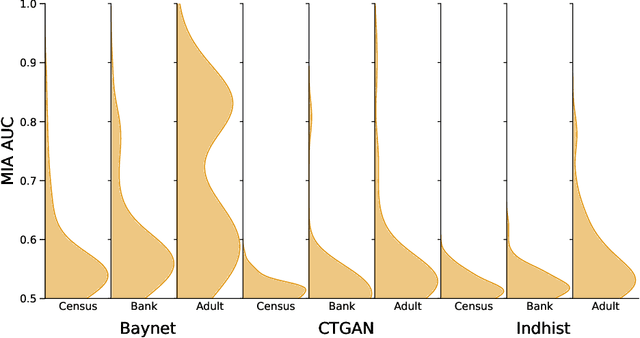

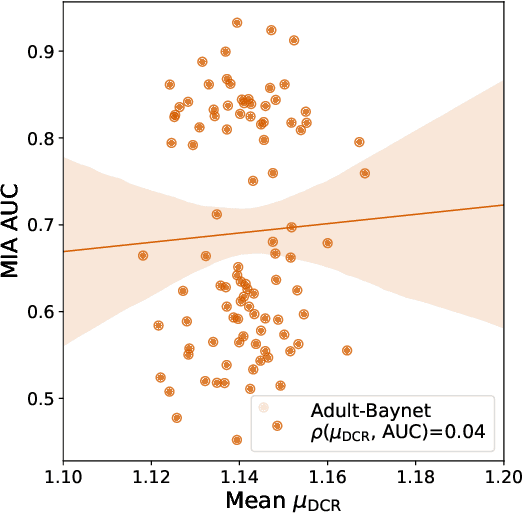
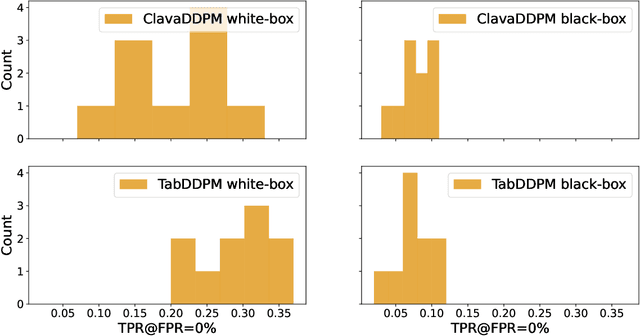
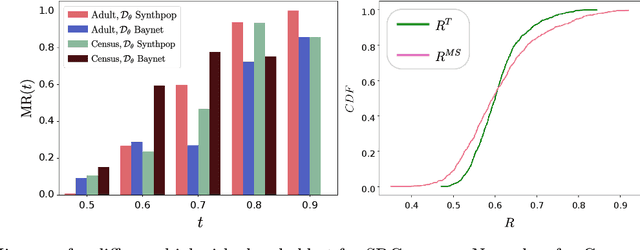
Synthetic data has become an increasingly popular way to share data without revealing sensitive information. Though Membership Inference Attacks (MIAs) are widely considered the gold standard for empirically assessing the privacy of a synthetic dataset, practitioners and researchers often rely on simpler proxy metrics such as Distance to Closest Record (DCR). These metrics estimate privacy by measuring the similarity between the training data and generated synthetic data. This similarity is also compared against that between the training data and a disjoint holdout set of real records to construct a binary privacy test. If the synthetic data is not more similar to the training data than the holdout set is, it passes the test and is considered private. In this work we show that, while computationally inexpensive, DCR and other distance-based metrics fail to identify privacy leakage. Across multiple datasets and both classical models such as Baynet and CTGAN and more recent diffusion models, we show that datasets deemed private by proxy metrics are highly vulnerable to MIAs. We similarly find both the binary privacy test and the continuous measure based on these metrics to be uninformative of actual membership inference risk. We further show that these failures are consistent across different metric hyperparameter settings and record selection methods. Finally, we argue DCR and other distance-based metrics to be flawed by design and show a example of a simple leakage they miss in practice. With this work, we hope to motivate practitioners to move away from proxy metrics to MIAs as the rigorous, comprehensive standard of evaluating privacy of synthetic data, in particular to make claims of datasets being legally anonymous.
Lost in the Averages: A New Specific Setup to Evaluate Membership Inference Attacks Against Machine Learning Models
May 24, 2024


Membership Inference Attacks (MIAs) are widely used to evaluate the propensity of a machine learning (ML) model to memorize an individual record and the privacy risk releasing the model poses. MIAs are commonly evaluated similarly to ML models: the MIA is performed on a test set of models trained on datasets unseen during training, which are sampled from a larger pool, $D_{eval}$. The MIA is evaluated across all datasets in this test set, and is thus evaluated across the distribution of samples from $D_{eval}$. While this was a natural extension of ML evaluation to MIAs, recent work has shown that a record's risk heavily depends on its specific dataset. For example, outliers are particularly vulnerable, yet an outlier in one dataset may not be one in another. The sources of randomness currently used to evaluate MIAs may thus lead to inaccurate individual privacy risk estimates. We propose a new, specific evaluation setup for MIAs against ML models, using weight initialization as the sole source of randomness. This allows us to accurately evaluate the risk associated with the release of a model trained on a specific dataset. Using SOTA MIAs, we empirically show that the risk estimates given by the current setup lead to many records being misclassified as low risk. We derive theoretical results which, combined with empirical evidence, suggest that the risk calculated in the current setup is an average of the risks specific to each sampled dataset, validating our use of weight initialization as the only source of randomness. Finally, we consider an MIA with a stronger adversary leveraging information about the target dataset to infer membership. Taken together, our results show that current MIA evaluation is averaging the risk across datasets leading to inaccurate risk estimates, and the risk posed by attacks leveraging information about the target dataset to be potentially underestimated.